

原文:How to Extract Pages from a PDF and Render Them with JavaScript,作者:Hrishikesh Pathak
PDF 是便携式文档格式(portable document format)的缩写。PDF 是由 Adobe 在 90 年代为 Windows 设计的。它们是独立的文件,几乎所有主要的操作系统都支持。
但有时你需要修改 PDF 以满足你的需要,而不仅仅是查看它。不幸的是,用于 PDF 的现有软件往往不能满足你的特别要求。
但你是一个程序员,对吗?为什么不做一些软件来帮助 PDF 按你的要求工作呢?嗯,这就是本文的灵感所在。
在这篇文章中,我们将探讨所有流行的 PDF 相关的 JavaScript 库。为什么是 JavaScript?因为它有一些相当不错的 PDF 包可用,而且人们喜欢它,特别是我自己。
你将在本教程中创建的 PDF 浏览器项目
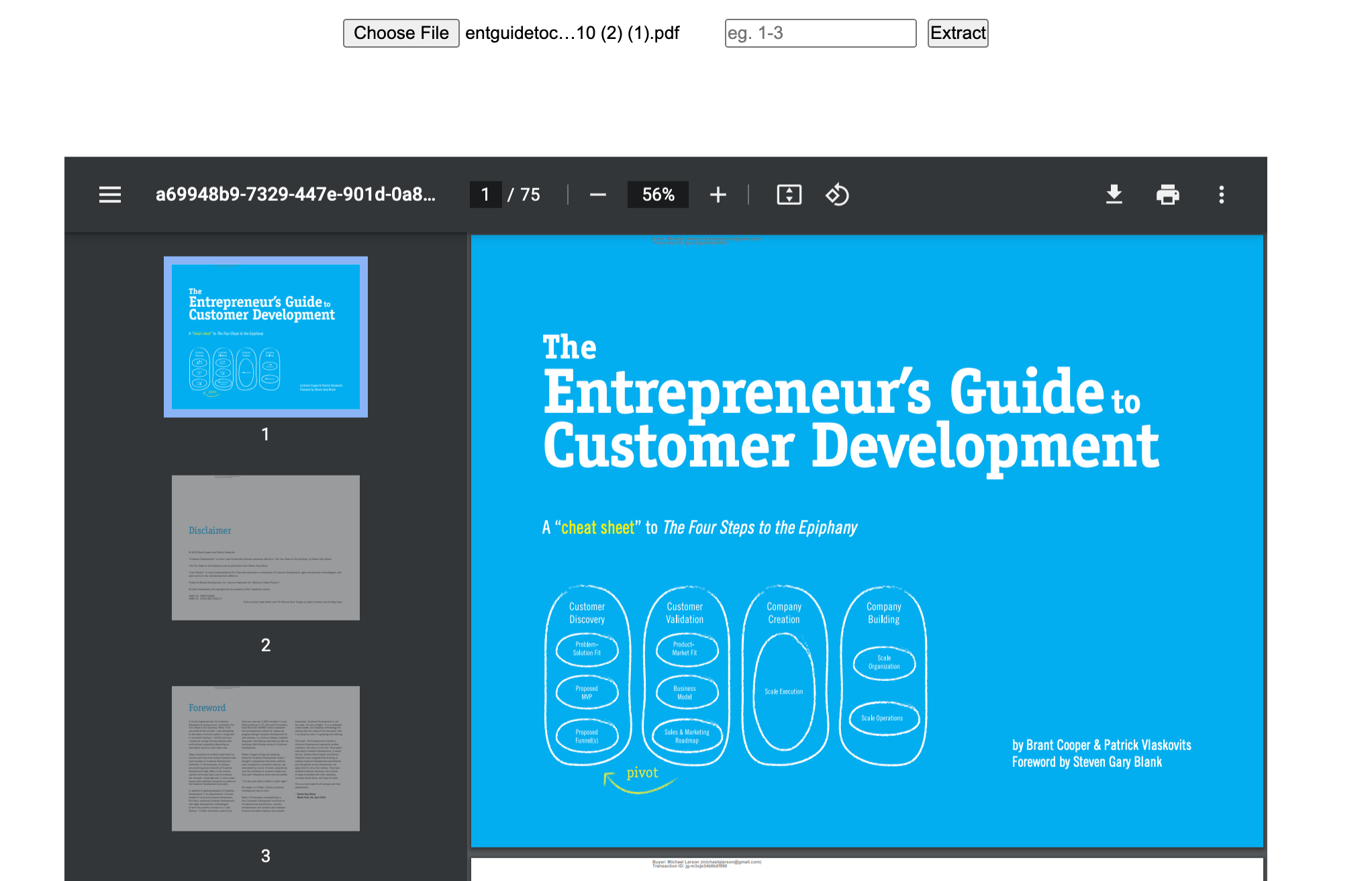
以下是你将在本教程中创建的 demo。
- 首先,我们将探索一些流行的 PDF 包,用于 JavaScript 中与 PDF 相关的工作。然后,我们将对它们进行比较,找到适合我们要求的最佳软件包。
- 接下来,我们将加载一个现有的 PDF,并从中提取一些页面。提取的页面将组成一个新的 PDF 文档。
- 然后,我们将在浏览器中渲染新的 PDF(我们在第二步中制作的)。
- 最后,我们将下载新的 PDF 文件供以后使用。
这些就是我们将要学习的所有步骤。我希望你看到结果时会很开心。让我们深入了解一下。
用于 JavaScript 的 PDF 库
我发现 JavaScript 中的 PDF 库主要有两种类型。一种是用于 PDF 渲染生成,另一种是用于 PDF 操作(或修改)。我在搜索了一个多小时后发现了一堆 PDF 库,这些是我最好的选择。
这里列出的所有软件包都是免费的、开源的软件包。你可以在 npm 注册表中找到所有这些包。
pdfjs
该软件包由 Firefox 网络浏览器背后的公司 Mozilla 制作。pdfjs 是一个基于 Web 标准的解析和呈现 PDF 的平台。
当你在 Firefox 中查看 PDF 时,PDF 查看器是使用此 pdfjs 包制作的。
这个包的核心优势是在网页上进行 PDF 渲染,不太支持其他的 PDF 修改功能。如果你想为你的网站制作一个自定义的 PDF 浏览器,这可能是你正在寻找的软件包。
pdfjs 有一个非常简单的 API。他们有很多教程可以让你开始使用这个库。如果你还不相信,可以使用这个库一段时间,你一定会爱上它的。
pdf-lib
与之前的 pdfjs 包不同,pdf-lib 主要用于 PDF 的创建和操作。你可以根据你的需要用这个包动态地生成一个新的 PDF 文档。
这个包对修改现有文档有强大的支持。你可以用这个库做很多 PDF 的修改。例如,你可以做 PDF 的分割和合并,你可以提取一个页面、注释一个 PDF 文档、添加一个大纲,以及更多你能想象的事情。
它只有 JavaScript 作为一个依赖项。所以,它可以运行在任何有 JavaScript 运行时的设备上。浏览器、Nodejs、Deno 和 React Native 都得到良好的支持。如果能在设备上安装 JavaScript,那么这个库就肯定能运行。
pdf-lib 的主要缺点是,它没有强大的渲染支持。如果你想用这个库做一个漂亮的 PDF 浏览用户界面,那么 pdf-lib 不是你的正确选择。在这种情况下,你应该使用 pdfjs。
pdfjs #2
如果你认为我在重复自己的话(跟 Mozilla 维护的 pdfjs 不一样),其实我没有。这是一个用于创建 PDF 文档的 JavaScript 库。它有一个非常简单的 API 供你使用。
我们之前讨论过的 pdfjs 库在用户界面上有非常强大的渲染支持,但它缺乏 PDF 创建和修改功能。
但这个库是以创建 PDF 为目的而构建的。它有一个非常简单的 API,对初学者很友好。你可以将它与 pdf-lib 包进行比较。
这个 pdfjs 库的主要缺点是,对现有文件的修改支持仍处于测试阶段。它并不是很稳定,而且仍在进行中。
