

Kubernetes 是一个开放源代码的容器编排平台,可自动执行容器的部署、管理、扩容伸缩和网络管理。
它是由 Google 使用 Go 语言开发的,这项了不起的技术从 2014 年开始一直是开源的。
根据 Stack Overflow 开发者调研报告 - 2020,Kubernetes 是 #3 最喜爱的平台以及 #3 最想要的平台。
除了功能强大之外,Kubernetes 是公认的难上手。入门确实不容易,但是只要你符合入门条件并且有足够的耐心完成该指南,你将可以:
- 对基础知识有深入的了解。
- 可以创建和管理 Kubernetes 集群。
- 部署任意应用程序到 Kubernetes 集群上。
入门条件
- 熟悉 JavaScript
- 熟悉 Linux 终端
- 熟悉 Docker(建议阅读:Docker 入门教程 - 2021 最新版)
项目代码
实例中的代码可以在这个仓库中找到(你的 ⭐ 是我动力的源泉)。k8s 分支包含完整的代码。
目录
- 容器编排和 Kubernetes 简介
- 安装 Kubernetes
- Kubernetes 初体验
- Kubernetes 的架构
- Control Plane 组件
- Node 组件
- Kubernetes 对象
- Pods
- Services
- 全景图
- 清除 Kubernetes 相关资源
- 声明式部署方法
- 编写你的第一套配置
- Kubernetes 控制面板
- 使用多容器应用程序
- 部署计划
- 复用 Controllers, Replica Sets 以及 Deployments
- 创建你的第一个部署
- 调试 Kubernetes 资源
- 从 Pods 获取容器日志
- 环境变量
- 创建数据库部署
- Persistent Volumes 和 Persistent Volume Claims
- Persistent Volumes 的动态预配置
- 通过 Pods 连接 Volumes
- 组装起来
- 使用 Ingress Controllers
- 设置 NGINX Ingress Controller
- Kubernetes 中的 Secret 和配置
- 在 Kubernetes 中执行更新发布
- 组合 Configurations
- 答疑
- 结论
容器编排和 Kubernetes 简介
摘自 Red Hat —
"容器编排是指自动化容器的部署、管理、扩展和联网。
容器编排可以在使用容器的任何环境中使用。它可以帮助你在不同环境中部署相同的应用,而无需重新设计。"
让我来给你看一个例子。假设你开发了一个很棒的应用,这个 应用可以根据时间向人们推荐他们应该吃什么。
假设你已经使用 Docker 容器化了应用并将其部署在了 AWS 上 。

如果应用因为某种原因宕机,用户马上就不能访问该服务了。
要解决此问题,可以为同一应用程序制作多个副本,使其服务高可用。

即使其中一台实例发生故障,其它两台实例也可以为用用户提供服务。
假设你的应用程序在熬夜党中流行了起来,在你晚上睡觉的时候涌入大量的请求。
如果所有的实例都因为过载而无法响应该怎么办?谁来进行自动伸缩?即使你扩容 了 50 个副本,谁来做健康检查?如何设置网络使使流量打到合适的端点上?负载均衡也是一个大问题,你说呢?
Kubernetes 可以很容易的搞定这些问题。Kubernetes 是一个由多个组件组成的容器编排平台,它可以一刻不眠的使是你的服务保持在理想状态。
假设你要连续运行 50 个应用程序副本,如果请求量激增,服务器也能自动扩容。
你只需把你的需求告诉 Kubernetes,它将为你完成其余的繁重工作。

Kubernetes 会实现并维护状态。如果有旧副本挂掉了,它将创建新的副本,管理网络和存储,推出或回滚更新,甚至在必要时升级服务。
安装 Kubernetes
实际上,在本地计算机上运行 Kubernetes 与在云平台上运行 Kubernetes 有很大不同。你需要下面两个程序,来启动和运行 Kubernetes。
- minikube - 它可以在本地计算机的虚拟机(VM)上运行单节点 Kubernetes 集群。
- kubectl - Kubernetes 命令行工具,可以在 Kubernetes 集群上执行命令。
除了这两个程序之外,你还需要一个管理程序和一个容器平台。显然 Docker 就是所需的容器平台。推荐的管理程序如下:
Hyper-V 作为可选功能内置于 Windows 10(Pro、Enterprise 和 Education)中,可以从控制面板中打开。
HyperKit 是 Mac 平台 Docker Desktop 的核心组件。
在 Linux 上,你可以直接通过 Docker 绕过整个管理程序层。它比任何管理程序都高效,是 Linux 上运行 Kubernetes 的推荐方法。
你可以继续安装上述任何管理程序。或者你想保持简单,只需要获取 VirtualBox。
文章的剩余部分,我们假设你正在使用 VirtualBox。别担心,即使你正在使用其他管理程序,区别也不会太大。
整篇文章,我在装有 Ubuntu 的机器上使用带有 Docker 驱动程序的
minikube完成。
安装了管理程序和容器化平台之后,就该安装 minikube 和 kubectl 程序了。
如果你使用 Mac 或 Windows,安装完 Docker Desktop 后 kubectl 就已经安装了。可在此处找到 Linux 的安装说明。
另外 minikube 也是必需要安装的,可以在 Mac 上使用 Homebrew,Windows 上使用 Chocolatey 来安装 minikube。可以在此处找到 Linux 的安装说明。
安装完成后,可以通过执行以下命令来测试是否安装成功:
minikube version
# minikube version: v1.12.1
# commit: 5664228288552de9f3a446ea4f51c6f29bbdd0e0
kubectl version
# Client Version: version.Info{Major:"1", Minor:"18", GitVersion:"v1.18.6", GitCommit:"dff82dc0de47299ab66c83c626e08b245ab19037", GitTreeState:"clean", BuildDate:"2020-07-16T00:04:31Z", GoVersion:"go1.14.4", Compiler:"gc", Platform:"darwin/amd64"}
# Server Version: version.Info{Major:"1", Minor:"18", GitVersion:"v1.18.3", GitCommit:"2e7996e3e2712684bc73f0dec0200d64eec7fe40", GitTreeState:"clean", BuildDate:"2020-05-20T12:43:34Z", GoVersion:"go1.13.9", Compiler:"gc", Platform:"linux/amd64"}
如果你已经为你的操作系统下载了正确的版本并且设置了正确路径,那么那你已经准备就绪啦。
正如我已经提到的,minikube 在本地计算机上的虚拟机(VM)中运行一个单节点 Kubernetes 集群。 我将在下一部分中更详细地解释集群和节点。
现在,可以理解为 minikube 使用你选择的管理程序创建常规 VM,并将其视为 Kubernetes 集群。
如果你在本节中遇到任何问题,请查看本文结尾处的答疑部分。
在启动 minikube 之前,必需正确设置管理程序才能使用。执行如下命令将 VirtualBox 设置为默认驱动程序:
minikube config set driver virtualbox
# ❗ These changes will take effect upon a minikube delete and then a minikube start
可以根据需要将 virtualbox 替换为 hyperv、 hyperkit 或者 docker。这个命令只需运行一次。
执行下面的命令启动 minikube:
minikube start
# ? minikube v1.12.1 on Ubuntu 20.04
# ✨ Using the virtualbox driver based on existing profile
# ? Starting control plane node minikube in cluster minikube
# ? Updating the running virtualbox "minikube" VM ...
# ? Preparing Kubernetes v1.18.3 on Docker 19.03.12 ...
# ? Verifying Kubernetes components...
# ? Enabled addons: default-storageclass, storage-provisioner
# ? Done! kubectl is now configured to use "minikube"
可以通过 minikube stop 命令来停止 minikube 。
Kubernetes 初体验
现在已经在本地上安装了 Kubernetes,是时候动手啦。在此示例中,会向本地集群部署一个非常简单的应用,并熟悉一下基础知识。
本节中会涉及到诸如 pod, service, 负载均衡等术语, 如果你没有搞懂他们,别急,我会在全景图小节中详细介绍它们。
如果你在上一小节已经启动了 minikube,那么就可以开始啦,否则你需要先启动它哦。启动 minikube 后,在终端执行下面的命令:
kubectl run hello-kube --image=fhsinchy/hello-kube --port=80
# pod/hello-kube created
你会立即看到 pod/hello-kube created 消息。 run 命令用来在 pod 中运行指定的容器映像。
Pods 就像是封装容器的盒子,执行以下命令确保 pod 已经成功创建并运行:
kubectl get pod
# NAME READY STATUS RESTARTS AGE
# hello-kube 1/1 Running 0 3m3s
你应该在 STATUS 列看到 Running 信息。如果看到类似 ContainerCreating 的信息,等待一两分钟,然后再次检查。
默认情况下,从集群外部无法访问 Pod。若要使其可访问,必需使用 service 使其暴露。运行 pod 后,执行下面的命令暴露 pod:
kubectl expose pod hello-kube --type=LoadBalancer --port=80
# service/hello-kube exposed
执行以下命令确保负载均衡服务已经成功创建:
kubectl get service
# NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
# hello-kube LoadBalancer 10.109.60.75 <pending> 80:30848/TCP 119s
# kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 7h47m
请确保在列表中可以看到 hello-kube 服务。现在已经有了一个公开的 pod 正在运行,执行下面的命令访问它。
minikube service hello-kube
# |-----------|------------|-------------|-----------------------------|
# | NAMESPACE | NAME | TARGET PORT | URL |
# |-----------|------------|-------------|-----------------------------|
# | default | hello-kube | 80 | http://192.168.99.101:30848 |
# |-----------|------------|-------------|-----------------------------|
# ? Opening service default/hello-kube in default browser...
默认的 web 浏览器应该会自动打开,显示类似如下的内容:

这是一个非常简单的 JavaScript 应用程序,使用了 vite 和一点 CSS。如果要了解刚才执行的命令,需要熟悉一下 Kubernetes 的架构。
Kubernetes 的架构
在 Kubernetes 的世界中,node 既可以是一台物理设备也可以是一台指定角色的虚拟机。这样的一组使用一个共享网络彼此通信的设备或者服务器的集合就叫做 集群(cluster)。

在本地设置中, minikube 是单节点的 Kubernetes 集群。因此 minikube 没有像上图的多个服务器,而是只有一台服务器同时充当主服务器和 node。

