

如果你对数据科学、Web 开发、机器人或物联网感兴趣,那你一定要学 Python。由于 Python 被大量使用和广泛应用,它已经成为了增长最快的编程语言。
对于一个初学者或没有技术背景的人来说,学习 Python 是一个不错的选择。它的语法就像使用通俗英语说话和写作一样。以这个语法为例,它展示了和英语的相似性:
print("Hello folks")
我们将在这篇教程中采用被广泛使用的 Python3,大多数 Python 的框架和库都支持这个版本。
注意: 任何高于 3.5.2 的版本都支持绝大多数库和框架。
索引:
- 绪论
- 安装
- Python shell
- 注释
- 打印
- 缩进
- 变量
- 运算符
- 条件语句
- For 循环
- While 循环
- 用户输入
- 类型转换
- 字典
- 列表
- 元组
- 集合
- 函数与参数
- Args
- 关键字参数
- 默认参数
- kwargs
- 作用域
- Return 语句
- Lambda 表达式
- 列表推导式
- 面向对象编程
- 类
- 方法
- 对象
- 构造器
- 实例属性
- 类属性
- Self
- 继承
- Super
- 多重继承
- 多态
- 封装
- 装饰器
- 异常
- 包的导入
- JSON 处理
注意: 这篇指南的开头部分是为初学者准备的。如果你拥有中级 Python 经验,随时可以使用上面的链接向前跳转。
绪论:
根据 Github 2019 年度的 octoverse 报告,在开发者使用最多的语言中,Python 排名第二。
在学习任何一门编程语言之前,了解该语言的由来是很有用的。Python 由荷兰程序员 Guido van Rossum 开发,于 1991 年发布。
Python 是一门解释型语言,它使用 CPython 解释器将 Python 代码编译成字节码。对于初学者来说,你不需要对 CPython 有过多了解,但你必须知道 Python 内部是如何工作的。
Python 背后的哲学就是代码必须可读,这是通过缩进实现的。Python 还支持很多编程范式,比如函数式编程和面向对象编程。你将在阅读本文的过程中对它们有一个更好的理解。
大多数初学者脑中的基本问题就是一门编程语言能够做什么。这里是 Pyhton 的一些使用场景:
- 服务端开发(Django,Flask)
- 数据科学(Pytorch,Tensor-flow)
- 数据分析/可视化(Matplotlib)
- 脚本(Beautiful Soup)
- 嵌入式开发
注意: 我并不是特别为上面提到的任何库或框架背书,它们在各自的领域中都非常流行,也得到了广泛使用。
安装:
学习任何编程语言的第一步都是安装它。如今,大多数操作系统都自带 Python。你可以在终端执行以下命令,检查 Python 是否可用:
python3 --version
输出如下:
Python 3.7.0
注意:你的 Python 版本可能会有所不同。如果你已经安装过 Python 并且版本号在 3.5.2 以上,可以跳过这一部分。
对于电脑上没有 Python 的人来说,下面是安装步骤:
Windows 用户:
- 打开 Python 官网。
- 点击下载按钮(下载 Python 3.8.2)[注意: 在你阅读本文时,版本可能会有所不同]。
- 前往下载目录,双击安装程序。
- 勾选“Add Python 3.x to PATH”,并单击“Install Now”。
- 安装完成后,你会收到一个“Setup was successful”的提示。再次使用上面的命令检查 python 是否配置正确。
- 使用命令
python3 --version确认 Python 是否安装成功以及配置正确。
Mac 用户
- 首先从应用商店安装 xcode。
- 如果你想从终端安装 Xcode,可以使用以下命令:
xcode-select --install
- 之后,我们将使用 brew 包管理器安装 Python。安装和配置 brew 的命令如下:
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install.sh)"
- 当 brew 设置完成,就使用下面这条命令更新所有过时的包:
brew update
- 使用以下命令安装 Python:
brew install python3
- 使用命令
python3 --version确认 Python 是否安装成功以及配置正确。
Linux 用户
- 使用
apt安装 Python 的命令如下:
sudo apt install python3
- 使用
yum安装 Python 的命令如下:
sudo yum install python3
- 使用命令
python3 --version确认 Python 是否安装成功以及配置正确。
Python shell:
Shell 将会是你遇到的最有用的工具之一。 Python shell 允许我们在将任何想法集成到应用之前进行快速测试。
打开终端或者命令行提示符,输入 python3 命令,你会得到以下输出:
➜ python3.7
Python 3.7.0 (v3.7.0:1bf9cc5093, Jun 26 2018, 23:26:24)
[Clang 6.0 (clang-600.0.57)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>>
在本教程中,我们将利用你刚看到的 python3 shell 学习一些概念。从现在开始,只要我提到“打开 Python shell”,就表示你需要使用 python3 命令。
我们会创建一个以 .py 为扩展的文件 “testing”,用于学习剩下的概念。我们将使用以下命令运行这个文件:
python3 testing.py
打开 Python shell,在 >>> 标记后输入 10 + 12,你会得到 22:
>>> 10 + 12
22
注释:
注释(comment)帮助我们(和其他人)理解为什么要写某段代码,让代码的编写更加容易。注释的另一大作用就是帮助我们提高代码的可读性。
# Stay Safe
当你像上面这么写时,Python 解释器就会知道它是一个注释。# 之后的任何东西都不会被执行。
你可能想知道为什么应该使用注释。假设你是一名开发者,被指派了一个庞大的项目,这个项目有超过一千行代码。为了理解一切都是怎么工作的,你需要逐行阅读所有的代码。
有比这更好的解决办法吗?哈哈,有,就是注释。注释帮助我们理解为什么要写某段代码,它返回啥或者它干了啥。注释看作是这段代码的文档。
打印:
除了编辑器的调试工具,最常帮助开发者解决问题的东西就是 print 语句了。print 语句是所有编程中最容易被低估的语法之一。
那么它是如何帮助我们调试问题的呢?假设你有一个模块,你想通过检查这个模块的执行过程理解或调试它。你有两个选择:要么使用调试工具,要么使用 print 语句。
并不是任何时候都可以使用调试工具。例如,如果你正在使用 Python shell,就没有调试工具可以用了。在这种情况下,print 语句可以帮我们。另一种情况就是你的应用正在运行,你可以添加一条显示日志的 print 语句,在运行时监视它们。
Python 提供了一个内置的 print 方法,语法如下:
print("Stay safe...")