如果你的主要关注点是 PDF 修改(例如,页面提取、合并、拆分、注释等),那么这个库可能不适合你。
如果贡献者能够进行维护,那么这可能是对 JavaScript 来说最好的 PDF 包。
js-pdf
与上面列出的所有 PDF 包不同,这个库非常强大。你可以用这个库做任何与 PDF 有关的工作。这就像一个万能的库。如果你想要一些复杂的 PDF 相关的东西,那么这个库可以做到。
但在 JavaScript 中还有更好的包,它们对个别任务非常好。例如,pdfjs 是一个比 js-pdf 更好的 PDF 渲染器,而 pdf-lib 比 js-pdf 有更好的修改支持。
这里我说的不是实际性能或其他类型的指标,我说的是开发者的体验。我发现它的 API 不是很直观。对于一个初学者来说,第一眼就会感到不知所措。不过,这是我的看法,也是我使用它时的体验。
PDF 生成是这个库的主要优势。你可以用你的任何设计来生成任何类型的 PDF。这个软件包将为你完成所有繁重的工作。如果你有经验,那么这可能是你的最佳选择。
react-pdf
顾名思义,这个库是专门针对 React 生态系统的。其用法非常具有 React 风格。你可以用它类似 JSX 的语法轻松创建一个文档。
你可以用简单的 React 组件创建和显示一个 PDF 文档。但功能非常有限。这个库主要用于生成 PDF。
如果你的目标是向用户展示一个 PDF,那么你可以使用这个包。作为一个 React 爱好者,你会喜欢这个库。看看他们的练习环境(playground),花些时间来使用这个包。这样你就会知道你是否需要这个库。
为什么我们要在本教程中使用 pdf-lib
在上面提到的所有这些 PDF 库中,我将在本文中使用 pdf-lib。因为我们要分割和合并 PDF 页面,并在浏览器中渲染它们,pdf-lib 似乎是这种情况下的最佳选择。
而且,pdf-lib 有相当简单的 API 可以使用,所有这些 API 都有很好的文档。如果你使用 TypeScript,你还可以获得类型推导,这非常有帮助。
最后但同样重要的是,他们的例子非常好。你可以在几分钟内启动并运行它。我喜欢这个库,因为它适合我的需求。
如何在 JavaScript 中读取本地 PDF 文件
在对我们的 PDF 文档进行任何操作之前,我们必须从用户那里读取到该文档。在浏览器中读取任何文件都可以通过FileReader web API 来处理。
首先,我们要做一个文件输入按钮,然后用 FileReader web API 处理上传的文件。
<input
type="file"
id="file-selector"
accept=".pdf"
onChange="{onFileSelected}"
/>
由于 Filereader API 是使用回调的,我发现 async/await 要简明得多,也更容易操作。所以让我们做一个辅助函数,把 Filereader 的回调修改成 async/await。
function readFileAsync(file) {
return new Promise((resolve, reject) => {
let reader = new FileReader();
reader.onload = () => {
resolve(reader.result);
};
reader.onerror = reject;
reader.readAsArrayBuffer(file);
});
}
现在,当用户完成上传文件时,我们监听文件输入事件,然后使用这个 readFileAsync 函数读取文件。
这个逻辑的实现在代码中看起来像这样:
const onFileSelected = async (e) => {
const fileList = e.target.files;
if (fileList?.length > 0) {
const pdfArrayBuffer = await readFileAsync(fileList[0]);
}
};
如何提取 PDF 页面
到此为止,我们的 PDF 被上传并转换为 JavaScript ArrayBuffer。由于我们正在从 PDF 中提取一系列的页面,我们想要一个包含 PDF 中这些页码的数组。