Kubernetes 集群中的每台服务器都会获得一个角色。有两种不同的角色:
- control-plane — 做出大部分必要的决定,并充当整个集群的大脑。它可以是单个服务器或者大型项目中的一组服务器。
- node — 负责运行工作负载,这些服务器通常由 control-plane 进行细微管理,并按照提供的说明执行各种任务。
集群中每个服务器都将具有一组特定的组件。这些组件的数量和类型根据服务器在集群中承担的角色而有所不同。这意味着节点不必包含 control plane 中的所有的组件。
在接下来的小节里,将更详细的了解组成 Kubernetes 集群的各个组件。
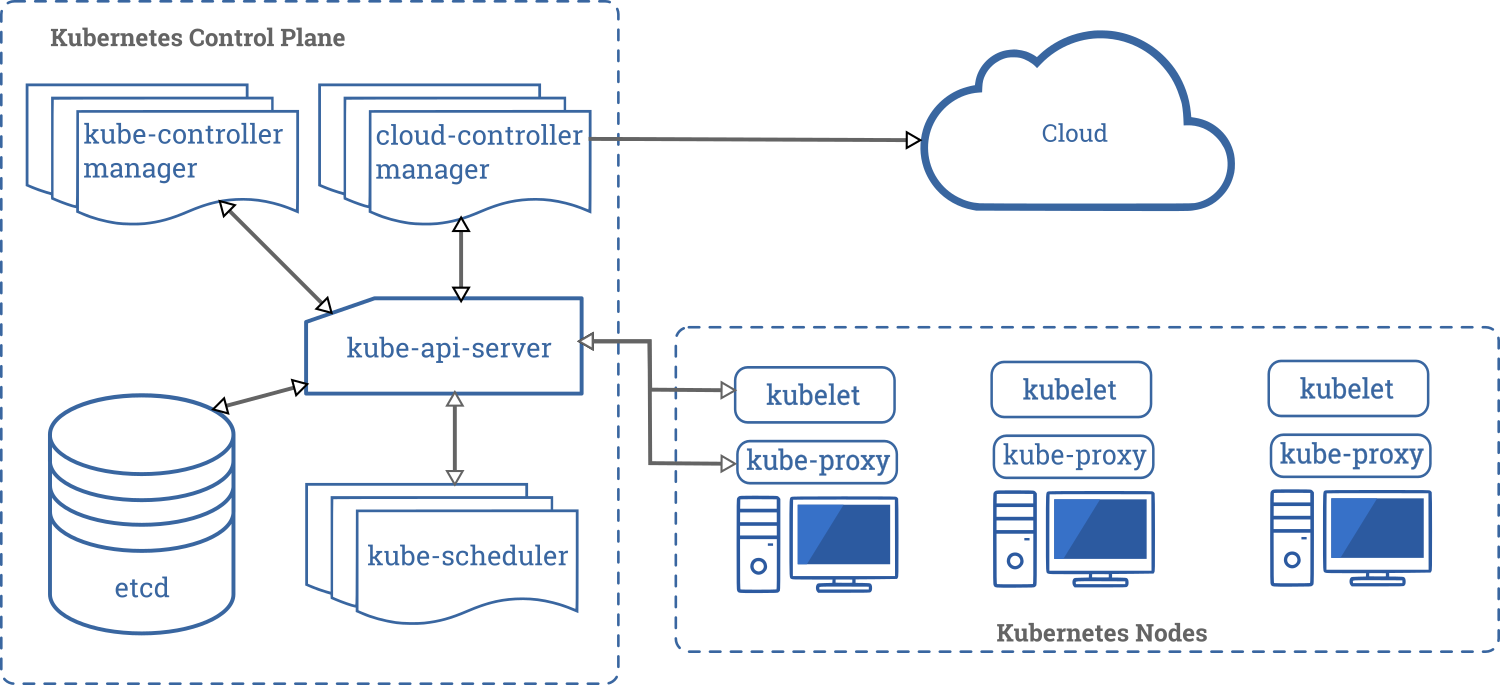
Control Plane 组件
Kubernetes 集群中的 control plane 由如下五个组件组成:
- kube-api-server: 这是 Kubernetes control plane 的入口,负责验证和处理使用客户端库(如
kubectl程序)传递的请求。 - etcd: 这是一个分布式键值存储,是整个集群的唯一键值来源。它保存了配置数据和集群的状态信息。etcd 是一个开源项目,由来自 Red Hat 的人开发。 该项目的源代码托管在 etcd-io/etcd GitHub 仓库中。
- kube-controller-manager: Kubernetes 中的 controller 负责控制集群的状态。当请求 Kubernetes 集群内容时,controller 会做出响应。
kube-controller-manager是通过一个进程管理所有 controller 进程的程序。 - kube-scheduler: 调度就是根据节点的可用资源和任务需要的资源分配任务。
kube-scheduler组件执行 Kubernetes 的任务调度以确保集群中所有的服务都不过载。 - cloud-controller-manager: 在真实的云环境中,此组件允许你通过 (GKE/EKS) API 连接集群。这样,与该云平台交互的组件就和与集群交互的组件隔离开了。在
minikube这一类的组件中,该组件并不存在。
Node 组件
与 control plane 相比,node 的组件数量非常少,如下:
- kubelet: 该服务充当 control plane 和集群中每个节点之间的网关。从 control plane 到节点的每条指令都通过此服务。它还与
etcd存储区进行交互以保持状态信息的更新。 - kube-proxy: 这个小服务运行在每个节点上,并为其维护网络规则。到达集群内部服务的任何网络请求都将通过此服务。
- Container Runtime: Kubernetes 是一个容器编排工具,因此它最终在容器中运行应用程序。这意味着每个节点都需要一个容器环境,比如 Docker、rkt 或者 cri-o。
Kubernetes 对象
摘自 Kubernetes 文档 —
"在 Kubernetes 系统中,Kubernetes 对象 是持久化的实体。 Kubernetes 使用这些实体去表示整个集群的状态。特别地,它们描述了如下信息:
- 哪些容器化应用在运行(以及在哪些节点上)
- 可以被应用使用的资源
- 关于应用运行时表现的策略,比如重启策略、升级策略,以及容错策略
当创建 Kubernetes 对象时,实际上是在告诉 Kubernetes 系统这个对象应该存在,任何时候 Kubernetes 系统都应该确保该对象的’
运行。
Pods
摘自 Kubernetes 文档 —
"Pod 是可以在 Kubernetes 中创建和管理的、最小的可部署的计算单元"。
pod 通常封装一个或多个紧密相关的容器,共享一个生命周期和消耗性资源。

尽管一个 pod 可以容纳多个容器,但是你不应该随意的把容器放到 pod 中。pod 中的容器必须紧密相关,以至于可以将它们视为单个应用程序。
例如,后端的 API 可能依赖数据库,但这并不意味着需要把他们都放在同一个容器中。在整篇文章中,不会有任何 pod 放置多个容器。
通常,你不应该直接管理 pod。相反,你应该使用可以提供更好的可管理的高级对象。将在后面的部分中介绍这些更高级别的对象。
Services
摘自 Kubernetes 文档 —
"Kubernetes 的 service 是将运行在一组 Pods 上的应用程序公开为网络服务的抽象方法"。
Kubernetes pods 是非永久性资源。他们被创造出来,即使过一段时间被销毁了,也不会被回收。
相反,新的 pod 取代了旧的 pod。一些更高级别的对象甚至能动态创建和销毁 pod。
在创建每个 pod 时,会为其分配一个新的 IP 地址。但是对于可以创建、销毁和组合多个 pod 的高级对象而言,在此刻运行的 pod 集合可能与稍后运行的 pod 集合并不相同。
这就导致了一个问题:如果集群中的某些 pod 依赖于集群中的另一组 pod,怎样定位并跟踪彼此的 IP 地址呢?
根据 Kubernetes 文档 —
"Kubernetes Service 定义了这样一种抽象:逻辑上的一组 Pod,一种可以访问它们的策略 —— 通常称为微服务"。
本质上讲,service 将执行相同功能的多个 pod 组合在一起,并将它们显示为单个实体。
这样一来,如何跟踪多个 Pod 的问题就消失了,因为单个 service 现在充当了所有 pod 的沟通器。
在 hello-kube 示例中,创建了一个 LoadBalancer 类型的服务,该服务可以将来自集群外部的请求连接到集群内部运行的 pod 上。

无论何时,在需要授予另一个应用程序或者集群外部某个对象一个或多个 pod 的访问权限时,就应该创建一个 service。
比如,如果你有一组运行 web 服务的 pod,需要从 internet 进行访问,那么就必需用 service 提供必要的抽象。
全景图
现在你已经对 Kubernetes 的各个组件有了适当的了解,下图描述了他们是如何协作的:
https://kubernetes.io/docs/concepts/overview/components/
在解释各个细节之前,先看一下 Kubernetes 文档 --
"操作 Kubernetes 对象 —— 无论是创建、修改,或者删除 —— 需要使用 Kubernetes API。 比如,当使用
kubectl命令行接口时,CLI 会执行必要的 Kubernetes API 调用。"
运行的第一个命令是 run 命令,如下:
kubectl run hello-kube --image=fhsinchy/hello-kube --port=80
run 命令负责运行指定的镜像创建新的 pod。运行此命令后,Kubernetes 集群会执行下面的事件:
kube-api-server组件接收请求,对其进行校验并进行处理。kube-api-server接着与节点上的kubelet进行通信,并提供创建 pod 所需的指令。kubelet组件开始启动运行 pod,并且在etcd存储中保持状态的更新。
run 命令的通用语法如下:
kubectl run <pod name> --image=<image name> --port=<port to expose>
可以在 pod 内运行任何有效的容器映像。fhsinchy/hello-kube Docker 镜像包含了一个非常简单的 JavaScript 应用程序,该应用程序在容器内部的 80 端口上运行。 --port=80 选项允许容器从内部暴露 80 端口。

新创建的 Pod 运行在 minikube 集群内部,并且无法从外部访问。要公开容器并使其可用,运行的第二个命令如下:
kubectl expose pod hello-kube --type=LoadBalancer --port=80
expose 命令负责创建类型为 LoadBalancer Kubernetes service,该服务允许用户访问 Pod 中运行的应用程序。
和 run 命令一样, expose 命令的执行需要在集群内部运行相似的步骤。在这里, kube-api-server 向 kubelet 组件提供了创建 service (而不是 pod)所需的指令。
expose 命令的通用语法如下:
kubectl expose <resource kind to expose> <resource name> --type=<type of service to create> --port=<port to expose>
对象类型可以是任意合法的 Kubernetes 对象类型。名称必需和要暴露的对象名称匹配。
--type 表示所需的 service 类型。在内部或外部网络中一共有四种不同的 service 类型。
最后, --port 是要从容器中暴露的端口号。