缩进:
Python 中另一个有趣的部分就是缩进(indentation)。为什么呢?答案很简单:缩进让代码易读、结构良好。Python 强制使用者遵守缩进规则,如果缩进不合适,你就会得到下面这个错误:
IndentationError: unexpected indent
看到了吧,即使是 Python 中的错误也这么易读和理解。你可能会在刚开始的时候因强制缩进而感到心烦,但是你会慢慢发现缩进是开发者的好朋友。
变量:
顾名思义,变量(variable)就是能够变化的东西。在计算机程序中,变量则是引用内存位置的一种方式。
在大多数编程语言中,你需要指定变量的类型。但是在 Python 中,你不需要这么做。例如,要声明一个整型变量,C 语言中需要写 int num = 5,而 Python 中只需要写 num = 5。
打开 Python shell,然后一步一步执行:
Integer:可正可负,也可为零的数值,不含小数点。
>>> num = 5
>>> print(num)
5
>>> type(num)
<class 'int'>
如你所见,我们声明了一个 num 变量并赋值为 5。Python 内置的 type 方法可以被用来检查变量的类型。检查 num 的类型,我们得到的结果为 <class 'int'>。现在,只关注结果中的 int,它表示一个整数。
Float:和整数类似,但又有点细微的差别——浮点数是含有小数点的数值。
>>> num = 5.0
>>> print(num)
5.0
>>> type(num)
<class 'float'>
我们将带有一位小数的数值赋值给了 num。检查 num 的类型,我们得到的结果是 float。
String:由字符或整数构成,可以使用双引号或单引号表示。
>>> greet = "Hello user"
>>> print(greet)
Hello user
>>> type(greet)
<class 'str'>
我们在这里将一个字符串赋值给了 greet。从输出中你可以看到,它的类型为字符串。
Boolean:一个二元操作符,值为 True 或 False。
>>> is_available = True
>>> print(is_available)
True
>>> type(is_available)
<class 'bool'>
我们将 is_available 赋值为 True,它的类型为布尔。你只可以给布尔变量赋值为 True 或 False。记住,T 和 F 应该是大写,否则你会收到一个错误,如下:
>>> is_available = true
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'true' is not defined
NoneType:在变量没有值的时候使用。
>>> num = None
>>> print(num)
None
>>> type(num)
<class 'NoneType'>
运算符:
下图展示了 Python 中所有的运算符:
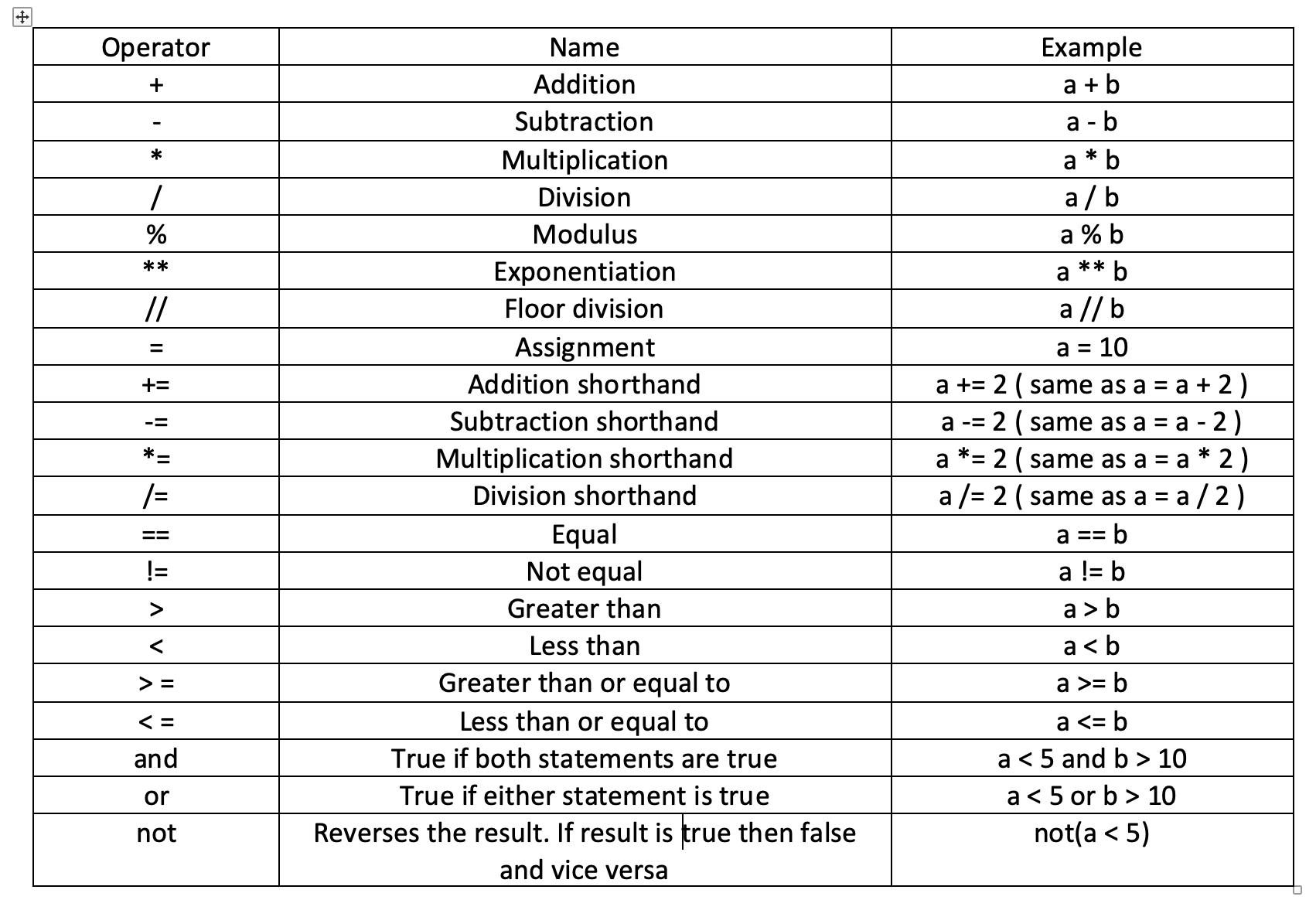
我们一个一个地看。
算术运算符
算术运算符包括加、减、乘、求幂、取模和向下取整除,一些运算符还有简写语法。
先声明两个变量,a 和 b。
>>> a = 6 # 赋值
>>> b = 2
尝试下基本算术运算符:
>>> a + b # 加
8
>>> a - b # 减
4
>>> a * b # 乘
12
>>> a / b # 除
3.0
>>> a ** b # 求幂
36
为了测试其它的算术运算符,我们要改变一下 a 和 b 的值。
>>> a = 7
>>> b = 3
>>> a % b # 取模
1
>>> a // b # 向下取整除
2
Python 中也支持使用简写的算术运算符,你可以参照上面的图片进行测试,使用 print 语句打印出简写运算的结果。
比较运算符
比较运算符包括等于、大于和小于。
>>> a = 5 # 赋值
>>> b = 2 # 赋值
>>> a > b # 大于
True
>>> a < b # 小于
False
>>> a == b # 等于
False
>>> a >= 5 # 大于等于
True
>>> b <= 1 # 小于等于
False
逻辑运算符
逻辑运算符包括非(not)、与(and)、或(or)。
>>> a = 10
>>> b = 2
>>> a == 2 and b == 10 # 与
False
>>> a == 10 or b == 10 # 或
True
>>> not(a == 10) # 非
False
>>> not(a == 2)
True
条件语句:
顾名思义,条件语句用于计算条件的真假。
很多时候,你需要在开发过程中根据特定的条件做不同的事情。在这种情况下,条件语句就非常有用了。Python 中的条件语句包括 if、elif 和 else。
我们可以比较变量,检查变量是否为一些值。如果变量为布尔类型的话,就检查它是真还是假。打开 Python shell,逐步执行:
条件 1: 我们有一个整数和三个条件。第一个是 if 条件,它检查数字是否等于 10。
第二个是 elif 条件,它检查数字是否小于 10。
最后一个条件是 else,它在以上两个条件匹配失败时执行。
>>> number = 5
>>> if number == 10:
... print("Number is 10")
... elif number < 10:
... print("Number is less than 10")
... else:
... print("Number is more than 10")
...
输出:
Number is less than 10
注意: 并不是只能在 if 条件中检查两个条件是否相等,你也可以使用 elif。
Condition Number 2: We have a boolean and 2 conditions here. Have you noticed how we are checking if the condition is true? If is_available, then print "Yes it is available", else print "Not available".
条件 2: 我们有一个布尔值和两个条件。你有注意到我们是如何检查条件为真吗?如果 is_available,就打印“Yes it is available”,否则打印“Not available”。
>>> is_available = True
>>> if is_available:
... print("Yes it is available")
... else:
... print("Not available")
...
Output:
输出:
Yes it is available
条件 3: 使用取反运算符反转条件 2。
>>> is_available = True
>>> if not is_available:
... print("Not available")
... else:
... print("Yes it is available")
...
输出:
Yes it is available
条件 4: 将 data 声明为 None,然后检查 data 是否可用。
>>> data = None
>>> if data:
... print("data is not none")
... else:
... print("data is none")
...
输出:
data is none
条件 5: 使用行内 if,语法如下:
>>> num_a = 10
>>> num_b = 5
>>> if num_a > num_b: print("num_a is greater than num_b")
...