在 JavaScript 中生成一个自然数的数组并不难。所以我们做了一个名为range()的函数来生成我们想要的所有索引。
我们必须提供起始页数和结束页数,然后这个range()函数就可以生成一个带有适当页数的数组。
function range(start, end) {
let length = end - start + 1;
return Array.from({ length }, (_, i) => start + i - 1);
}
在这里,我们在最后加上 -1。你知道原因是什么吗?在编程中,索引是从 0 开始的,而不是 1。所以我们必须从每一个页码中扣除 -1,以实现我们想要的效果。
现在让我们开始本文的主要部分:提取。在做任何工作之前,请导入 pdf-lib 库。
import { PDFDocument } from 'pdf-lib';
首先,我们加载我们从之前的 onFileSelected 函数得到的 PDF ArrayBuffer。然后我们把 ArrayBuffer 加载到 PDFDocument.load(arraybuffer) 函数中。这就是我们的用户提供的 PDF。为了方便起见,我们称它为 pdfSrcDoc。
现在我们将创建一个新的 PDF。所有从用户提供的文档中提取的 PDF 页面都被合并到新文档中。我们使用 PDFDocument.create() 函数来做这件事。为了便于使用,我们称它为 pdfNewDoc。
之后,我们使用 copyPages() 函数将我们想要的页面从 pdfSrcDoc 复制到 pdfNewDoc。然后我们将复制的页面添加到 pdfNewDoc 中。
要保存这些变化,运行 pdfNewDoc.save()。让我们创建一个名为 extractPdfPage() 的函数来重用这个逻辑。函数中的代码将看起来像这样:
async function extractPdfPage(arrayBuff) {
const pdfSrcDoc = await PDFDocument.load(arrayBuff);
const pdfNewDoc = await PDFDocument.create();
const pages = await pdfNewDoc.copyPages(pdfSrcDoc, range(2, 3));
pages.forEach((page) => pdfNewDoc.addPage(page));
const newpdf = await pdfNewDoc.save();
return newpdf;
}
我们从 extractPdfPage() 函数返回一个 Uint8Array。
如何在浏览器中渲染 PDF
到目前为止,我们有一个修改过的 PDF 的 Uint8Array。为了在你的浏览器中呈现它,我们必须把它转换成一个 Blob。
然后我们将它做成一个 URL,并在一个 iframe 中呈现。
你也可以使用我上面提到的 pdfjs 库制作你的自定义 PDF 浏览器。但如果你不需要显示品牌和定制,浏览器的默认 PDF 查看器就可以达到这个目的。
function renderPdf(uint8array) {
const tempblob = new Blob([uint8array], {
type: 'application/pdf'
});
const docUrl = URL.createObjectURL(tempblob);
setPdfFileData(docUrl);
}
现在你可以很容易地在一个 iframe 中渲染这个从 renderPdf() 函数返回的 docUrl。
完整的代码示例
我在本教程中使用 Next.js。如果你使用的是其他框架或 vanilla JavaScript,结果也会类似。下面是这个项目的所有代码:
import { useState } from 'react';
import { PDFDocument } from 'pdf-lib';
export default function Home() {
const [pdfFileData, setPdfFileData] = useState();