创建完 service 后,最后一件事就是访问在 pod 的应用程序。为此,需要执行如下命令:
minikube service hello-kube
和之前的命令不同 ,最后一个命令没有用 kube-api-server。它使用 minikube 和本地集群通讯。 minikube 的 service 命令会返回给定服务的完整 URL。
当使用 --port=80 选项创建 hello-kube 容器时,Kubernetes 会在容器内暴露 80 端口,但是无法在集群外部访问它。
接着,使用 --port=80 选项创建 LoadBalancer 服务,它将 80 端口从该容器映射到本地系统中的任意端口,从而可以从集群外部访问它。
在我的系统上, service 命令返回 pod 的 URL 192.168.99.101:30848。该 URL 中的 IP 实际上是 minikube 虚拟机的真实 IP。可以通过下面的命令来验证:
minikube ip
# 192.168.99.101
可以通过如下命令验证 30848 端口是否指向 pod 内部的 80 端口:
kubectl get service hello-kube
# NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
# hello-kube LoadBalancer 10.109.60.75 <pending> 80:30848/TCP 119s
在 PORT(S) 列上,可以看到 80 端口实际上映射到本地系统的 30484 端口。因此,无需运行 service 命令,只需找到 IP 和端口号,然后就可以在浏览器内访问 hello-kube 应用程序。

目前集群的状态如下所示:

如果你了解 Docker,那么你可能觉得使用 service 来公开 pod 有点太麻烦了。
但是当你处理涉及多个 pod 的实例时,你就会了解 Kubernetes 这么做的便利了。
清除 Kubernetes 相关资源
现在已经了解如何创建 pod 和 service 之类的 Kubernetes 资源,现在来学习如何清除它们。也就是删除它们。
执行 kubectl 的 delete 命令来删除资源,用法如下:
kubectl delete <resource type> <resource name>
使用下面的命令删除名为 hello-kube 的 pod:
kubectl delete pod hello-kube
# pod "hello-kube" deleted
使用下面的命令删除名为 hello-kube 的 service:
kubectl delete service hello-kube
# service "hello-kube" deleted
或者(现在不可用)使用 delete 命令的 --all 选项来一次性删除所有此类对象。该选项的通用语法如下:
kubectl delete <object type> --all
如果要删除所有的 pod 和 service,依次执行 kubectl delete pod --all 和kubectl delete service --all。
声明式部署方法
坦白讲,你在上一节看到的 hello-kube 例子并不是部署 Kubernetes 的最佳方式。
在之前章节采用的是交互式途径(imperative approach),这意味着你必须手动逐个执行每个命令。采用交互式方法无法很好的工程化。
使用 Kubernetes 进行部署的理想方式是声明式途径(declarative approach),作为开发人员,只需让 Kubernetes 知道服务需要达到的状态,其余的 Kubernetes 会搞定。
在本节中,将会使用声明式部署相同的 hello-kube 应用程序。
如果你尚未克隆上面链接的代码仓库,请立即进行操作。
克隆完毕后,进入 hello-kube 目录,该目录包含 hello-kube 应用程序的代码以及用户构建镜像的 Dockerfile 。
├── Dockerfile
├── index.html
├── package.json
├── public
└── src
2 directories, 3 files
JavaScript 代码位于 src 文件夹下,无需关注,你应该看一下 Dockerfile,了解一下计划部署。Dockerfile 文件内容如下:
FROM node as builder
WORKDIR /usr/app
COPY ./package.json ./
RUN npm install
COPY . .
RUN npm run build
EXPOSE 80
FROM nginx
COPY --from=builder /usr/app/dist /usr/share/nginx/html
如你所见,这是一个多阶段构建(multi-staged build)。
- 第一阶段使用
node作为基本镜像,然后将 JavaScript 应用程序编译为生产状态。 - 第二阶段复制第一阶段生成的文件,并将其粘贴到默认的 NGINX 文档根目录中。这里假设第二阶段的基本镜像是
nginx,会把第一阶段构建的文件运行在 80 端口(nginx 默认端口)。
要在 Kubernetes 上部署应用,需要找到一种方式把镜像运行在容器里,并使其能在外部世界通过 80 端口访问。
编写你的第一套配置
在声明式方式中,无需在终端中发送单个命令,只需在 YAML 文件中写下必要的配置,然后将其提供给 Kubernetes 即可。
在 hello-kube 工程目录下,创建另一个名为 k8s 的目录,k8s 是 k(ubernete = 8 个字符)s 的缩写。
文件夹名不必一定是 k8s,可以任意命名。
甚至没有必要将其放在项目目录中,这些配置文件可以放在计算机中的任何位置,因为这些配置与项目源代码无关。
在 k8s 目录中,创建一个名为 hello-kube-pod.yaml 的新文件。先看一下所有的代码,后面会逐行解释。文件内容如下:
apiVersion: v1
kind: Pod
metadata:
name: hello-kube-pod
labels:
component: web
spec:
containers:
- name: hello-kube
image: fhsinchy/hello-kube
ports:
- containerPort: 80
每个有效的 Kubernetes 配置文件都有四个必填字段。如下:
apiVersion: 创建对象使用的 Kubernetes API 版本。该值可能会根据你创建的对象的类型而变化。对于Pod的创建,所需的版本是v1。kind: 创建的对象的类型。Kubernetes 中有许多种对象。本文介绍了很多对象,目前只需知道要创建的对象是Pod即可。metadata: 对象的唯一标识数据。在此字段下,可以有name、labels、annotation等信息。当使用kubectl命令时metadata.name会显示在终端上。metadata.labels字段下的键值对不必一定是components: web,可以指定任意 label 比如app: hello-kube。在接下来创建LoadBalancerservice 时会使用该值作为选择器。spec: 包含对象希望达成的状态。spec.containers子字段包含将要运行在Pod内的容器信息。spec.containers.name是节点内的容器运行时分配给新创建容器的值。spec.containers.image是用来创建容器的镜像。spec.containers.ports字段是各种端口的配置。containerPort: 80表示容器对外暴露的端口是 80。
现在使用 apply 命令将这个文件提供给 Kubernetes,用法如下:
kubectl apply -f <configuration file>
如下命令 apply 了名为 hello-kube-pod.yaml 的配置文件:
kubectl apply -f hello-kube-pod.yaml
# pod/hello-kube-pod created
执行以下命令以确保 Pod 已经成功启动并且正在运行:
kubectl get pod
# NAME READY STATUS RESTARTS AGE
# hello-kube 1/1 Running 0 3m3s
在 STATUS 列中能看到 Running。如果显示的是类似 ContainerCreating 的内容,请等待一两分钟后再试。
当 Pod 启动并运行后,就可以开始写 LoadBalancer service 的配置文件了。
在 k8s 路径下创建一个名为 hello-kube-load-balancer-service.yaml 的文件内容如下:
apiVersion: v1
kind: Service
metadata:
name: hello-kube-load-balancer-service
spec:
type: LoadBalancer
ports:
- port: 80
targetPort: 80
selector:
component: web
和之前的配置文件一样,apiVersion、kind 和 metadata 字段作用相同。如你所见,metadata 内没有 labels 字段,因为 service 使用 labels 选择其它对象,而其它对象无需选择 service。
记住,service 为其他对象设置了访问策略,而其它对象无需为 service 设置访问策略。
在 spec 字段内可以看到一组新的值。和 Pod 不同,service 有四种不同的类型,他们是 ClusterIP、 NodePort、 LoadBalancer 和ExternalName。
在此例中,使用的是 LoadBalancer 类型,这是把 service 暴露给集群外的标准方法。该服务会给你提供一个 IP 地址,可以使用该 IP 地址连接到集群内运行的应用程序。

LoadBalancer 类型需要两个端口值才能正常工作,在 ports 字段下,port 值用于访问 pod 本身,其值可以是任意值。
targetPort 值是容器内部的值,必需要与容器内部的 port 一致。
正如之前所说,hello-kube 应用运行在容器内部的 80 端口上,已经在 Pod 配置文件中暴露了该端口,因此 targetPort 的值应该为 80。
selector 字段用于标识将要连接该 service 的对象。component: web 键值对必须与 Pod 配置文件中的 labels 字段相匹配。如果你之前在配置文件里使用了其它的键值对如 app: hello-kube ,那么就改成你的键值。
在次使用 apply 命令将这个文件提供给 Kubernetes。文件名为hello-kube-load-balancer-service.yaml, 命令如下:
kubectl apply -f hello-kube-load-balancer-service.yaml
# service/hello-kube-load-balancer-service created
执行以下命令以确保负载均衡器已经成功创建:
kubectl get service
# NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
# hello-kube-load-balancer-service LoadBalancer 10.107.231.120 <pending> 80:30848/TCP 7s
# kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 21h
确保在列表中能看到 hello-kube-load-balancer-service。现在你已经运行了一个公有的 pod,执行下面的命令直接进行访问:
minikube service hello-kube-load-balancer-service
# |-----------|----------------------------------|-------------|-----------------------------|
# | NAMESPACE | NAME | TARGET PORT | URL |
# |-----------|----------------------------------|-------------|-----------------------------|
# | default | hello-kube-load-balancer-service | 80 | http://192.168.99.101:30848 |
# |-----------|----------------------------------|-------------|-----------------------------|
# ? Opening service default/hello-kube-load-balancer in default browser...
默认的浏览器应该会自动打开,如下所示:

也可以将两个文件一起提供,如下所示,将文件名替换成目录名即可:
kubectl apply -f k8s
# service/hello-kube-load-balancer-service created
# pod/hello-kube-pod created
请确保终端在 k8s 目录的父目录中。
如果位于 k8s 目录中,可以使用点 (.) 引用当前目录。应用批量配置时,最好提前清除之前创建的资源,以防发生冲突。
声明式方法是使用 Kubernetes 的理想方法,当然有一些例外情况,本文结尾会介绍。
Kubernetes 控制面板
在上一节中,使用 delete 命令清除了 Kubernetes 对象。
在本节中,会引入控制面板。Kubernetes 控制面板是一个图形用户界面,用于管理工作负载、service 等。
在终端中执行以下命令启动 Kubernetes 控制面板:
minikube dashboard
# ? Verifying dashboard health ...
# ? Launching proxy ...
# ? Verifying proxy health ...
# ? Opening http://127.0.0.1:52393/api/v1/namespaces/kubernetes-dashboard/services/http:kubernetes-dashboard:/proxy/ in your default browser...
控制面板应该会在浏览器中自动打开:

控制面板界面很直观,你可以快速上手。虽然创建、管理和删除对象都能从控制面板进行,但是本文其余部分还是会使用 cli 来操作。
在 Pods 列表中,可以使用右边的三个点菜单的 Delete 来删除 Pod。LoadBalancer service 也可以如此操作,实际上 Services 列表就位于 Pods 列表后。
可以按 Ctrl + C 组合键或者关闭终端窗口来停止控制面板服务。
使用多容器应用程序
目前为止,已经使用了单个容器运行了应用程序。
在本节中,将会使用两个容器组成应用程序。你还会学习到 Deployment、ClusterIP、 PersistentVolume、PersistentVolumeClaim 以及一些调试技巧。
将使用的服务是一个具备完整 CRUD 功能的简单的基于 express 的日记 API。该应用使用 PostgreSQL 数据库。因此不仅需要部署应用程序,还需要建立应用程序和数据库服务的内部网络连接。
该应用程序的代码位于项目仓库的 notes-api 目录中。
.
├── api
├── docker-compose.yaml
└── postgres
应用程序代码位于 api 目录中,postgres 目录包含了创建 postgres 镜像的 Dockerfile。 docker-compose.yaml 文件包含使用 docker-compose 运行应用程序的配置文件。
就像上一个项目一样,可以查看每个 service 单独的 Dockerfile,以了解应用程序是如何在容器中运行的。
也可以只检查 docker-compose.yaml 并用它来规划 Kubernetes 部署。
version: "3.8"
services:
db:
build:
context: ./postgres
dockerfile: Dockerfile.dev
environment:
POSTGRES_PASSWORD: 63eaQB9wtLqmNBpg
POSTGRES_DB: notesdb
api:
build:
context: ./api
dockerfile: Dockerfile.dev
ports:
- 3000:3000
volumes:
- /usr/app/node_modules
- ./api:/usr/app
environment:
DB_CONNECTION: pg
DB_HOST: db
DB_PORT: 5432
DB_USER: postgres
DB_DATABASE: notesdb
DB_PASSWORD: 63eaQB9wtLqmNBpg
查看 api 服务定义,应该可以看到服务运行在内部容器的 3000 端口。它还需要一堆环境变量才能正常运行。
可以忽略 volumes,它在开发环境是必需的,并且构建配置是只针对于 Docker。因此可以保留 Kubernetes 配置文件几乎不变,如下:
- Port 映射 – 必需从容器公开相同的端口。
- 环境变量 – 这些变量在所有的环境中都是相同的(尽管值将发生变化)。
db 服务更简单,它只是一堆环境变量。甚至可以用官方的 postgres 镜像代替自定义的镜像。
使用自定义镜像的好处是数据库实例可以附带预先创建的 notes 表。
该表对于应用程序是必需的,如果查看 postgres/docker-entrypoint-initdb.d 目录,会看到一个名为 notes.sql 的文件,该文件用于在初始化期间创建数据库。
部署计划
和之前的项目部署不同,该项目将变的更加复杂。
在这个项目中,将会创建三个 notes API 实例。这三个实例使用 LoadBalancer service 暴露在集群外面。

除了这个实例,还会有一个 PostgreSQL 系统实例。notes API 应用程序的三个实例都使用 ClusterIP service 和数据库实例通讯。
ClusterIP service 是另外一种 Kubernetes service,它在集群内部使应用可见。也就是说即使没有外部流量,应用程序也可以使用 ClusterIP service。

在此项目中,必需仅通过 Notes API 访问数据库,因此在集群中公开数据库服务是一个理想的选择。
上一节中已经提起到,不应该直接创建 pod。因此,在此项目中使用 Deployment 而不是 Pod。
复制 Controllers、Replica Sets 以及 Deployments
根据 Kubernetes 文档 -
"在 Kubernetes 中,控制器通过监控集群 的公共状态,并致力于将当前状态转变为期望的状态。控制回路(Control Loop)是一个非终止回路,用于调节系统状态。"
ReplicationController 可以很轻松的创建多个副本。当创建所需的副本后,控制器将保持当前状态。
如果过了一段时间你决定减少副本的数量,那么 ReplicationController 会立刻清除多余的 pods。
否则,如果副本的数量少于预期数量(也许一些 pod 已经崩溃),ReplicationController 会创建新的副本以达到所需的状态。
尽管 ReplicationController 很强大,但目前已不是创建副本的推荐方式。它已经被较新的 API ReplicaSet 取代。
ReplicaSet 除了提供了更多选择外,ReplicationController 和 ReplicaSet 完成的几乎是同一件事。
拥有更多的选择器是件好事,但是更棒的是,能在发布和回滚更新方面具有更大的灵活性。这就该轮到另一个 Kubernetes API Deployment 出场了。
Deployment 就像是 ReplicaSet API 的一个扩展。Deployment 不但允许你立即创建新副本,还允许使用一个或两个 kubectl 命令发布或回滚更新。
| REPLICATIONCONTROLLER | REPLICASET | DEPLOYMENT |
|---|---|---|
| 可以轻松创建多个 pod | 可以轻松创建多个 pod | 可以轻松创建多个 pod |
| Kubernetes 中的原始复制方法 | 更灵活的选择器 | 扩展自 ReplicaSets,可以轻松更新和回滚 |
在这个项目里,会使用 Deployment 来维护应用程序实例。
创建你的第一个部署
首先,为 Notes API 部署编写配置文件,在 notes-api 目录中创建一个 k8s 目录。
在该目录中,创建一个名为 api-deployment.yaml 的文件,内容如下:
apiVersion: apps/v1
kind: Deployment
metadata:
name: api-deployment
spec:
replicas: 3
selector:
matchLabels:
component: api
template:
metadata:
labels:
component: api
spec:
containers:
- name: api
image: fhsinchy/notes-api
ports:
- containerPort: 3000
在此文件中,apiVersion、 kind、 metadata 和 spec 字段作用与之前的项目相同。与上一个文件相比,不一样的地方如下:
- 创建 pod 时,
apiVersion的值是v1。但是创建部署时,需要的版本是apps/v1。Kubernetes API 的版本有时会有些混乱,你可能会有些一头雾水。可以阅读一下官网文档对DeploymentYAML 文件的介绍。 spec.replicas定义了同时运行的副本数量。将此值设置为 3 意味着希望 Kubernetes 同时运行三个应用实例。- 在
spec.selector中,可以让Deployment知道要控制那些 pods。之前已经提到,Deployment是ReplicaSet的扩展,可以控制 Kubernetes 对象。将selector.matchLabels设置为component: api意味着Deployment会控制 label 为component: api的 pods。这行代码的意思就是让 Kubernetes 知道你希望Deployment来控制 label 为component: api的 pods。 spec.template是用于配置 pod 的模板,它与之前的配置文件几乎相同。
现在,要查看此配置效果,和之前一样 apply 该文件:
kubectl apply -f api-deployment.yaml
# deployment.apps/api-deployment created
执行下面的命令确保 Deployment 已经成功创建:
kubectl get deployment
# NAME READY UP-TO-DATE AVAILABLE AGE
# api-deployment 0/3 3 0 2m7s
如果查看 READY 列,会看到 0/3。这意味着容器尚未创建,等待几分钟,然后在试一次。
kubectl get deployment
# NAME READY UP-TO-DATE AVAILABLE AGE
# api-deployment 0/3 3 0 28m
坦白讲,我已经等了将近半个小时,pod 还未准备就绪。API 本身只有几百 kb。这种规模的部署不应该花这么长的时间,这意味着有问题,我们来解决它。
调试 Kubernetes 资源
开始之前,首先回到起点。get 命令是一个很基础的命令。
get 命令可以打印一张包含一个或多个 Kubernetes 资源重要信息的表。用法如下:
kubectl get <resource type> <resource name>
在终端执行如下代码,在 api-deployment 上运行 get 命令:
kubectl get deployment api-deployment
# NAME READY UP-TO-DATE AVAILABLE AGE
# api-deployment 0/3 3 0 15m
可以省略 api-deployment 以获取所有可用的部署列表。也可以在配置文件上使用 get 命令。
可以使用如下命令获取有关 api-deployment.yaml 文件中描述的部署信息:
kubectl get -f api-deployment
# NAME READY UP-TO-DATE AVAILABLE AGE
# api-deployment 0/3 3 0 18m
默认情况下,get 命令显示的信息非常少,可以使用 -o 选项获取更多信息。
-o 选项设置 get 命令的输出格式,可以使用 wide 输出格式查看更详细信息。
kubectl get -f api-deployment.yaml
# NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
# api-deployment 0/3 3 0 19m api fhsinchy/notes-api component=api
现在列表包含了更多的信息,可以在官方文档了解有关 get 命令的选项。
老实说,仅仅是运行 Deploymen 的 get 命令没啥意思。还需要获取更底层资源的信息。
看一下 pod 列表,看看里面都有啥东西:
kubectl get pod
# NAME READY STATUS RESTARTS AGE
# api-deployment-d59f9c884-88j45 0/1 CrashLoopBackOff 10 30m
# api-deployment-d59f9c884-96hfr 0/1 CrashLoopBackOff 10 30m
# api-deployment-d59f9c884-pzdxg 0/1 CrashLoopBackOff 10 30m
现在发现了一些有用的东西。所有的 pods 都有一个值为 CrashLoopBackOff 的 STATUS。之前只接触过 ContainerCreating 和 Running 状态。你可能还会在 CrashLoopBackOff 处看到 Error。
看一下 RESTARTS 列,会发现 pod 已经重启 10 多次了,着意味着因为某些原因, pod 启动失败了。
现在,要查看一个 pod 的更详细信息,可以使用另一个名为 describe 的命令。它和 get 命令很像,用法如下:
kubectl get <resource type> <resource name>
执行下面的命令查看 api-deployment-d59f9c884-88j4 pod 的详细信息:
kubectl describe pod api-deployment-d59f9c884-88j45
# Name: api-deployment-d59f9c884-88j45
# Namespace: default
# Priority: 0
# Node: minikube/172.28.80.217
# Start Time: Sun, 09 Aug 2020 16:01:28 +0600
# Labels: component=api
# pod-template-hash=d59f9c884
# Annotations: <none>
# Status: Running
# IP: 172.17.0.4
# IPs:
# IP: 172.17.0.4
# Controlled By: ReplicaSet/api-deployment-d59f9c884
# Containers:
# api:
# Container ID: docker://d2bc15bda9bf4e6d08f7ca8ff5d3c8593655f5f398cf8bdd18b71da8807930c1
# Image: fhsinchy/notes-api
# Image ID: docker-pullable://fhsinchy/notes-api@sha256:4c715c7ce3ad3693c002fad5e7e7b70d5c20794a15dbfa27945376af3f3bb78c
# Port: 3000/TCP
# Host Port: 0/TCP
# State: Waiting
# Reason: CrashLoopBackOff
# Last State: Terminated
# Reason: Error
# Exit Code: 1
# Started: Sun, 09 Aug 2020 16:13:12 +0600
# Finished: Sun, 09 Aug 2020 16:13:12 +0600
# Ready: False
# Restart Count: 10
# Environment: <none>
# Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from default-token-gqfr4 (ro)