输出:
num_a is greater than num_b
条件 6: 使用行内 if else,语法如下:
expression_if_true if condition else expression_if_false
示例:
>>> num = 5
>>> print("Number is five") if num == 5 else print("Number is not five")
输出:
Number is five
条件 7: 使用嵌套的 if-else 语句,语法如下:
>>> num = 25
>>> if num > 10:
... print("Number is greater than 10")
... if num > 20:
... print("Number is greater than 20")
... if num > 30:
... print("Number is greater than 30")
... else:
... print("Number is smaller than 10")
...
输出:
Number is greater than 10
Number is greater than 20
条件 8: 在条件语句中使用 and 运算符,它只有在两个条件同时满足时才会执行。
>>> num = 10
>>> if num > 5 and num < 15:
... print(num)
... else:
... print("Number may be small than 5 or larger than 15")
...
输出:
10
由于我们的数字在 5 到 15 之间,所以我们得到的结果是 10。
条件 9: 使用 or 运算符,它在任一条件为真时执行。
>>> num = 10
>>> if num > 5 or num < 7:
... print(num)
...
输出:
10
因为 num 的值为 10,并且我们的第二个条件要求 num 小于 7,你是不是很困惑?为什么输出是 10 呢?因为 or 只要匹配上任意一个条件,就会执行。
For 循环:
另一个在所有编程语言中都非常有用的方法就是迭代器(iterator)。如果你不得不多次实现某个东西,你会怎么做?
print("Hello")
print("Hello")
print("Hello")
这是一种方式。但是,如果必须做一百或一千次,你就要非写大量的 print 语句不可。有一种更好的处理方式——使用迭代器或循环。我们可以使用 for 循环,也可以使用 while 循环。
这里使用了 range 方法,它给出了一个区间,循环应该在这个区间内重复执行。默认情况下,range 的开始点为 0。
>>> for i in range(3):
... print("Hello")
...
输出:
Hello
Hello
Hello
你也可以使用 range(1,3) 这种方式声明区间。
>>> for i in range(1,3):
... print("Hello")
...
输出:
Hello
Hello
因为我们声明了区间,所以“Hello”只打印了两次。你可以把区间看成 Number on right - Number on left。
你还可以将 else 语句添加到 for 循环。
>>> for i in range(3):
... print("Hello")
... else:
... print("Finished")
输出:
Hello
Hello
Hello
Finished
循环先迭代了 3 次(3 - 0),else 语句在迭代完成后立即执行。
我们也可以将一个 for 循环嵌入到另一个 for 循环之中。
>>> for i in range(3):
... for j in range(2):
... print("Inner loop")
... print("Outer loop")
...
输出:
Inner loop
Inner loop
Outer loop
Inner loop
Inner loop
Outer loop
Inner loop
Inner loop
Outer loop
如你所见,内层循环的打印语句执行了两次,之后外层循环的打印语句执行了一次,然后又是两次内层循环。所以这里在发生什么呢?如果你感到困惑,这么想一想:
- 解释器一上来就看见了一个
for循环,它再次向下,发现还有另一个for循环。 - 现在它会执行两次内层的
for循环,然后退出。内层循环执行完之后,编译器就会得知外层循环要求它再重复执行两次。 - 解释器再次执行,遇到内层循环,然后重复这个过程。
你还可以选择通过某个 for 循环条件,通过在这里是什么意思呢?不论 for 循环在何时发生,只要解释器看到了 pass 语句,它什么都不会做,直接跳到下一行。
>>> for i in range(3):
... pass
...
你不会在 shell 中得到任何输出。
While 循环:
Python 中还有一种循环或迭代器,它就是 while 循环。我们可以使用 while 循环得到与 for 循环一样的结果。
>>> i = 0
>>> while i < 5:
... print("Number", i)
... i += 1
...
输出:
Number 0
Number 1
Number 2
Number 3
Number 4
不论你何时使用 while 循环,都要记得添加一个递增语句,或者一个在某种情况下能够结束 while 循环的语句。否则,循环会一直执行下去。
另一种方式就是在 while 循环中加入一个 break 语句,它会打破循环。
>>> i = 0
>>> while i < 5:
... if i == 4:
... break
... print("Number", i)
... i += 1
...
输出:
Number 0
Number 1
Number 2
Number 3
在这里,如果发现 i 的值为 4,我们就打破 while 循环。
另一种方式是在 while 循环中加入一个 else 语句,它会在 while 循环完成后执行。
>>> i = 0
>>> while i < 5:
... print("Number", i)
... i += 1
... else:
... print("Number is greater than 4")
...
输出:
Number 0
Number 1
Number 2
Number 3
Number 4
Number is greater than 4
continue 语句可以用来跳出当前循环,直接进到下次循环。
>>> i = 0
>>> while i < 6:
... i += 1
... if i == 2:
... continue
... print("number", i)
...
输出:
number 1
number 3
number 4
number 5
number 6
用户输入:
假设你正在构建一个命令行应用,现在你需要根据用户的输入执行不同的操作。为了达到这个目的,你可以使用 Python 内置的 input 方法。
实现的语法很简单,如下所示:
variable = input(".....")
示例:
>>> name = input("Enter your name: ")
Enter your name: Sharvin
当你使用 input 方法时,你会在按下回车键之后收到一个提示,提示的内容就是你输入到 input 方法的文本。我们来检查一下赋值有没有成功:
>>> print(name)
Sharvin
就是这个!它运行得很好,Sharvin 就是输入的字符串。
>>> type(name)
<class 'str'>
我们用另一个例子试一下。这一次我们会把它赋值给一个整数,而不是字符串,然后会检查它的类型。
>>> date = input("Today's date: ")
Today's date: 12
>>> type(date)
<class 'str'>
又困惑了吗?我们输入了一个整数 12,但它还是告诉我们类型为字符串。这并不是一个 bug,它正是输入的工作机制。要将字符串转成整数,我们需要使用类型转换。
类型转换:
我们看到 input 方法为整数返回了字符串。如果我们现在想把这个输出和另一个整数进行比较,就需要一种将其转换回整数的方式。
>>> date_to_int = int(date)
>>> type(date_to_int)
<class 'int'>
这里我们使用了用户输入一节声明的 date,使用 Python 内置的 int 方法将它转换成一个整数。这就是类型转换(typecasting)。
你基本上可以进行下列转换:
- 整数到字符串:
str() - 字符串到整数:
int() - 整数到浮点数:
float()
注意:浮点数到整数的转换也是可能的。
>>> type(date)
<class 'str'>
# 从字符串转换到浮点数
>>> date_to_float = float(date)
>>> type(date_to_float)
<class 'float'>
# 从浮点数转换到字符串
>>> date_to_string = str(date_to_float)
>>> type(date_to_string)
<class 'str'>
字典
假如你想保存一些用户的详细资料,你会怎么保存它们呢?没错,我们可以用变量保存它们,像下面这样:
>>> fname = "Sharvin"
>>> lname = "Shah"
>>> profession = "Developer"
要访问变量的值,可以这么做:
>>> print(fname)
Sharvin
但是这是访问用户资料最优雅的方式吗?并不是。让我们把数据存到键值对形式的字典(dictionary)中吧,它会让用户资料的访问变得更加友好。
那么什么是字典呢?字典是一种无序、可变(即它可以被更新)的集合。
字典的格式如下:
data = {
"key" : "value"
}
让我们通过一个示例进一步理解字典吧:
>>> user_details = {
... "fname": "Sharvin",
... "lname": "Shah",
... "profession": "Developer"
... }
如果访问字典中的值
有两种访问字典中的值的方式,我们将逐一查看并调试它们,从而找出哪种方式更好。
方法一:使用以下语法访问 user_details 字典中键为 fname 的值:
>>> user_details["fname"]
'Sharvin'
方法二:使用 get 访问 user_details 字典中键为 fname 的值:
>>> user_details.get("fname")
'Sharvin'
我知道方法一看起来更容易理解。当我们尝试访问一个字典中不存在的数据的时,它的问题体现出来了。
>>> user_details["age"]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'age'
我们得到了一个 KeyError,表示那个键不可用。我们使用方法二试一下这种情况。
>>> user_details.get("age")
控制台空空如也。让我们进一步调试,搞清楚为何会这样。将 get 操作赋值给一个 age 变量,然后将其打印在控制台。
>>> age = user_details.get("age")
>>> print(age)
None
所以,get 方法会在找不到键时把值设置为 None。正因为如此,我们才不会得到任何错误。现在你或许知道该使用哪个了吧。大多数情况下,方法二更合适,但是对于需要严格检查的条件,还是应该使用方法一。
如何检查一个键是否存在
你或许想知道如何检查字典中是否有某个键。Python 为此提供了一个内置的方法 keys()。
>>> if "age" in user_details.keys():
... print("Yes it is present")
... else:
... print("Not present")
...
