

原文:The complexity of simple algorithms and data structures in JS,作者:Yung L. Leung
在之前的文章《迈向计算科学的一步:JS 里的简易算法和数据结构》里,我们讨论了简易的算法 (线性和二分搜索;冒泡、选择、插入排序) 以及数据结构 (数组、键值对对象),这里将继续讨论算法和数据结构的复杂度概念及其应用。
复杂度
复杂度是衡量程序复杂程度的一个指标。对于算法和数据结构来讲,它代表运行指定任务(如搜索、排序、访问数据)花费的时间和空间 (计算所消耗的内存)。任务的执行效率取决于执行完整程序需要的操作数。
扔垃圾需要 3 步 (打包垃圾袋,拎出去,扔进垃圾桶里)。 扔垃圾 很简单,但是如果扔装修一周后攒的垃圾,会发现不能完成这个简单的任务,因为垃圾桶 空间不足 。
房屋吸尘需要一些重复的步骤 (打开开关,使用吸尘器头重复的在地板上刮扫,关闭开关)。越大的房间就需要在地板上刮扫越多次,房屋除尘也就要耗费 越多的时间 。

执行的操作数和执行元素的数量有一定的关系,垃圾 (元素) 越多花费的时间越多,这就产生了 空间复杂度 问题。面积 (元素) 越大,吸尘器头刮扫的次数就越多,这就产生了 时间复杂度 问题。
不管是 扔垃圾 还是 房间吸尘, 操作数 (O) 和 元素的数量 (n) 成正比。如果只有一个垃圾袋,那么一次只能携带一袋垃圾。如果有两个垃圾袋,那么同时就能携带两袋垃圾,当然在体力足以同时拎两袋垃圾的前提下。这些家务活的大 O 就是 O = n,也可以写成 O = function(n) 或者 O(n) 。在这里复杂度是线性的 (操作数和元素是一一对应的关系),即 30 个操作对应 30 个元素 (上图的黄线)。
在算法和数据结构里情况是一样的。
搜索
线性搜索

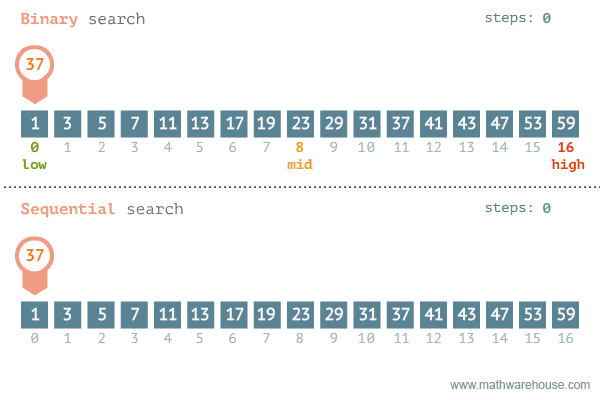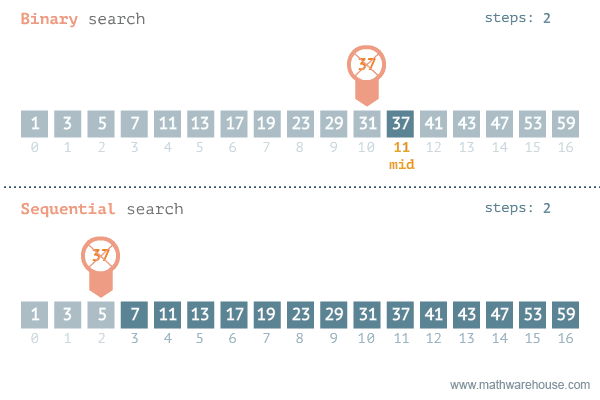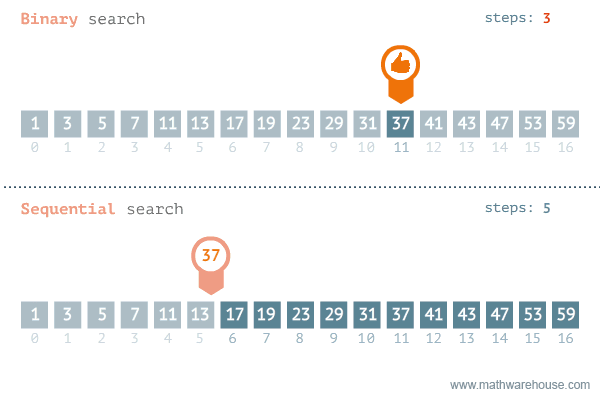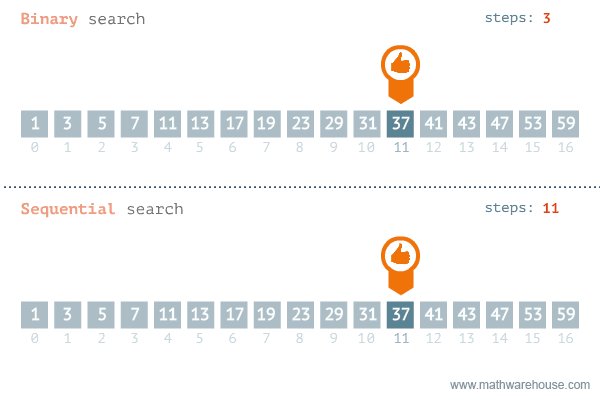{kind=link}
元素搜索的 最好情况 是有序列表,假设要搜索的元素就在列表的第一项,这时复杂度是常数 O(1)。因此,如果搜索的元素总是第一个被索引到,和列表长度无关,元素会当即被搜索到。搜索的复杂度是和列表长度相关的常数。这种搜索平均最坏的情况是线性复杂度 O(n)。换言之,n 个元素,要遍历 n 次才能找到,因此叫线性搜索。
二分搜索