# Conditions:
# Type Status
# Initialized True
# Ready False
# ContainersReady False
# PodScheduled True
# Volumes:
# default-token-gqfr4:
# Type: Secret (a volume populated by a Secret)
# SecretName: default-token-gqfr4
# Optional: false
# QoS Class: BestEffort
# Node-Selectors: <none>
# Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s
# node.kubernetes.io/unreachable:NoExecute for 300s
# Events:
# Type Reason Age From Message
# ---- ------ ---- ---- -------
# Normal Scheduled <unknown> default-scheduler Successfully assigned default/api-deployment-d59f9c884-88j45 to minikube
# Normal Pulled 2m40s (x4 over 3m47s) kubelet, minikube Successfully pulled image "fhsinchy/notes-api"
# Normal Created 2m40s (x4 over 3m47s) kubelet, minikube Created container api
# Normal Started 2m40s (x4 over 3m47s) kubelet, minikube Started container api
# Normal Pulling 107s (x5 over 3m56s) kubelet, minikube Pulling image "fhsinchy/notes-api"
# Warning BackOff <invalid> (x44 over 3m32s) kubelet, minikube Back-off restarting failed container
整个输出中最有用的部分是 Events 部分,如下:
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled <unknown> default-scheduler Successfully assigned default/api-deployment-d59f9c884-88j45 to minikube
Normal Pulled 2m40s (x4 over 3m47s) kubelet, minikube Successfully pulled image "fhsinchy/notes-api"
Normal Created 2m40s (x4 over 3m47s) kubelet, minikube Created container api
Normal Started 2m40s (x4 over 3m47s) kubelet, minikube Started container api
Normal Pulling 107s (x5 over 3m56s) kubelet, minikube Pulling image "fhsinchy/notes-api"
Warning BackOff <invalid> (x44 over 3m32s) kubelet, minikube Back-off restarting failed container
从这些事件中,可以看到容器镜像已经成功 pulled,容器也已经创建,但是显然从 Back-off restarting failed container 中可以看出该容器无法启动。
describe 命令和 get 命令类似,并且具有相同的选项。
可以省略 api-deployment-d59f9c884-88j45 名字以获取所有 pods 的信息。或者也可以使用 -f 选项将配置文件传入命令。访问官方文档了解更多信息。
既然已经知道了是容器出了问题,那么就让我们到容器层面看看到底出了什么问题吧。
从 Pods 获取容器日志
还有另一个名为 logs 的 kubectl 命令,可以从容器内部获取容器的日志,用法按如下:
kubectl logs <pod>
使用如下命令 api-deployment-d59f9c884-88j45 查看 pod 内的日志:
kubectl logs api-deployment-d59f9c884-88j45
# > api@1.0.0 start /usr/app
# > cross-env NODE_ENV=production node bin/www
# /usr/app/node_modules/knex/lib/client.js:55
# throw new Error(knex: Required configuration option 'client' is missing.);
^
# Error: knex: Required configuration option 'client' is missing.
# at new Client (/usr/app/node_modules/knex/lib/client.js:55:11)
# at Knex (/usr/app/node_modules/knex/lib/knex.js:53:28)
# at Object.<anonymous> (/usr/app/services/knex.js:5:18)
# at Module._compile (internal/modules/cjs/loader.js:1138:30)
# at Object.Module._extensions..js (internal/modules/cjs/loader.js:1158:10)
# at Module.load (internal/modules/cjs/loader.js:986:32)
# at Function.Module._load (internal/modules/cjs/loader.js:879:14)
# at Module.require (internal/modules/cjs/loader.js:1026:19)
# at require (internal/modules/cjs/helpers.js:72:18)
# at Object.<anonymous> (/usr/app/services/index.js:1:14)
# npm ERR! code ELIFECYCLE
# npm ERR! errno 1
# npm ERR! api@1.0.0 start: cross-env NODE_ENV=production node bin/www
# npm ERR! Exit status 1
# npm ERR!
# npm ERR! Failed at the api@1.0.0 start script.
# npm ERR! This is probably not a problem with npm. There is likely additional logging output above.
这正是出问题的地方,看起来是 knex.js 库缺少一个必要的值,导致程序启动失败。可以从官方文档了解更多关于 logs 命令的信息。
出现这个错误主要是因为在部署定义中缺少了一些必需的环境变量。
如果在看一下 docker-compose.yaml 文件中的 api service 定义,应该会看到类似如下的内容:
api:
build:
context: ./api
dockerfile: Dockerfile.dev
ports:
- 3000:3000
volumes:
- /usr/app/node_modules
- ./api:/usr/app
environment:
DB_CONNECTION: pg
DB_HOST: db
DB_PORT: 5432
DB_USER: postgres
DB_DATABASE: notesdb
DB_PASSWORD: 63eaQB9wtLqmNBpg
应用程序与数据库进行连接需要这些环境变量。所以,把这些数据添加到部署配置中就可以解决该问题。
环境变量
给 Kubernetes 配置文件添加环境变量非常简单。打开 api-deployment.yaml 文件并按如下更新内容:
apiVersion: apps/v1
kind: Deployment
metadata:
name: api-deployment
spec:
replicas: 3
selector:
matchLabels:
component: api
template:
metadata:
labels:
component: api
spec:
containers:
- name: api
image: fhsinchy/notes-api
ports:
- containerPort: 3000
# these are the environment variables
env:
- name: DB_CONNECTION
value: pg
containers.env 字段包含所有的环境变量,如果细心你会发现我还没有给 docker-compose.yaml 文件添加所有的环境变量,我只添加了一个。
DB_CONNECTION 表示应用正在使用 PostgreSQL 数据库,添加这个变量就可以解决上述问题。
现在通过执行下面的命令在此 apply 配置文件:
kubectl apply -f api-deployment.yaml
# deployment.apps/api-deployment configured
这次显示资源已经被 configured。这就是 Kubernetes 厉害的地方,apply 配置文件可以立即生效。
现在在次使用 get 命令确保一切运行正常。
kubectl get deployment
# NAME READY UP-TO-DATE AVAILABLE AGE
# api-deployment 3/3 3 3 68m
kubectl get pod
# NAME READY STATUS RESTARTS AGE
# api-deployment-66cdd98546-l9x8q 1/1 Running 0 7m26s
# api-deployment-66cdd98546-mbfw9 1/1 Running 0 7m31s
# api-deployment-66cdd98546-pntxv 1/1 Running 0 7m21s
三个 pod 都在运行,并且 Deployment 也运行良好。
创建数据库部署
既然 API 已经启动并且运行,是时候为数据库实例编写配置了。
在 k8s 目录中另创建一个名为 postgres-deployment.yaml 的文件,文件内容如下:
apiVersion: apps/v1
kind: Deployment
metadata:
name: postgres-deployment
spec:
replicas: 1
selector:
matchLabels:
component: postgres
template:
metadata:
labels:
component: postgres
spec:
containers:
- name: postgres
image: fhsinchy/notes-postgres
ports:
- containerPort: 5432
env:
- name: POSTGRES_PASSWORD
value: 63eaQB9wtLqmNBpg
- name: POSTGRES_DB
value: notesdb
配置本身与上一次非常相似,我就不详细解释了,根据目前学到的知识你应该可以了解。
PostgreSQL 默认运行在 5432 端口上,运行 postgres 容器需要 POSTGRES_PASSWORD 变量。该密码也会用于 API 连接数据库。
POSTGRES_DB 变量是可选的,但是在该项目里是必需的,否则会初始化失败。
可以在 Docker Hub 页面上了解 postgres Docker 镜像的更多信息。在此项目中,化繁为简,副本数量设置为 1。
执行以下命令 apply 这个文件:
kubectl apply -f postgres-deployment.yaml
# deployment.apps/postgres-deployment created
通过 get 命令确保 pod 已经正常部署和运行:
kubectl get deployment
# NAME READY UP-TO-DATE AVAILABLE AGE
# postgres-deployment 1/1 1 1 13m
kubectl get pod
# NAME READY STATUS RESTARTS AGE
# postgres-deployment-76fcc75998-mwnb7 1/1 Running 0 13m
尽管 pod 已经成功部署和运行,但是数据库部署还是有很大的问题。
如果你以前使用过数据库系统,应该知道数据库是把数据存储在文件系统中。目前,数据库部署如下:

postgres 容器由 pod 封装,数据保留在容器内部的文件系统中。
现在,如果由于某种原因,容器崩溃或者封装容器的 pod 发生故障,则保存在文件系统的所有数据都将丢失。
崩溃后,Kubernetes 会创建一个新的 pod 来维持状态,但是两个 pod 之间没有任何数据转移机制。
为了解决这个问题,可以将数据存储在集群 pod 外部的单独空间中。

和管理计算实例相比,管理此类存储面临的是另一些问题。Kubernetes 中的 PersistentVolume 子系统为用户和管理员提供了一个 API,该 API 从存储的使用方式中抽象出如何提供存储的细节。
Persistent Volumes 和 Persistent Volume Claims
摘自 Kubernetes 文档 —
"持久卷(PersistentVolume,PV)是集群中的一块存储,可以由管理员事先供应,或者使用存储类(Storage Class)来动态供应。 持久卷是集群资源,就像节点也是集群资源一样。"
实际上,PersistentVolume 是一种从存储空间获得切片并将其保留给特定 pod 的方法。Volumes 始终由 pod 占用,而不是像 deployment 这样的高级对象占用。
如果要在具有多个 pod 的 deployment 中使用 volume,必须要执行一些附加步骤。
在 k8s 目录中创建一个名为 database-persistent-volume.yaml 的新文件,内容如下:
apiVersion: v1
kind: PersistentVolume
metadata:
name: database-persistent-volume
spec:
storageClassName: manual
capacity:
storage: 5Gi
accessModes:
- ReadWriteOnce
hostPath:
path: "/mnt/data"
apiVersion、 kind 和 metadata 与其它配置文件里的用法一致,在 spec 字段里,有一些新字段:
spec.storageClassName指示 volume 的名称。假设云提供商有三种可用的存储。slow、 fast 和 very fast 。从云存储上获取的存储方式取决于支付的金额。如果需要 very fast 存储,则需要支付更多的费用。这些不同类型的存储就是 classes。在本例里我使用manual,在本地集群里可以使用任何你喜欢的选项。spec.capacity.storage代表 volume 的存储大小。在此项目中设置了 5GB 的存储空间。spec.accessModes设置卷的访问模式。一共有三种存储模式,ReadWriteOnce代表该 volume 可以通过单个 node 以读写方式安装。ReadWriteMany则代表该 volume 可以被多个 node 以读写的方式安装。ReadOnlyMany意味着该 volume 可以被多个 node 以只读的方式安装。spec.hostPath是特定于开发者的。它将本地单 node 集群的目录映射为 persistent volume。/mnt/data意味着保存在持久卷(persistent volume)中的数据位于集群的/mnt/data文件夹内。
执行下面的命令 apply 配置文件:
kubectl apply -f database-persistent-volume.yaml
# persistentvolume/database-persistent-volume created
现在使用 get 命令确定 volume 创建成功:
kubectl get persistentvolume
# NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
# database-persistent-volume 5Gi RWO Retain Available manual 58s
现在已经创建了 persistent volume,需要让 postgres pod 访问它,可以通过PersistentVolumeClaim (PVC) 。
persistent volume 声明是 pod 对存储的要求。假设在集群中有很多 volumes。该声明将定义必需满足 pod 的需求的 volume 的特征。
一个类似的的例子是从商店购买 SSD。销售员向你展示了如下模型:
| MODEL 1 | MODEL 2 | MODEL 3 |
|---|---|---|
| 128GB | 256GB | 512GB |
| SATA | NVME | SATA |
现在你和销售员要求至少 200GB 的存储容量,并且驱动器的型号是 NVME。
MODEL1 是容量小于 200GB 的 SATA,与你的要求不符,MODEL 3 容量大于 200GB,但是不是 NVME 接口的。只有 MODEL2 是容量大于 200GB 并且接口是 NVME 的。正是需要的。
销售人员向你展示的 SSD models 就等同于 persistent volumes,你的要求就等同于 persistent volume 声明。
在 k8s 目录下创建一个名为 database-persistent-volume-claim.yaml 的新文件,文件内容如下:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: database-persistent-volume-claim
spec:
storageClassName: manual
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 2Gi
apiVersion、 kind 和 metadata 和之前的作用一致。
spec.storageClass表示存储类型的声明配置文件。 着意味着将任何设置为manual的spec.storageClass的PersistentVolume都适合此类声明。如果有多个设置为manual的 volumes ,那么将获得其中任意一个的声明。如果没有 class 为manual的 volume,那就动态配置一个。spec.accessModes在此设置访问模式。这表明该声明希望使用具有ReadWriteOnce的accessMode。假设有两个设置为manual的 volumes 。其中一个将其accessModes设置为ReadWriteOnce,另一个设置为ReadWriteMany。该声明将获取其中的ReadWriteOnce。resources.requests.storage是此声明所需要的存储量2Gi并不意味着给定的卷必须恰好具有 2GB 的存储容量 。而是意味着它至少要有 2GB。你应该还记得之前将存储容量设置为 5GB,大于 2GB。
执行下面的命令 apply 文件:
kubectl apply -f database-persistent-volume-claim.yaml
# persistentvolumeclaim/database-persistent-volume-claim created
使用 get 命令确定 volume 已经成功创建:
kubectl get persistentvolumeclaim
# NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
# database-persistent-volume-claim Bound database-persistent-volume 5Gi RWO manual 37s
查看 VOLUME 列,这个声明与之前创建的 database-persistent-volume 持久卷绑定 ,在看一下 CAPACITY,它是 5Gi,因为该声明要求 volume 至少有 2GB 的存储容量。
Persistent Volumes 的动态预配置
在上一小节,你已经创建了一个 persistent volume,然后创建了一个声明,但是如果以前没有设置任何 persistent volume 该怎么办呢?
在这种情况下,将自动设置与声明兼容的持久卷。
开始之前,先执行如下命令删除之前创建的 persistent volume 和 persistent volume 声明:
kubectl delete persistentvolumeclaim --all
# persistentvolumeclaim "database-persistent-volume-claim" deleted
kubectl delete persistentvolumeclaim --all
# persistentvolume "database-persistent-volume" deleted
打开 database-persistent-volume-claim.yaml 文件将内容更新为如下内容:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: database-persistent-volume-claim
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 2Gi
我已经从文件中删除了 spec.storageClass 字段,现在重新 apply database-persistent-volume-claim.yaml 文件(无需应用 database-persistent-volume.yaml 文件):
kubectl apply -f database-persistent-volume-claim.yaml
# persistentvolumeclaim/database-persistent-volume-claim created
现在使用 get 命令查看声明信息:
kubectl get persistentvolumeclaim
# NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
# database-persistent-volume-claim Bound pvc-525ae8af-00d3-4cc7-ae47-866aa13dffd5 2Gi RWO standard 2s
正如你看到的,已经提供了名为 pvc-525ae8af-00d3-4cc7-ae47-866aa13dffd5 且存储容量为 2Gi 的 volume,将其动态绑定到了声明。
该项目的剩余部分使用静态或者动态预配置 persistent volume 都可以。我会使用动态配置。
通过 Pods 连接 Volumes
现在你已经创建了一个 persistent volume 和声明,是时候让数据库 pod 使用该 volume 了。
可以把之前小节创建的 persistent volume 声明连接到 pod 上。打开 postgres-deployment.yaml 文件,将内容更新如下:
apiVersion: apps/v1
kind: Deployment
metadata:
name: postgres-deployment
spec:
replicas: 1
selector:
matchLabels:
component: postgres
template:
metadata:
labels:
component: postgres
spec:
# volume configuration for the pod
volumes:
- name: postgres-storage
persistentVolumeClaim:
claimName: database-persistent-volume-claim
containers:
- name: postgres
image: fhsinchy/notes-postgres
ports:
- containerPort: 5432
# volume mounting configuration for the container
volumeMounts:
- name: postgres-storage
mountPath: /var/lib/postgresql/data
subPath: postgres
env:
- name: POSTGRES_PASSWORD
value: 63eaQB9wtLqmNBpg
- name: POSTGRES_DB
value: notesdb
我在此配置文件中添加了两个字段。
spec.volumes字段包含了供 pod 查找 persistent volume 申明的必要信息。spec.volumes.name可以是你想要的任何东西。spec.volumes.persistentVolumeClaim.claimName必需与database-persistent-volume-claim.yaml文件中的metadata.name值相匹配。containers.volumeMounts包含容器挂载的 volume 所必需的信息。containers.volumeMounts.name必需与spec.volumes.name中的值相匹配。containers.volumeMounts.mountPath代表 volume 挂载的目录。/var/lib/postgresql/data是 PostgreSQL 的默认数据目录。containers.volumeMounts.subPath表示将在 volume 创建的目录。假设你与其它的 pod 正在使用相同的 volume。保存在/var/lib/postgresql/data目录中的所有数据都将进入 volume 的postgres路径下。
现在执行下面的命令重新 apply postgres-deployment.yaml 文件:
kubectl apply -f postgres-deployment.yaml
# deployment.apps/postgres-deployment configured
现在,已经进行了正确的数据库部署,数据丢失的风险小了很多。
想要在这里提及的是,目前数据库部署中只有一个副本,如果有多个副本,那么情况会有所不同,
多个 pod 在不知道彼此存在情况下访问相同的 volume 会产生灾难性的后果 ,在 volume 内为 pod 创建子目录可以解决这个问题。
组装起来
现在已经运行了 API 和数据库,是时候建立网络并做一些后续工作了。
在前面的章节中已经了解到 Kubernetes 中的网络设置,在开始编写服务之前,先看看我为项目制定的联网计划。

- 数据库只使用
ClusterIPservice 在集群内暴露,不允许任何外部流量访问。 - API 部署服务将暴露给外部世界,用户将与 API 通信,API 与数据库通信。
之前通过 LoadBalancer service 将应用暴露给了外部世界,ClusterIP 则再集群中公开应用,并且不允许外部流量访问。

鉴于数据库服务应仅在集群内可用 ,因此 ClusterIP service 服务非常适合此方案。
在 k8s 目录下创建一个名为 postgres-cluster-ip-service.yaml 的文件,内容如下:
apiVersion: v1
kind: Service
metadata:
name: postgres-cluster-ip-service
spec:
type: ClusterIP
selector:
component: postgres
ports:
- port: 5432
targetPort: 5432
ClusterIP 的配置文件与 LoadBalancer 的配置文件差不多,唯一的不同的是 spec.type 。
现在,这个文件就清晰了。5432 是 PostgreSQL 运行的默认端口。所以也要集群内暴露 5432 。
接下来是 LoadBalancer service 的配置文件,负责将 API 暴露给外界。创建一个名为 api-load-balancer-service.yaml 的文件,内容如下:
apiVersion: v1
kind: Service
metadata:
name: api-load-balancer-service
spec:
type: LoadBalancer
ports:
- port: 3000
targetPort: 3000
selector:
component: api
此配置与上一节中的配置相同。API 运行在容器内的 3000 端口,所以也要在集群中暴露此端口。
最后要做的是要将环境变量添加到 API deployment 中。打开 api-deployment.yaml 文件并按照如下更新其内容:
apiVersion: apps/v1
kind: Deployment
metadata:
name: api-deployment
spec:
replicas: 3
selector:
matchLabels:
component: api
template:
metadata:
labels:
component: api
spec:
containers:
- name: api
image: fhsinchy/notes-api
ports:
- containerPort: 3000
env:
- name: DB_CONNECTION
value: pg
- name: DB_HOST
value: postgres-cluster-ip-service
- name: DB_PORT
value: '5432'
- name: DB_USER
value: postgres
- name: DB_DATABASE
value: notesdb
- name: DB_PASSWORD
value: 63eaQB9wtLqmNBpg
之前,spec.containers.env 下面只有 DB_CONNECTION 变量,新涉及到的字段如下:
DB_HOST表示数据库服务的地址。在非容器化环境中,该值通常为127.0.0.1。但是在 Kubernetes 环境中,并不知道数据库容器的 IP 地址。因此只需使用公开的数据库 service 的名字即可 。DB_PORT是数据库 service 公开的端口,即 5432。DB_USER用于连接数据库的用户,默认的用户名是postgres。DB_DATABASEAPI 将要连接的数据库,必须与postgres-deployment.yaml文件中的spec.containers.env.DB_DATABASE值相同。DB_PASSWORD用于连接数据库的密码,必须与postgres-deployment.yaml文件中的spec.containers.env.DB_PASSWORD值相匹配。
完成此操作后就可以测试 API 了。在执行操作之前,执行一下下面的命令 apply 所有的配置文件:
kubectl apply -f k8s
# deployment.apps/api-deployment created
# service/api-load-balancer-service created
# persistentvolumeclaim/database-persistent-volume-claim created
# service/postgres-cluster-ip-service created
# deployment.apps/postgres-deployment created
如果遇到任何错误,只需删除所有的资源并重新 apply 文件即可。service、persistent volumes、persistent volume 声明会立即创建。
用 get 命令确保所有的部署都已经启动且运行:
kubectl get deployment
# NAME READY UP-TO-DATE AVAILABLE AGE
# api-deployment 3/3 3 3 106s
# postgres-deployment 1/1 1 1 106s
从 READY 列中可以看出,所有的 pod 都已经启动并且正在运行。执行 minikube 的 service 命令访问 API。
minikube service api-load-balancer-service
# |-----------|---------------------------|-------------|-----------------------------|
# | NAMESPACE | NAME | TARGET PORT | URL |
# |-----------|---------------------------|-------------|-----------------------------|
# | default | api-load-balancer-service | 3000 | http://172.19.186.112:31546 |
# |-----------|---------------------------|-------------|-----------------------------|
# * Opening service default/api-load-balancer-service in default browser...
API 会在默认浏览器里立即打开:

这时 API 的默认响应,还可以通过 Insomnia 或者 Postman 来测试 http://172.19.186.112:31546/ API 的完整 CRUD 功能。
可以将 API 源代码随附的测试作为文档查看。只需打开 api/tests/e2e/api/routes/notes.test.js 文件即可,如果你有 JavaScript 和express 的经验,那么理解这个文件会很容易。
使用 Ingress Controller
目前为止,已经使用 ClusterIP 在集群内公开了的应用程序,使用 LoadBalancer 把应用暴露给集群外。
尽管我已经引用了 LoadBalancer 作为引用于集群外部公开应用程序的的标准 service,但是它还有一些缺点。
当使用 LoadBalancer services 在云环境中公开应用程序时,必需单独为每个公开的服务付费。这在大型项目下回非常昂贵。
还有另一种成为 NodePort 的 service,可以代替 LoadBalancer service。

NodePort 在集群所有节点上打开一个特定的端口,并处理通过该打开端口的所有流量。
你知道,service 将多个 pod 组合在一起,并控制他们的访问方式。通过公开端口到达 service 的任何请求都将最终在正确的容器中。
用于创建 NodePort 的实例配置文件如下:
apiVersion: v1
kind: Service
metadata:
name: hello-kube-node-port
spec:
type: NodePort
ports:
- port: 8080
targetPort: 8080
nodePort: 31515
selector:
component: web
这里的 spec.ports.nodePort 字段值必须在 30000 和 32767 之间,此范围超出了各种服务通常所使用的常用端口。端口的数字位数很多。、
尝试用
NodePortservice 替换前面几节创建的LoadBalancerservice,这应该不难,算是对所学知识的简单测试。
创建 Ingress 可以解决此问题,澄清一下,Ingress 不是一种 service,相反,它位于各个 service 前面,充当路由器的角色。
在集群中使用 Ingress 资源用到了 IngressController。可以在 Kubernetes 文档 中找到可用 的 ingress controllers 列表。
设置 NGINX Ingress Controller
在此例中,通过向其添加 front end 来扩展 notes API。使用 Ingress 来暴露应用,而不是使用诸如 LoadBalancer 或者 NodePort 之类的 service。
将要使用的而控制器是 NGINX Ingress Controller,在此 NGINX 将用于不同 service 请求的路由。NGINX Ingress Controller 使 Kubernetes 集群的 NGINX 配置变的更容易。
项目代码在 fullstack-notes-application 路径下:
.
├── api
├── client
├── docker-compose.yaml
├── k8s
│ ├── api-deployment.yaml
│ ├── database-persistent-volume-claim.yaml
│ ├── postgres-cluster-ip-service.yaml
│ └── postgres-deployment.yaml
├── nginx
└── postgres
5 directories, 1 file
你会看到 k8s 目录,包含在上一个小节中除了 api-load-balancer-service.yaml 文件的所有的配置文件。
原因是,在该项目中,旧的 LoadBalancer service 将被 Ingress 代替。另外,无需公开 API,而是将前端应用程序公开即可。
在开始编写新文件之前,先看看架构。

用户访问前端应用程序并提交必要的数据,然后前端应用程序将提交的数据转发到后端 API。
然后 API 将数据保留在数据库中,并将其发送回前端应用程序。然后使用 NGINX 实现请求的路由。
可以查看 nginx/production.conf 文件了解如何设置此路由。
现在实现目标所必需的网络如下:

具体如下:
Ingress将充当此应用程序的入口点和路由器,这是一个NGINX类型的Ingress,因此端口是 nginx 的默认端口 80。- 到
/的每个请求都会被路由到前端应用(左侧的服务)处理。因此,如果应用程序的 URL 是https://kube-notes.test,那么所有的https://kube-notes.test/foo或者https://kube-notes.test/bar都会由前端应用程序处理。 - 到
/api的每个请求都会被路由到后端的 API (右侧的服务)处理。因此,如果 URL 是https://kube-notes.test,那么所有的https://kube-notes.test/api/foo或者https://kube-notes.test/api/bar都会由后端 API 处理。
完全可以将 Ingress service 配置与子域名一起使用,而不是向这样的路径,这里的设计使用路径的方式。
在本小节中,必需编写四个新的配置文件:
ClusterIP是 API deployment 的配置。Deployment是 front-end 应用的配置。ClusterIP是 front-end 应用的配置。Ingress是路由的配置。
前三个文件我会快速的过一下。
第一个文件是 api-cluster-ip-service.yaml 配置,内容如下:
apiVersion: v1
kind: Service
metadata:
name: api-cluster-ip-service
spec:
type: ClusterIP
selector:
component: api
ports:
- port: 3000
targetPort: 3000
尽管在上一小节中,将 API 直接暴露给了外界,但在本小节中,Ingress 承担起了这个任务,同时使用 ClusterIP 在内部公开 API。
配置不言自明,无需过多解释。
接下来创建一个名为 client-deployment.yaml 的文件来运行前端应用,内容如下:
apiVersion: apps/v1
kind: Deployment
metadata:
name: client-deployment
spec:
replicas: 3
selector:
matchLabels:
component: client
template:
metadata:
labels:
component: client
spec:
containers:
- name: client
image: fhsinchy/notes-client
ports:
- containerPort: 8080
env:
- name: VUE_APP_API_URL
value: /api
它几乎与 api-deployment.yaml 文件相同,很好理解。
VUE_APP_API_URL 环境变量表示 API 请求应该转发的路径。这些转发请求将依次由Ingress 处理。
需要另一个 ClusterIP service 来公开客户端应用程序。创建一个名为 client-cluster-ip-service.yaml 的新文件,内容如下:
apiVersion: v1
kind: Service
metadata:
name: client-cluster-ip-service
spec:
type: ClusterIP
selector:
component: client
ports:
- port: 8080
targetPort: 8080
描述的是运行在集群上默认暴露在 8080 端口上的前端应用。
在完成了旧配置之后,下一个配置是 ingress-service.yaml 文件,内容如下:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: ingress-service
annotations:
kubernetes.io/ingress.class: nginx
nginx.ingress.kubernetes.io/rewrite-target: /$1
spec:
rules:
- http:
paths:
- path: /?(.)
backend:
serviceName: client-cluster-ip-service
servicePort: 8080
- path: /api/?(.)
backend:
serviceName: api-cluster-ip-service
servicePort: 3000
该文件有一些新配置,也很好理解:
IngressAPI 仍处于测试阶段,所以apiVersion是extensions/v1beta1。尽管处于 beta 版本,该 API 很稳定,可以直接在生产环境中使用。kind和metadata.name字段和之前配置相同。metadata.annotations可以包含有关Ingress配置的信息。kubernetes.io/ingress.class: nginx表示Ingress对象应该由ingress-nginx控制器控制。nginx.ingress.kubernetes.io/rewrite-target表示重写目标 URL 的地方。spec.rules.http.paths包含在nginx/production.conf文件中看到的各个路径的路由配置。paths.path表示路由的路径,backend.serviceName是上述路径应该匹配的 service。backend.servicePort是服务内部的端口。/?(._)_和/api/?(._)是简单的正则表达式,表示?(.*)部分会被路由到指定的服务。
配置重写的方式会时不时发生变化,具体可以查看官方文档。
在 apply 新的配置之前,使用 addons 命令激活 minikube 的 ingress 插件,用法如下:
minikube addons <option> <addon name
执行如下命令激活 ingress 插件:
minikube addons enable ingress
# ? Verifying ingress addon...
# ? The 'ingress' addon is enabled
可以对 addon 命令使用 disable 选项来禁用插件,查看官网文档了解 addon 命令的更多信息。
插件激活后,可以 apply 配置文件,建议在 apply 新资源之前删除所有的资源(service、deployment 和 persistent volume claims)。
kubectl delete ingress --all
# ingress.extensions "ingress-service" deleted
kubectl delete service --all
# service "api-cluster-ip-service" deleted
# service "client-cluster-ip-service" deleted
# service "kubernetes" deleted
# service "postgres-cluster-ip-service" deleted
kubectl delete deployment --all
# deployment.apps "api-deployment" deleted
# deployment.apps "client-deployment" deleted
# deployment.apps "postgres-deployment" deleted
kubectl delete persistentvolumeclaim --all
# persistentvolumeclaim "database-persistent-volume-claim" deleted
kubectl apply -f k8s
# service/api-cluster-ip-service created
# deployment.apps/api-deployment created
# service/client-cluster-ip-service created
# deployment.apps/client-deployment created
# persistentvolumeclaim/database-persistent-volume-claim created
# ingress.extensions/ingress-service created
# service/postgres-cluster-ip-service created
# deployment.apps/postgres-deployment created
使用 get 命令来确保所有的资源都已经创建成功。当全部运行后,可以通过 minikube 集群的 IP 地址访问该应用程序。执行如下命令获取 IP 地址:
minikube ip
# 172.17.0.2
还可以通过运行 Ingress 来获取此 IP 的地址:
kubectl get ingress
# NAME CLASS HOSTS ADDRESS PORTS AGE
# ingress-service <none> * 172.17.0.2 80 2m33s
IP 和 端口分别在 ADDRESS 和 PORTS 端口列下。访问 127.17.0.2:80,可以直接进入 notes 应用程序。