输出如下:
Not present
如果我们想检查字典是否为空呢?为了便于理解,先声明一个空的字典:
>>> user_details = {}
我们直接在字典上使用 if-else,它要么在数据存在时返回 True,要么就在字典为空时返回 False。
>>> if user_details:
... print("Not empty")
... else:
... print("Empty")
...
输出:
Empty
我们也可以使用 Python 内置的 bool 方法检查字典是否为空。记住:如果字典为空,bool 会返回 False,否则会返回 True。
>>> bool(user_details)
False
如果更新已有键的值
现在我们知道了如何获取某个特定的键以及如何检查键是否存在,但是你怎么在字典中更新某个键呢?
声明一个字典,如下:
>>> user_details = {
... "fname":"Sharvin",
... "lname": "Shah",
... "profession": "Developer"
... }
使用以下语法更新对应的值:
>>> user_details["profession"] = "Software Developer"
>>> print(user_details)
{'fname': 'Sharvin', 'lname': 'Shah', 'profession': 'Software Developer'}
在字典中,更新键的值的方式与给变量赋值的方式一摸一样。
如何添加键-值对
下一个问题是如何添加一个新的值到字典中?让我们添加一个 age 键吧,值为 100。
>>> user_details["age"] = "100"
>>> print(user_details)
{'fname': 'Sharvin', 'lname': 'Shah', 'profession': 'Software Developer', 'age': '100'}
如你所见,一个新的键-值对已经被添加到字典中。
如何移除键-值对
要将一个键-值对从字典中移除,你可以使用 Python 内置的 pop方法。
>>> user_details.pop("age")
'100'
这将 age 键-值对从 user_details 字典中移除,我们也可以使用 del 运算符删除这个值。
>>> del user_details["age"]
del 方法也可以用来 删除整个字典,语法为 del user_details。
如何复制字典
字典是不能使用传统方式复制的。例如,你不能像下面这样将 dictA 的值复制到 dictB:
dictA = dictB
你需要使用 copy 方法完成值的复制。
>>> dictB = user_details.copy()
列表:
假如你有一堆没有标签的数据,换句话说,每条数据都没有定义它的键。你会怎么保存它呢?这个时候就该列表出场了,数据的定义如下:
data = [ 1, 5, "xyz", True ]
列表(list)是一种随机、有序和可变的集合。
如何访问列表元素
让我们试着访问列表中的第一个元素:
>>> data[1]
5
等一下,这里发生了什么?我们尝试访问第一个元素,但是却得到了第二个元素。为什么?
列表的索引从零开始。我这么说的意思是什么呢?元素位置的索引从零开始。访问列表元素的语法如下:
list[position_in_list]
要访问第一个元素,我们需要这么做:
>>> data[0]
1
>>> data[2:4]
['xyz', True]
第一个值表示开始位置,而最后一个值表示我们想要访问值的前一个位置。
如何向列表添加数据项
要将一个数据项添加到列表中,我们需要使用 Python 提供的 append 方法。
>>> data.append("Hello")
如何改变数据项的值
改变数据项的值的语法如下:
>>> data[2] = "abc"
我们可以使用 Python 内置的 remove 方法从列表中删除一个数据项。
>>> data.remove("Hello")
>>> data
[1, 5, 'abc', True]
如何遍历列表
我们也可以遍历列表,从中找出某个元素,然后操作这个元素。
>>> for i in data:
... print(i)
...
输出:
1
5
abc
True
如何检查一个数据项存在与否
要检查某个数据项是否存在于列表中,我们可以像下面这样使用 if:
>>> if 'abc' in data:
... print("yess..")
...
yess..
如何复制列表数据
要将一个列表的数据复制到另一个列表,我们需要使用 copy 方法。
>>> List2 = data.copy()
>>> List2
[1, 5, 'abc', True]
如何检查列表长度
我们可以使用 Python 内置的 len 方法检查列表的长度。
>>> len(data)
4
如何连接两个列表
我们可以使用 + 操作符连接两个列表。
>>> list1 = [1, 4, 6, "hello"]
>>> list2 = [2, 8, "bye"]
>>> list1 + list2
[1, 4, 6, 'hello', 2, 8, 'bye']
如果我们尝试访问一个在列表中不可用的元素位置会怎样?我们会得到一个 list index out of range error。
>>> list1[6]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: list index out of range
元组:
元组(tuple)是一种有序但不可变(即数据不能被改变)的数据类型。
创建一个元组:
>>> data = ( 1, 3 , 5, "bye")
>>> data
(1, 3, 5, 'bye')
如何访问元组中的元素
我们可以用访问列表元素的方式访问元组中的元素:
>>> data[3]
'bye'
用以下方式访问索引范围:
>>> data[2:4]
(5, 'bye')
如何改变元组的值
如果你正在思考如何改变元组的值,我就真拿你当朋友了。我们不能改变元组的值,因为它是不可变的。如果我们尝试改变元组的值,会得到如下错误:
>>> data[1] = 8
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'tuple' object does not support item assignment
有一种改变元组的值的变通方法:
>>> data = ( 1, 3 , 5, "bye")
>>> data_two = list(data) # 转换成列表
>>> data_two[1] = 8 # 列表是可变的,更新值
>>> data = tuple(data_two) # 再次转换成元组
>>> data
(1, 8, 5, 'bye')
我们见过的其它列表方法都适用于元组。
[注意:一旦元组被创建出来,就不能添加新值到其中了]。
集合
集合(set)是 Python 中的另一种数据类型,它是无序的,没有索引。集合的声明方式如下:
>>> data = { "hello", "bye", 10, 15 }
>>> data
{10, 15, 'hello', 'bye'}
如何访问值
由于集合没有索引,所以我们不能直接访问集合中的值。因此,我们需要使用 for 循环:
>>> for i in data:
... print(i)
...
如何改变一个值
一旦集合被创建,值就不能被改变。
如何添加一个数据项
Python 提供的 add 方法就可以将数据项添加到集合。
>>> data.add("test")
>>> data
{10, 'bye', 'hello', 15, 'test'}
如何检查长度
我们可以使用 len 方法检查集合的长度。
>>> len(data)
5
如何删除一个数据项
使用 remove 方法移除数据项:
>>> data.remove("test")
>>> data
{10, 'bye', 'hello', 15}
函数与参数
函数(Function)是一种声明我们想要执行的操作的简单方式。在函数的帮助下,你可以根据操作拆分逻辑。
函数就是一个代码块,它帮助我们复用重复的逻辑。函数既可以是内置的也可以是用户自定义的。
我们使用 def 关键字声明函数,下面是函数的语法:
>>> def hello_world():
... print("Hello world")
...
我们声明了一个函数,它会在被调用时打印出“Hello World”语句。调用函数的语法如下:
>>> hello_world()
我们会得到以下结果:
Hello world
记住,函数调用中的 () 括号表示执行函数本身。你可以把圆括号去掉试一下。
>>> hello_world
你会得到以下输出:
<function hello_world at 0x1083eb510>
当我们把圆括号从函数调用上去掉时,它会给我们一个函数引用。从上面可以看出:function hello_world 的引用指向了 0x1083eb510 这个内存地址。
如果你要执行一个加法操作,你可以先声明 a 和 b,然后把它们相加。
>>> a = 5
>>> b = 10
>>> a + b
15
这是一种方式。但是,如果 a 和 b 的值变了,你就需要再这么来一次。
>>> a = 5
>>> b = 10
>>> a + b
15
>>> a = 2
>>> b = 11
>>> a + b
13
这看起来仍然是可行的。现在,假设我们需要进行一百次两数相加操作,每次相加的两个数都不同,这就有得做了。别担心,我们有函数,它可以解决这个问题。
>>> def add(a,b):
... print(a+b)
...