function readFileAsync(file) {
return new Promise((resolve, reject) => {
let reader = new FileReader();
reader.onload = () => {
resolve(reader.result);
};
reader.onerror = reject;
reader.readAsArrayBuffer(file);
});
}
function renderPdf(uint8array) {
const tempblob = new Blob([uint8array], {
type: 'application/pdf'
});
const docUrl = URL.createObjectURL(tempblob);
setPdfFileData(docUrl);
}
function range(start, end) {
let length = end - start + 1;
return Array.from({ length }, (_, i) => start + i - 1);
}
async function extractPdfPage(arrayBuff) {
const pdfSrcDoc = await PDFDocument.load(arrayBuff);
const pdfNewDoc = await PDFDocument.create();
const pages = await pdfNewDoc.copyPages(pdfSrcDoc, range(2, 3));
pages.forEach((page) => pdfNewDoc.addPage(page));
const newpdf = await pdfNewDoc.save();
return newpdf;
}
// 当用户选择一个文件时,执行以下代码
const onFileSelected = async (e) => {
const fileList = e.target.files;
if (fileList?.length > 0) {
const pdfArrayBuffer = await readFileAsync(fileList[0]);
const newPdfDoc = await extractPdfPage(pdfArrayBuffer);
renderPdf(newPdfDoc);
}
};
return (
<>
<h1>Hello world</h1>
<input
type="file"
id="file-selector"
accept=".pdf"
onChange={onFileSelected}
/>
<iframe
style={{ display: 'block', width: '100vw', height: '90vh' }}
title="PdfFrame"
src={pdfFileData}
frameborder="0"
type="application/pdf"
></iframe>
</>
);
}
现在你可以使用 PDF 查看器上的下载按钮保存生成的 PDF。
今后的发展方向
在这篇文章中,我只是触及了冰山一角。如果你想处理 PDF,并想从中获得一些东西,那么 pdf-lib 是一个非常强大的库,可以达到这个目的。
你可以将两个 PDF 合并成一个,你可以旋转页面,或者从一个 PDF 中删除一些页面。这些只是一些例子,可能性是无限的。
如果你想将你的 Next.js 应用程序部署到 Cloudflare 页面,你应该看看这篇文章。
你可以用它来做一些事情。做一些创造性的东西,并在 Twitter 上向我展示。
总结
如果你一直读到现在,我非常感激——感觉世界上另一个地方的人会读到我写的内容。请把文章分享给你的会写代码的朋友。
你想在你的 PDF 文档中添加一个大纲吗?我知道这是一个非常难实现的任务。我已经经历了很多痛苦,以用 JavaScript 在 PDF 文档中添加这个功能。你有兴趣吗?我会在未来介绍这个过程。
祝你愉快!