对于二分搜索, 最好的情况 也是 O(1) ,此时搜索的元素位于中点。平均最坏的情况是 n 以 2 为底的对数:

对数或者 log 是幂运算的逆运算,所以如果有 16 个元素 (n=16),这时至少要花费 4 步(这是在最坏情况下),4 步就能找到数字 15 (基数 = 4)。

或者, O(log n)

排序
冒泡

{kind=link}
在冒泡排序里,元素和剩下的元素集合对比来找更高的元素向上冒泡,所以,平均最坏的情况,复杂度是 O(n²) ,也就是嵌套循环。

每一个元素都要和剩下元素的集合进行对比,4 个元素一共对比 16 次 (4² = 16)。 最好的情况 是集合除了一个元素外其余都已经排好序了,那么只需进行一轮对比。也就是说四个元素需要和集合里剩下的 3 个分别元素对比,复杂度也就是 O(n) 。
选择排序

和 冒泡排序 高值冒泡不同, 选择排序 把最低值放在未排序元素的最前面,因为需要和剩下集合的每个元素对比,它的复杂度是 O(n²) 。
插值排序

和 冒泡&选择排序 不同, 插值排序 把元素直接插入到正确的位置。和上一个排序一样,需要和集合里剩下的元素对比,因此 平均最坏的复杂度 是 O(n²) 。和冒泡排序类似,如果只有一个元素需要排序,只需要一轮对比来把元素插入到正确的位置。复杂度为 O(n) 。
数据结构
数组

因为通过索引访问、添加或者删除末位数据元素只需要一步, 访问、推入、弹出 数组里的值的复杂度是 O(1) 。因此,在数组里通过索引来 线性搜索 的复杂度是 O(n) 。
另外,在数组在前面 shift 或者 unshift 值需要 重新索引 之后的每一个元素 (比如,移除索引为 0 的元素需要重新给索引为 1 的元素标记为 0,依次直到第四个),它的复杂度是 O(n) ,需要重新标记所有元素。
健 - 值对对象

{kind=link}
通过健 访问、插入或者删除 值是瞬间发生的,因此,复杂度是 O(1) 。通过索引健在 “存储箱” 中搜索特定的项目本质是线性搜索,因此它的复杂度是 O(n) 。
结论
复杂度不只是既定算法和数据结构里面的一个论题。运用恰当,它会是衡量代码的效率的一个利器。