我们在这里把 a 和 b 作为了 add 函数的必备参数(compulsory argument),调用这个函数的语法如下:
>>> add(10,5)
输出:
15
定义一个函数并使用它是不是很容易?如果我们不传递参数会怎么样?
>>> add()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: add() missing 2 required positional arguments: 'a' and 'b'
Python 抛出了一个 TypeError,告知我们这个函数需要有两个参数。
如果我们传递了第三个参数,你能猜出来会发生什么吗?
>>> add(10,5,1)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: add() takes 2 positional arguments but 3 were given
Python 会告诉我们:我们传递了三个参数,但是只有两个位置参数。
所以当我们不知道函数的参数数量时该怎么做呢?我们可以使用 args 和 kwargs 解决这个问题。
Args:
当你不知道要给函数传递多少个参数时,可以使用 args 和 kwargs(kwargs 会在下面进行讨论)。
要给函数传递 n 个参数,我们使用 args。在参数的前面添加一个 *。
记住:当你在前面添加
*时,你会得到一个由参数构成的元组。
>>> def add(*num):
... print(num)
...
这里的 *num 是 args 的一个实例。当我们调用 add 函数时,可以传入 n 个参数,也不会有 TypeError 被抛出。
>>> add(1,2,3)
(1, 2, 3)
现在我们使用 Python 内置的 sum 函数进行加法操作:
>>> def add(*num):
... print(sum(num))
...
当我们调用 add 函数时,就会得到以下输出:
>>> add(1,2,3) # 函数调用
6
>>> add(1,2,3,4) # 函数调用
10
关键字参数:
有时候,我们并不知道传递给函数的参数顺序。这时就可以使用关键词参数,不管我们以何种顺序传递参数,函数都会知道对应的参数值。来看这个示例:
>>> def user_details(username, age):
... print("Username is", username)
... print("Age is", age)
...
像下面这样调用这个函数:
>>> user_details("Sharvin", 100)
输出如下:
Username is Sharvin
Age is 100
这看起来没错,但是如果我们用这种方式调用这个函数呢:
>>> user_details(100, "Sharvin")
输出如下:
Username is 100
Age is Sharvin
这看起来不太对。username 取了 100 这个值,而 age 取了“Sharvin”这个值。在我们不知道参数的顺序时,可以在调用函数时使用关键词参数:
>>> user_details(age=100, username="Sharvin")
输出:
Username is Sharvin
Age is 100
默认参数:
有时,我们并不确定某个参数是否会在函数被调用时得到值。这种情况下可以使用默认参数,例如:
>>> def user_details(username, age = None):
... print("Username is", username)
... print("Age is", age)
...
这里将 None 赋给了 age 参数,如果我们在调用函数时不传递第二个参数,它就会自动将 None 作为默认值。
让我们调用一下这个函数吧:
>>> user_details("Sharvin")
输出:
Username is Sharvin
Age is None
如果我们传了第二个参数,它就会覆盖 None 并使用自己作为参数值。
>>> user_details("Sharvin", 200)
Username is Sharvin
Age is 200
但是,如果我们将第一个参数设置为默认并把第二个参数设置为必备参数,会怎么样呢?打开 Python shell,一探究竟:
>>> def user_details(username=None, age):
... print("Username is", username)
... print("Age is", age)
...
你会得到如下错误:
File "<stdin>", line 1
SyntaxError: non-default argument follows default argument
记住: 所有的必备参数必须先于默认参数声明。
Kwargs:
有时你并不知道会有多少个关键字参数会被传递给函数,这种情况可以使用 Kwargs。
要使用 kwargs,我们要把它放在 参数之前。
记住: 当你在前面附加一个
**时,你将会收到一个参数字典。
让我们通过示例理解这个吧。声明一个函数,以 username 为参数,username 前面会有 **。
>>> def user(**username):
... print(username)
...
当我们调用 user 函数时,我们会收到一个字典。
>>> user(username1="xyz",username2="abc")
输出:
{'username1': 'xyz', 'username2': 'abc'}
所以这里发生了什么呢?它看起来和 args 一摸一样,是不是?
不,并不是。在 args 中,你不能通过名字传值,因为它在元组中。这里我们得到的数据是字典,所以我们可以轻而易举地访问值。
考虑下这个示例:
>>> def user(user_details):
... print(user_details['username'])
...
调用我们的函数:
>>> user(username="Sharvin",age="1000")
输出如下:
Sharvin
作用域
作用域(scope)定义了变量或函数的作用范围。Python 中有两种类型的作用域:全局(global)和局部(local)。
全局作用域
在 Python 代码主体中创建的变量或函数被称为全局变量或全局函数,它们是全局作用域的一部分。例如:
>>> greet = "Hello world"
>>> def testing():
... print(greet)
...
>>> testing()
Hello world
我们在这里定义的是一个全局可用的变量 greet,因为它是在程序体内声明的。
局部作用域
在函数内部创建的变量或函数被称为局部变量或局部函数,它们是局部作用域的一部分:
>>> def testing():
... greet = "Hello world"
... print(greet)
...
>>> testing()
Hello world
这里的 greet 是在 testing 函数内部创建的,它只能在这个函数内部使用。我们试着这代码主体内访问它,看看会发生什么:
>>> print(greet)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'greet' is not defined
记住: 在测试上述代码之前要重启 Python 控制台:先按 ctrl + d 停止程序,再使用 python3 命令启动 shell。因为第一个例子中将 greet 变量声明在全局作用域,所以在运行第二个示例时,它仍然在内存中可用。
由于 greet 并不是全局可用,所以我们会得到一个指出它未定义的错误。
Return 语句:
到目前为止,我们的函数都非常简单:它们接收数据,进行处理,然后打印它们。但是在真实世界中,你需要函数将输出返回,以便它可以在不同操作中使用。
return 语句可以达到这个目的。记住,return 语句只是函数和方法的一部分,它的语法非常简单。
>>> def add(a, b):
... return a + b
...
>>> add(1,3)
4
我们将输出返回,而没有打印相加的结果。返回值也可以被存放在变量中。
>>> sum = add(5,10)
>>> print(sum)
15
Lambda 表达式
有时候,你并不想在一个函数内执行太多的计算,这时写一个完整的函数就没什么意义了。要解决这个问题,我们可以使用 lambda 表达式或 lambda 函数。
那么什么是 lambda 表达式呢?它是一个匿名函数,表达式只能有一行。Lambda 表达式可以接收 n 个参数。
Lambda 表达式的语法如下:
variable = lambda arguments: operation
让我们通过一个示例进一步理解:
>>> sum = lambda a: a + 10
我们在这里声明了一个变量 sum,它会被用来调用 lambda 函数。a 表示传递给函数的参数。
让我们调用一下我们的函数吧:
>>> x(5)
15
列表推导式
考虑这样这一种场景:你想要一个由平方数组成的列表。通常你会声明一个 squares 列表,然后在一个 for 循环中计算这些数字的平方。
>>> squares = []
>>> for x in range(10):
... squares.append(x**2)
...
>>> squares
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
虽然这是可行的,但是在列表推导式(list comprehension)的帮助下,我们用一行代码就可以实现:
实现的方式有两种,我们两个方法都理解一下。
>>> squares = list(map(lambda x: x**2, range(10)))
>>> squares
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
这里使用 list 构造器构造了一个列表,它里面是计算平方值的 lambda 函数。另一种方式也得到了同样的结果,如下:
>>> squares = list(x**2 for x in range(10))
>>> squares
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
我更喜欢这种方式,因为它更简单、易懂。
如果我们有一个条件,想要一组相同的两个数字该怎么办呢?嗯,我们需要写两个 for 循环和一个 if 条件。
我们来看一下这该怎么写:
>>> num_list = []
>>> for i in range(10):
... for j in range(10):
... if i == j:
... num_list.append((i,j))
...