可以在此应用中执行简单的 CRUD 操作,端口 80 是 NGINX 的默认端口,因此可以省略 URL 中的端口号。
如果你了解如何配置 NGINX,可以使用 ingress controller 执行很多操作。毕竟,这就是控制器的用途 - 将 NGINX 的配置存储在 Kubernetes 的 ConfigMap 上,将会在下一部分中学习。
Kubernetes 中的 Secret 和配置
目前为止,部署中使用纯文本形式存储了敏感信息,如 POSTGRES_PASSWORD,这并不是最佳实践。
可以用 Secret 将值存储在集群中,这是存储密码、token 等的更安全的方法。
需要将数据转换成 base64 数据才能将信息存储在 Secret 中。如果纯文本密码为 63eaQB9wtLqmNBpg ,执行以下命令获取 base64 版本。
echo -n "63eaQB9wtLqmNBpg" | base64
# NjNlYVFCOXd0THFtTkJwZw==
此步骤是必要的,参数必需是 base64 格式的,现在在 k8s 目录下创建一个 postgres-secret.yaml 文件,内容如下:
apiVersion: v1
kind: Secret
metadata:
name: postgres-secret
data:
password: NjNlYVFCOXd0THFtTkJwZw==
apiVersion、kind 和 metadata 的意义无需解释,data 字段就是真实的密文。
如上,创建了一个键值对,键是 password, 值是 NjNlYVFCOXd0THFtTkJwZw==。将使用 metadata.name 值在其他配置文件中作为获取密码值的 Secret 的标识。
按如下更新 postgres-deployment.yaml 文件,以在数据库配置中使用此密码:
apiVersion: apps/v1
kind: Deployment
metadata:
name: postgres-deployment
spec:
replicas: 1
selector:
matchLabels:
component: postgres
template:
metadata:
labels:
component: postgres
spec:
volumes:
- name: postgres-storage
persistentVolumeClaim:
claimName: database-persistent-volume-claim
containers:
- name: postgres
image: fhsinchy/notes-postgres
ports:
- containerPort: 5432
volumeMounts:
- name: postgres-storage
mountPath: /var/lib/postgresql/data
subPath: postgres
env:
# not putting the password directly anymore
- name: POSTGRES_PASSWORD
valueFrom:
secretKeyRef:
name: postgres-secret
key: password
- name: POSTGRES_DB
value: notesdb
如上,除了 spec.template.spec.continers.env 字段外,所有的字段介绍过。
之前用于存储密码的 name 环境变量是纯文本。但是现在是 valueFrom.secretKeyRef 字段。
这里的 name 字段是指刚刚创建的 Secret 的名字,key 值是指 Secret 配置文件键值对中的键。Kubernetes 将在内部将编码后的值解码为纯文本。
除了数据库配置,你还需按如下所示更新 api-deployment.yaml 文件:
apiVersion: apps/v1
kind: Deployment
metadata:
name: api-deployment
spec:
replicas: 3
selector:
matchLabels:
component: api
template:
metadata:
labels:
component: api
spec:
containers:
- name: api
image: fhsinchy/notes-api
ports:
- containerPort: 3000
env:
- name: DB_CONNECTION
value: pg
- name: DB_HOST
value: postgres-cluster-ip-service
- name: DB_PORT
value: '5432'
- name: DB_USER
value: postgres
- name: DB_DATABASE
value: notesdb
# not putting the password directly anymore
- name: DB_PASSWORD
valueFrom:
secretKeyRef:
name: postgres-secret
key: password
现在执行下面的命令 apply 这些新的配置文件:
kubectl apply -f k8s
# service/api-cluster-ip-service created
# deployment.apps/api-deployment created
# service/client-cluster-ip-service created
# deployment.apps/client-deployment created
# persistentvolumeclaim/database-persistent-volume-claim created
# secret/postgres-secret created
# ingress.extensions/ingress-service created
# service/postgres-cluster-ip-service created
# deployment.apps/postgres-deployment created
取决于集群的状态不同,输出可能会不同。
谨慎起见,先删除所有的资源然后在 apply 配置文件来创建他们。
使用 get 命令检查并确保所有的 pod 都已经启动并且正在运行。
使用 minikube IP 访问 notes 应用程序并尝试创建新的 notes, 来测试新的配置。
minikube ip
# 172.17.0.2
访问 127.17.0.2:80,你应该会直接进入 Notes 应用程序。

还有一种无需任何配置文件即可创建 secret 的方法,执行如下命令,使用 kubectl 创建相同的 Secret。
kubectl create secret generic postgres-secret --from-literal=password=63eaQB9wtLqmNBpg
# secret/postgres-secret created
这是一种更方便的方法,因为可以跳过整个 base64 编码步骤。在这种情况下,secret 会被自动编码。
ConfigMap 和 Secret 类似,一般用于非隐私的的信息。
在 k8s 目录下创建一个名为 api-config-map.yaml 的文件,把 API deployment 里所有的其余的环境变量放在 ConfigMap 里:
apiVersion: v1
kind: ConfigMap
metadata:
name: api-config-map
data:
DB_CONNECTION: pg
DB_HOST: postgres-cluster-ip-service
DB_PORT: '5432'
DB_USER: postgres
DB_DATABASE: notesdb
apiVersion、 kind 和 metadata 无需解释。data 字段是以键值对形式的环境变量。
和 Secret 不同,此处的 key 必需与 API 所需的 key 匹配。因此,我从 api-deployment.yaml 文件中复制了一些变量,并稍作修改后粘贴到了此处。
要在 API deployment 中使用 secret,打开 api-deployment.yaml 文件并做如下修改:
apiVersion: apps/v1
kind: Deployment
metadata:
name: api-deployment
spec:
replicas: 3
selector:
matchLabels:
component: api
template:
metadata:
labels:
component: api
spec:
containers:
- name: api
image: fhsinchy/notes-api
ports:
- containerPort: 3000
# not putting environment variables directly
envFrom:
- configMapRef:
name: api-config-map
env:
- name: DB_PASSWORD
valueFrom:
secretKeyRef:
name: postgres-secret
key: password
文件除了 spec.template.spec.containers.env 字段外几乎没有改变。
我已经将环境变量移到了 ConfigMap 中。spec.template.spec.containers.envFrom 用来从 ConfigMap 中获取数据。configMapRef.name 表示将从中 提取环境变量的 ConfigMap 。
然后执行下面的命令 apply 所有的配置:
kubectl apply -f k8s
# service/api-cluster-ip-service created
# configmap/api-config-map created
# deployment.apps/api-deployment created
# service/client-cluster-ip-service created
# deployment.apps/client-deployment created
# persistentvolumeclaim/database-persistent-volume-claim created
# ingress.extensions/ingress-service configured
# service/postgres-cluster-ip-service created
# deployment.apps/postgres-deployment created
# secret/postgres-secret created
取决于集群的状态,输出可能会不同。
谨慎起见,先删除所有的 Kubernetes 资源然后在 apply configs 创建他们。
使用 get 命令确保 pod 已经启动并运行,使用 minikube IP 访问 notes 应用并尝试创建新的 note。
执行下面的命令获取 IP 地址。
minikube ip
# 172.17.0.2
访问 127.17.0.2:80 ,直接进入 notes 应用程序。
Secret 和 ConfigMap 还有其它一些技巧,就不在这里展开了,如果想了解,可以查看官方文档。
在 Kubernetes 中执行更新发布
既然已经在 Kubernetes 上成功部署了一个包含多个容器的应用程序,是时候学习执行更新了。
Kubernetes 很神奇,将容器更新为较新版本的镜像比较麻烦,有很多种方式更新容器,这里不会涉及到所有的方法。
相反,我将直接进入更新容器时主要采取的方法。如果打开 client-deployment.yaml 文件并查看 spec.template.spec.containers 字段,会看到下面的配置:
containers:
- name: client
image: fhsinchy/notes-client
如上,在 image 字段中,没有使用任何镜像标签。现在,如果你认为在镜像尾部添加 :latest 将确保部署始终拉取最新的镜像,那你可就大错特错了。
我通常采用最简单的路径。之前提到过,在某些情况下,使用命令式而不是声明式是一个好主意,创建一个 Secret 或者更新容器就是这种情况。
可以用来执行更新的命令是 set 命令,其通用语法如下:
kubectl set image <resource type>/<resource name> <container name>=<image name with tag>
资源类型为 deployment,资源名称为 client-deployment。可以在 client-deployment.yaml 文件内的 containers 字段找到容器的名称,本例中为 client 。
我已经构建了带有标签 edge 的 fhsinchy/notes-client 镜像,将使用它来更新 fhsinchy/notes-client 的版本。
最终命令如下:
kubectl set image deployment/client-deployment client=fhsinchy/notes-client:edge
# deployment.apps/client-deployment image updated
由于 Kubernetes 将重新创建所有的 pod,执行此更新可能需要一段时间,可以运行 get 命令来了解是否所有的 pod 都已经启动并且成功运行。
重新创建后,使用 minikube IP 访问 notes 应用并尝试创建新的 notes。可以执行下面的命令获取 IP:
minikube ip
# 172.17.0.2
通过访问 127.17.0.2:80 应该可以直接进入 notes 应用程序。
鉴于我还未对应用程序代码进行任何实际更改,因此所有的内容都将保持不变。你可以使用 describe 命令来确保 pod 正在使用新的镜像。
kubectl describe pod client-deployment-849bc58bcc-gz26b | grep 'Image'
# Image: fhsinchy/notes-client:edge
# Image ID: docker-pullable://fhsinchy/notes-client@sha256:58bce38c16376df0f6d1320554a56df772e30a568d251b007506fd3b5eb8d7c2
grep 命令在 Mac 和 Linux 可以直接使用,如果你使用的是 Windows,使用 git bash 而不是 Windows 命令行。
尽管强制性更新过程有些繁琐,但是通过好的 CI/CD 流程可以使其变得更加容易。
组合 Configurations
尽管其中只有三个容器,但该项目中的配置文件数量已经非常庞大了。
实际上可以按照如下方式组合配置文件:
apiVersion: apps/v1
kind: Deployment
metadata:
name: client-deployment
spec:
replicas: 3
selector:
matchLabels:
component: client
template:
metadata:
labels:
component: client
spec:
containers:
- name: client
image: fhsinchy/notes-client
ports:
- containerPort: 8080
env:
- name: VUE_APP_API_URL
value: /api
---
apiVersion: v1
kind: Service
metadata:
name: client-cluster-ip-service
spec:
type: ClusterIP
selector:
component: client
ports:
- port: 8080
targetPort: 8080
如上,我已经使用界定符(---)组合了 client-deployment.yaml 和 client-cluster-ip-service.yaml 文件。尽管有可能在容器数量很多的项目中减少文件,但我还是建议将他们分开,更简洁、更干净。
答疑
在本节中,我将列出你使用 Kubernetes 时可能遇到的一些常见问题。
- 如果你在 Windows 或者 Mac 使用 Docker 的
minikube,Ingress插件可能并没有生效。、 - 如果你在 Mac 上运行了Laravel Valet,并且将 HyperKit 驱动程序用于
minikube,会联网失败。关闭minikube服务可以解决此问题。 - 如果你有一台 Ryzen (mine is R5 1600) PC,并且正在运行 Windows 10,由于缺少内嵌虚拟化支持 VirtualBox 可能会启动失败。必须在 Windows 10 (Pro、Enterprise 和 Education)上安装 Hyper-V 驱动程序,对于家庭版,很遗憾没有该选项。
- 如果你在 Windows 10 (Pro, Enterprise 和 Education) 上使用用于
minikube的 Hyper-V 驱动,VM 可能会启动失败,并显示 内存不足的消息。不要紧张,执行minikube start重新启动 VM。 - 如果你在 Windows 命令行中看到本文执行的某些命令丢失,或者功能异常,请改用 git 命令行或者 cmder 。
我建议在你的系统上安装一个 Linux 发行版,并将 Docker 驱动程序用于 minikube。目前为止,这是最快也是最可靠的设置。
结论
衷心感谢你花了这么长时间阅读本文,希望你享受学习过程,并了解了 Kubernetes 的基础知识。
你可以关注我的推特 @frhnhsin 或者在 LinkedIn /in/farhanhasin 上与我联系。