>>> num_list
[(0, 0), (1, 1), (2, 2), (3, 3), (4, 4), (5, 5), (6, 6), (7, 7), (8, 8), (9, 9)]
这工作量还是挺大的,而且从可读性方面来看,代码更难理解了。
让我们用列表推导式实现它吧。
>>> num_list = list((i,j) for i in range(10) for j in range(10) if i == j)
看见了吧,用一个表达式得到同样的结果是不是很容易?这就是列表生成式的强大之处。
面向对象编程
Python 是一门多范式的编程语言,即它可以使用不同的方式解决同一个问题。其中的一种范式就是过程式(procedural)或函数式(functional)编程,代码结构就像一个食谱——一组以函数或代码块呈现的步骤。
解决这个问题的另一种方式就是创建类(class)和对象(object),这就是所谓的面向对象编程(OOP)。对象就是一组数据(变量)和方法的集合,方法操作这些数据。类是对象的蓝图。
理解面向对象编程的关键在于:以对象为中心——它们不仅代表数据,还代表程序的结构。
你可以为要处理的问题选择最适合的范式,在一个程序中混用不同的范式,也可以在程序的演进过程中从一种范式切换到另一种范式。
面向对象编程的优点
-
继承(Inheritance): 这是面向对象编程中最有用的概念之一。它指明子对象会拥有父对象所有的属性和行为。因此,继承允许我们定义一个类,这个类将继承另一个类的所有方法和属性。
-
多态(Polymorphism): 为了理解多态,我们可以将这个词划分为两部分。第一部分“poly”表示很多,而“morph”表示形成或形状。因此 polymorphism 表示一个任务可以以不同方式执行。
例如,你有一个
animal类,并且所有的动物都能说话。但是它们说话的方式不同。这里的“说话”这个行为就是多态的,它依赖于具体的动物。所以,抽象的“动物”实际上并不“说话”,但是特定的动物(比如狗和猫)就有“说话”这个动作的具体实现。多态意味着相同的函数名或方法名可以被用于不同的类型。
-
封装(Encapsulation): 在面向对象编程中,你可以限制对方法和变量的访问——我们可以把方法和变量设置成私有的。这就能防止数据被意外修改,这种方式被称为封装。
首先,我们会理解类、对象和构造器。之后,我们会再次查看上述属性。如果你已经对类、对象和构造器有所了解,可以自由跳过。
类:
Python 中一些可以直接使用的基本数据结构,比如数字、字符串和列表。这些都可以用来简单地表示名字、地方、价值,等等。
但是如果我们有更复杂的数据,该怎么办呢?如果这些数据有着重复的属性,我们可以做什么呢?
假设我们有一百只不同的动物,每只动物都有名字、年龄、腿,等等。如果我们想给每只动物再添加一个属性,或者再添加一只动物到这个列表中,该怎么办呢?要应付这种复杂的情况,我们需要使用类(class)。
根据 Python 官方文档:
类提供了一种将数据数据和功能捆绑在一起的方法。创建一个新类意味着创建一种新的对象类型,从而允许创建一个该类型的新实例。
每个类的实例可以拥有保存状态的属性,也可以有改变状态的(定义在类中的)方法。
类的语法:
class ClassName:
<expression-1>
.
.
.
<expression-N>
我们使用 class 关键字定义一个类。我们将定义一个 Car 类。
class Car:
pass
方法:
方法(Method)看起来和函数一样,它们之间唯一的区别就是:方法依赖于对象。函数可以通过函数名调用,而方法必须通过它们的类引用调用。方法在类中定义。
在我们的示例中,创建了两个方法:一个是 engine,另一个是 wheel。这两个方法定义了汽车的可用部件。
下面这段程序会让我们对类有一个更好的理解:
>>> class Car:
... def engine(self):
... print("Engine")
...
>>> Car().engine()
Engine
在这里,我们通过 Car() 引用调用 engine 方法。
总而言之,类提供定义的蓝图,但并不提供任何真实内容。Car 类定义了引擎(engine),但它并不会声明一辆特定汽车的引擎是什么。引擎是通过对象声明的。
对象:
对象(object)是类的实例。考虑上述汽车的例子,汽车就是我们的类,而 toyota 就是汽车的对象。我们可以创建多个对象的副本。每个对象都必须使用类进行定义。
创建对象的语法如下:
toyota = Car()
class Car:
def engine(self):
print("Engine")
def wheel(self):
print("Wheel")
toyota = Car()
上面的 toyota = Car() 就是一个 类对象。类对象支持两种类型的操作:属性引用和实例化。
类的实例化使用函数符号,实例化操作(“调用”类对象)会创建一个空对象。
现在我们可以使用 toyota 对象调用 Car 类的不同方法,让我们调用下方法 engine 和 wheel 吧。
打开你的编辑器,创建一个名为 mycar.py 的文件。将以下代码复制到该文件中:
class Car:
def engine(self):
print("Engine")
def wheel(self):
print("Wheel")
if __name__ == "__main__":
toyota = Car()
toyota.engine()
toyota.wheel()
保存上述代码。现在让我们仔细看一看这个程序。
我们利用 Car 类创建了一个 toyota 对象。toyota.engine() 是一个方法对象,当一个方法对象被调用时,到底发生了什么?
调用 toyota.engine() 时并没有传递任何参数,但是如果你看一眼方法声明,你就会发现它有一个 self 参数。
你可能会因没有抛出错误而感到疑惑。其实每次我们在使用方法对象时, toyota.engine() 都会被转换成 Car.engine(toyota)。
使用以下命令运行程序。
python mycar.py
你会得到以下输出:
Engine
Wheel
构造器:
__init__ 方法是 Python 中的构造器方法(constructor method),构造器方法用于初始化数据。
打开 Python shell,输入这个示例:
>>> class Car():
... def __init__(self):
... print("Hello I am the constructor method.")
...
调用这个类得到的输出如下:
>>> toyota = Car()
Hello I am the constructor method.
注意: 你永远都不必调用 init() 方法——它会在创建类实例时被自动调用。
实例属性:
所有的类都有对象,所有的对象都有属性(attributes)。属性就是对象具有的性质。我们使用 __init__()方法声明一个对象的初始属性。
以汽车为例:
class Car():
def init(self, model):
self.model = model #实例属性
在我们的示例中,每个 Car() 都有一个特定的型号(model),因此实例属性对每个实例来说都是唯一的。
类属性:
我们看到实例属性是针对每个对象来说的,但是类属性对所有的实例来说都是一样的。我们借助类属性看一下汽车的示例:
class Car():
no_of_wheels = 4 #类属性
所以每辆汽车都可以有不同的型号,但是所有的汽车都只会有四个轮子。
Self:
现在我们来理解下 self 的含义,以及如何在面向对象编程中使用它。self 表示类的实例,我们可以通过这个关键字访问由构造器和类方法初始化的数据。
现在来看一个使用 self 的示例,我们在 Car 类中创建一个名为 brand 的方法。
在 __init__ 方法中,我们会在实例化对象时传递汽车型号的名字,这个名字可以在类中的任何地方被访问,比如我们的 self.model。
打开名为 mycar.py 的文件,将旧代码换成这个代码:
class Car():
def __init__(self, model):
self.model = model
def brand(self):
print("The brand is", self.model)
if __name__ == "__main__":
car = Car("Bmw")
car.brand()
现在当我们使用以下命令运行上述程序时:
python mycar.py
会得到以下结果:
The brand is Bmw
注意: self 是只是一个习惯,它并不是一个 Python 的关键词。方法中的 self 只是一个参数,我们可以使用另一个名字替换它。但是推荐使用 self,因为它会提高代码的可读性。
继承:
继承指一个类继承了另一个类的属性。
被继承了属性的那个类称为基类(base class)。继承了另一个类的属性的那个类被称为派生类(derived class)。
继承可以被定义为父子关系。子类继承父类的性质,因此子类就是派生类,而父类就是基类。这里的性质指的是属性和方法。
派生类定义的语法如下:
class DerivedClassName(BaseClassName):
<statement-1>
.
.
.
<statement-N>
注意到子类覆盖或扩展父类方法的属性和行为 z 这一点很重要。这就是说,子类继承父类所有的属性和行为,但是子类又可以声明不同的行为。
最基本的类类型是 object,它通常被所有的其它类作为父类继承。我们来修改一下之前的示例,理解继承是如何工作的。
创建一个名为 vehicle 的基类:
class Vehicle:
def __init__(self, name):
self.name = name
def getName(self):
return self.name
我们已经创建了一个 Vehicle 类,使用 self.name 实例化了一个构造器,我们将在 getName 方法中使用 self.name。每次调用这个方法时,它都会返回对象初始化时传入的 name。
现在创建一个子类 Car:
class Vehicle:
def __init__(self, name):
self.name = name
def getName(self):
return self.name
class Car(Vehicle):
pass
Car 是 Vehicle 的一个子类,它继承了父类所有的方法和属性。
现在在子类 Car 中使用父类 Vehicle 的方法和属性。
class Vehicle:
def __init__(self, name, color='silver'):
self.name = name
self.color = color
def get_name(self):
return self.name
def get_color(self):
return self.color
class Car(Vehicle):
pass
audi = Car("Audi r8")
print("The name of our car is", audi.get_name(), "and color is", audi.get_color())
理解一下我们在这里干了啥。
我们声明了一个名为 Vehicle 的类,它的构造器将名字作为参数,而颜色有一个默认参数。
类中有两个方法:get_name 返回名字,而 get_color 返回颜色。我们实例化了一个对象,传递了一个汽车名。
在这里,你会发现我们在子类声明中使用了父类的方法。
使用以下命令运行上述程序:
python mycar.py
输出:
The name of our car is Audi r8 and color is silver
我们也重写了一个父类的方法或属性。在以上示例中,我们定义交通工具的颜色为银色,但是如果我们的汽车是黑色的呢?
对于每个子类,我们不能直接在它的父类中进行修改,这就有了重写机制。
class Vehicle:
def __init__(self, name, color='silver'):
self.name = name
self.color = color
def get_name(self):
return self.name
def get_color(self):
return self.color
class Car(Vehicle):
def get_color(self):
self.color = 'black'
return self.color
audi = Car("Audi r8")
print("The name of our car is", audi.get_name(), "and color is", audi.get_color()
如你所见,我们并没有实例化一个构造器。因为子类 Car 只是使用来自 Vehicle 类的属性,而它早就继承这些属性了。所以在这种场景下,没有必要重新实例化这些属性。
运行程序,输出如下:
The name of our car is Audi r8 and color is black
Super:
super() 返回一个父类的临时对象,允许我们调用父类的方法。
直接使用 super() 调用已有的方法让我们免于在子类中重写那些方法,允许我们用最小的代码改动替换父类。因此 super 扩展了继承方法的功能。
让我们使用 super() 对汽车示例进行扩展吧。我们将用父类 Vehicle 中的 brand_name 和 color 重新实例化一个构造器。现在在子类(Car)中使用 super 调用父类的这个构造器,我们将创建一个 get_description 方法,它从 Car 类返回 self.model 并从 Vehicle 类返回 self.brand_name 和 self.color。
class Vehicle:
def __init__(self, brand_name, color):
self.brand_name = brand_name
self.color = color
def get_brand_name(self):
return self.brand_name
class Car(Vehicle):
def __init__(self, brand_name, model, color):
super().__init__(brand_name, color)
self.model = model
def get_description(self):
return "Car Name: " + self.get_brand_name() + self.model + " Color:" + self.color
c = Car("Audi ", "r8", " Red")
print("Car description:", c.get_description())
print("Brand name:", c.get_brand_name())
运行上述程序,输出如下:
Car description: Car Name: Audi r8 Color: Red
Brand name: Audi
多重继承:
多重继承(multiple inheritance)是指一个类从多个父类继承方法和属性。它允许我们在派生类或子类中使用多个基类或父类的性质。
多继承的通用语法如下:
class DerivedClassName(Base1, Base2, Base3):
<statement-1>
.
.
.
<statement-N>
让我们使用多继承对交通工具这个示例进行扩展吧。在这个示例中我们会创建三个类:Vehicle、Cost 和 Car。
Vehicle 类 和 Cost 会成为父类。Vehicle 类表示通用属性,而 Cost 类表示价值。
因为 Car 有一个通用属性和价值,所以它将会有两个父类。因此我们将继承多个父类。
class Vehicle:
def __init__(self, brand_name):
self.brand_name = brand_name
def get_brand_name(self):
return self.brand_name
class Cost:
def __init__(self, cost):
self.cost = cost
def get_cost(self):
return self.cost
class Car(Vehicle, Cost):
def __init__(self, brand_name, model, cost):
self.model = model
Vehicle.__init__(self, brand_name)
Cost.__init__(self, cost)
def get_description(self):
return self.get_brand_name() + self.model + " is the car " + "and it's cost is " + self.get_cost()
c = Car("Audi ", "r8", "2 cr")
print("Car description:", c.get_description())
在上述程序中,你会发现有一个东西与这篇教程中的其它程序都不同,我在 Car 类的构造器中使用了 Vehicle.__init(self, brand_name)。这是调用父类属性的一种方式,另一种方式就是我在上面提到的 super。
运行程序,结果如下:
Car description: Audi r8 is the car and it's cost is 2 cr
尽管多重继承可以被高效使用,但是也需要保持谨慎,避免程序变得模棱两可,防止程序对于其它程序员难于理解。
多态:
多态一词表示具有很多种形式。在编程中,多态表示同一个函数名(但是不同的函数签名)被用于不同的类型。
让我们用多态扩展汽车程序吧。我们将会创建两个类:Car 和 Bike。两个类都有共同的方法或函数,但是它们会打印不同的数据。程序本身很容易理解:
class Car:
def company(self):
print("Car belongs to Audi company.")
def model(self):
print("The Model is R8.")
def color(self):
print("The color is silver.")
class Bike:
def company(self):
print("Bike belongs to pulsar company.")
def model(self):
print("The Model is dominar.")
def color(self):
print("The color is black.")
def func(obj):
obj.company()
obj.model()
obj.color()
car = Car()
bike = Bike()
func(car)
func(bike)
运行以上代码,结果如下:
Car belongs to Audi company.
The Model is R8.
The color is silver.
Bike belongs to pulsar company.
The Model is dominar.
The color is black.
封装:
在大多数面向对象编程中,我们都可以限制对方法和变量的访问。这能防止数据被意外修改,也被称为封装。
让我们在汽车示例中使用封装吧。假设我们有一个绝密的引擎。在第一个示例中,我们将使用 私有变量 隐藏引擎。在第二个示例中,我们将使用 私有方法 对引擎进行隐藏。
示例 1:
cclass Car:
def __init__(self):
self.brand_name = 'Audi '
self.model = 'r8'
self.__engine = '5.2 L V10'
def get_description(self):
return self.brand_name + self.model + " is the car"
c = Car()
print(c.get_description)
print(c.__engine)
在这个示例中,self.__engine 是私有属性。当我们运行这个程序时,就会得到以下结果。
Audi r8 is the car
AttributeError: 'Car' object has no attribute 'engine'
我们得到了一个错误:Car 对象没有 _engine 属性,因为它是一个私有对象。
示例 2:
我们也可以通过在方法名前面加上 __ 定义私有方法。以下就是一个定义私有方法的示例。
class Car:
def __init__(self):
self.brand_name = 'Audi '
self.model = 'r8'
def __engine(self):
return '5.2 L V10'
def get_description(self):
return self.brand_name + self.model + " is the car"
c = Car()
print(c.get_description())
print(c.__engine())
示例中的 def __engine(self) 是一个私有方法。运行程序,结果如下:
Audi r8 is the car
AttributeError: 'Car' object has no attribute '__engine'
假设现在我们想访问私有属性或私有方法,我们可以这么做:
class Car:
def __init__(self):
self.brand_name = 'Audi '
self.model = 'r8'
self.__engine_name = '5.2 L V10'
def __engine(self):
return '5.2 L V10'
def get_description(self):
return self.brand_name + self.model + " is the car"
c = Car()
print(c.get_description())
print("Accessing Private Method: ", c._Car__engine())
print("Accessing Private variable: ", c._Car__engine_name)
程序的输出如下:
Audi r8 is the car
Accessing Private Method: 5.2 L V10
Accessing Private variable: 5.2 L V10
封装使你可以更好地控制代码中的耦合程度,允许你在不影响其它部分的情况下修改类的实现。
装饰器:
假设你需要扩展多个函数的功能,你会怎么做?
一种方式是进行函数调用,你可以在函数内进行处理。对三十到四十个函数调用进行修改,还要记住应该把调用放在何处,这是一项很棘手额工作。不过,Python 给你提供了一种更加优雅的方式——装饰器(decorator)。
什么是装饰器?装饰器就是一个函数,它接受一个函数并扩展其功能,整个过程不涉及对原函数的显式修改。我觉得你仍然不太明白装饰器是什么,别急,我们有一个示例对它进行解释。
让我们通过示例理解装饰器吧。有两种写装饰器的方法。
方法 1
我们声明一个装饰器函数,并将我们期望的函数作为参数传入。在装饰器函数内部,我们写一个包装函数执行操作并将其返回。
>>> def my_decorator(func):
... def wrapper():
... print("Line Number 1")
... func()
... print("Line Number 3")
... return wrapper
...
>>> def say_hello():
... print("Hello I am line Number 2")
...
要调用这个函数,我们将 say_hello 赋给装饰器作为参数。
>>> say_hello = my_decorator(say_hello)
我们还可以使用 say_hello 检查引用,结果会告诉我们它已经被 my_decorator 函数包装。
<function my_decorator.<locals>.wrapper at 0x10dc84598>
调用一下 say_hello 函数:
>>> say_hello()
Line Number 1
Hello I am line Number 2
Line Number 3
“Hello I am line Number 2”魔术般地被打印在“Line Number 1”和“Line Number 3”之间,因为这个函数调用就在那里执行的。
方法 1 很笨重,因此很多人更喜欢使用另一种方式。
方法 2
这里我们的装饰器装饰仍然不变,但是我们改变了调用被赋给装饰器的方式。每个需要装饰器的函数都用 @decorator_name 包裹自己。
>>> def my_decorator(func):
... def wrapper():
... print("Line Number 1")
... func()
... print("Line Number 3")
... return wrapper
...
>>> @my_decorator
... def say_hello():
... print("Hello I am line Number 2")
...
>>> say_hello()
输出不变:
Line Number 1
Hello I am line Number 2
Line Number 3
装饰器是一个非常强大的工具,它被用在下列开发场景中:
- 日志设置
- 配置设置
- 错误捕获
- 为所有的函数和类扩展通用功能
异常:
在学习各种语法的过程中,我们也遇到了各种各样的错误。那些错误因为语法问题而出现。但是在真实应用中,错误(通常也称为 bug)并不只是由语法问题引起的,也可能是网络或其他原因。
我们使用 Try-Except 处理这些问题。在 try 块中,写我们想要执行的表达式,而在 except 块中,我们捕获错误。Try-Except 块形式如下:
try:
expression
except:
catch error
让我们通过示例来理解吧:
>>> try:
... print(value)
... except:
... print("Something went wrong")
...
我们尝试打印出 value 变量,但是它并没有被定义。所以我们得到了以下结果:
Something went wrong
你可能在想,“something went wrong”这一行并没有多大帮助。所以我们要怎样才能知道是什么错了呢?
我们可以把异常打印出来,然后用它找出是什么出错了。我们在示例中试一下吧:
>>> try:
... print(value)
... except Exception as e:
... print(e)
...
结果为:
name 'value' is not defined
哇!太神奇了。它提示我“value”没有被定义。
Python 也提供了一个名为 raise 的工具。假如你不希望某个条件发生,你想在它发生的时候把它抛出来。在这种情况下,你可以使用 raise。示例如下:
>>> i = 5
>>> if i < 6:
... raise Exception("Number below 6 are not allowed")
...
我们得到的结果如下:
Traceback (most recent call last):
File "<stdin>", line 2, in <module>
Exception: Number below 6 are not allowed
异常有很多子类型,我推荐你阅读 Python 文档,进一步理解它们。
包的导入:
你已经学完了 Python 的基础知识,现在已经做好构建出色应用程序的准备了。但是,等一等,我们还漏掉了一些重要的主题。
如果没有包的导入,你将被迫在一个文件里写下所有的代码。想象一下这是多么的糟糕。
创建两个文件,分别命名为 mani.py 和 hello.py。记住,两个文件需要在同一个目录中。
将以下代码复制到 hello.py中:
def say_hello():
print("Hello world")
将以下代码复制到 main.py 中:
import hello
if __name__ == "__main__":
hello.say_hello()
我们在 hello.py 中声明了一个 say_hello() 函数,它打印“Hello world”。在 main.py 中,你会看到一个 import 语句。我们导入 hello 模块,并从那个模块调用 say_hello 函数。
使用以下命令运行程序:
➜ python main.py
输出:
Hello world
现在我们来理解一下如何导入另一个目录中的模块。
我们先创建一个名为“data”的目录,然后将 hello.py 移动到该目录下。
打开 main.py,修改之前的 import 语句:
from data import hello
if __name__ == "__main__":
hello.say_hello()
从一个目录导入的方式有两种:
- 方法 1:
from data import hello - 方法 2:
import data.hello
我更喜欢方法 1,因为它更易读。你可以选择适合自己的导入方式。
使用以下命令运行我们的应用:
➜ python main.py
出现了一个错误,为什么会这样呢?我们没做错,仔细检查一下错误吧:
Traceback (most recent call last):
File "main.py", line 1, in <module>
from data import hello
ImportError: No module named data
Python 告诉我们它没有识别出名为“data”的模块。要解决这个问题,我们需要在“data”目录中创建一个 __init__.py。文件内容留空,再次运行程序,你会得到以下结果:
Hello world
默认情况下,Python 不把目录当作模块对待。要通知 Python 将某个目录视为模块,需要有 __init__.py。
JSON 处理:
如果你之前从事过 web 开发或应用开发,你可能会知道所有的 API 调用都以 JSON 格式进行。虽然 JSON 看起来和 Python 中的字典很像,但是它完全不同。
Python 提供了一个内置的 json 包,用于处理 JSON。要使用这个包,我们需要先导入它:
import json
这个库提供了两个处理 JSON 的方法,我们逐一进行理解:
JSON loads:
如果你想把 JSON 字符串转换回字典,就需要使用 load 方法。打开 Python shell,复制-粘贴以下代码:
>>> import json
>>> json_string = '{ "user_name":"Sharvin", "age":1000}' #JSON 字符串
>>> type(json_string)
<class 'str'>
>>> data = json.loads(json_string)
>>> type(data)
<class 'dict'>
>>> data
{'user_name': 'Sharvin', 'age': 1000}
JSON dumps:
现在,让我们用 dumps 方法将数据转换回 JSON 字符串格式吧。
>>> jsonString = json.dumps(data)
>>> type(jsonString)
<class 'str'>
>>> jsonString
'{"user_name": "Sharvin", "age": 1000}'
若想学习更多关于 JSON 操作的支持,可以前往 Python 文档。
说完了
说完了!我希望你现在已经理解 Python 的基础知识。祝贺你!这是一个巨大的成就。
欢迎反馈。如果你想了解任何其它主题的内容,你可以在 Twitter 上发送主题名字并带上我的 Twitter handle(@sharvinshah26)。
原文:The Ultimate Guide to Python: How to Go From Beginner to Pro,作者:Sharvin Shah