

原文:The definitive Node.js handbook,作者:Flavio Copes
注意:你可以得到这本手册的 PDF、ePub或Mobi 版本,以方便参考,或在你的 Kindle 或平板电脑上阅读。
Node.js 简介
本手册是 Node.js 的入门指南,它是服务器端 JavaScript 运行环境。
概况
Node.js 是一个 服务器 上的 JavaScript 运行环境。
Node.js 是开源的、跨平台的,自从2009年推出以来,它大受欢迎,现在在 Web 开发领域发挥着重要作用。如果 GitHub 的星星是一个流行的指示因素,那么拥有58000多颗星星就意味着非常流行。
Node.js 在浏览器之外运行 V8 JavaScript 引擎,这是 Chrome 浏览器的核心。Node.js 能够利用那些使 Chrome 浏览器的 JavaScript 运行变得非常快的成果,这使得 Node.js 能够从 V8 执行的巨大性能改进和即时编译中受益。得益于此,在 Node.js 中运行的 JavaScript 代码可以变得非常有性能。
一个 Node.js 应用程序是由一个单一的进程运行的(single process),不需要为每个请求创建一个新的线程(new thread)。Node在其标准库中提供了一套异步 I/O 原生语法,这将防止JavaScript 代码被阻塞,一般来说,Node.js 中的库是使用非阻塞范式编写的,使阻塞行为成为例外,而不是正常的。
当 Node.js 需要执行 I/O 操作时,比如从网络中读取数据、访问数据库或文件系统,而不是阻塞线程,Node.js 会在响应回来时恢复操作,而不是浪费 CPU 来等待。
这使得 Node.js 可以用一台服务器处理成千上万的并发连接,而不需要引入管理线程并发的负担,这将是错误的主要来源。
Node.js 有一个独特的优势,因为数百万为浏览器编写 JavaScript 的前端开发人员现在能够运行服务器端代码和前端代码,而不需要学习一种完全不同的语言。
在 Node.js 中,新的 ECMAScript 标准可以顺利使用,因为你不必等待所有用户更新他们的浏览器--你通过改变Node.js的版本来决定使用哪个 ECMAScript 版本,你还可以通过运行带有标志(flags)的 Node 来启用特定的实验性功能。
Node.js 有大量的库
凭借其简单的结构,Node包管理器(NPM)帮助 Node.js 的生态系统激增。现在,NPM registry 托管了近50万个开源包,你可以自由使用。
一个Node.js应用程序的例子
Node.js 最常见的例子 Hello World 是一个网络服务器:
const http = require('http')
const hostname = '127.0.0.1'
const port = 3000
const server = http.createServer((req, res) => {
res.statusCode = 200
res.setHeader('Content-Type', 'text/plain')
res.end('Hello World\n')
})
server.listen(port, hostname, () => {
console.log(`Server running at http://${hostname}:${port}/`)
})
要运行这个片段,将其保存为 server.js 文件,并在终端运行 node server.js。
这段代码首先包括 Node.js http模块。
Node.js有一个惊艳的 标准库,包括对网络的一流支持。
http 的 createServer() 方法创建一个新的HTTP服务器并返回。
该服务器被设置为在指定的端口和主机名上监听。当服务器准备好时,回调函数被调用,在这种情况下,通知我们服务器正在运行。
每当收到一个新的请求,request event 被调用,提供两个对象:一个请求(一个 http.IncomingMessage 对象)和一个响应(一个 http.ServerResponse 对象)。
这两个对象对于处理HTTP调用是必不可少的。
第一个对象提供请求的细节。在这个简单的例子中,这个没有被使用,但是你可以访问请求头和请求数据。
第二个对象是用来返回数据给调用者的。
在这种情况下:
res.statusCode = 200
我们将 "statusCode" 属性设置为 "200",以表示成功响应。
我们设置 Content-Type 头:
res.setHeader('Content-Type', 'text/plain')
……我们最后关闭响应,将内容作为一个参数添加到 end():
res.end('Hello World\n')
Node.js 框架和工具
Node.js 是一个低代码(low-level)平台。为了让开发者更容易、更有趣,成千上万的库被建立在Node.js 之上。
其中许多人随着时间的推移成为了流行的选择。这里有一个不全面的列表,列出了我认为非常相关和值得学习的那些:
- Express
创建一个网络服务器的最简单而强大的方法之一。它的极简方法和对服务器核心功能的无偏见关注是其成功的关键。 - Meteor
一个令人难以置信的强大的全栈框架,赋予你用JavaScript构建应用程序的同构方法,在客户端和服务器上共享代码。曾经是一个提供一切的现成工具,现在它与前端库如React、Vue 和 Angular 集成。Meteor也可以用来创建移动应用程序。 - Koa
由Express背后的同一个团队建立,Koa旨在更简单和更小,建立在多年的知识之上。这个新项目的诞生是由于需要在不破坏现有社区的情况下,创造不兼容的变化。 - Next.js
这是一个用于渲染服务器端的 React 应用程序的框架。 - Micro
这是一个非常轻量级的服务器,用于创建异步的HTTP微服务。 - Socket.io
这是一个实时通信引擎,用于构建网络应用。
Node.js 的简史
回顾 2009 年到今天的 Node.js 的历史
信不信由你,Node.js 只有 9 年的历史。
相比之下,JavaScript 有 23 年的历史,而我们所知的网络(在引入Mosaic之后)有25年的历史。
对于一项技术来说,9年的时间实在是太短了,但Node.js似乎已经存在了很久。
我有幸从 Node.js 的早期就开始工作,当时它只有2年的历史,尽管信息很少,但你已经可以感觉到它是一个巨大的东西。
在这一节中,我想画出 Node.js 在历史上的大图景,把事情看清楚。
一段小的历史
JavaScript 是一种编程语言,是在网景公司创建的,作为一种脚本工具,在他们的浏览器 Netscape Navigator 中操作网页。
网景公司的部分商业模式是销售网络服务器,其中包括一个名为 “Netscape LiveWire” 的环境,它可以使用服务器端的 JavaScript 创建动态页面。因此,服务器端JavaScript的想法并不是由 Node.js引入的,它就像 JavaScript 一样古老--但在当时它并不成功。
导致 Node.js 崛起的一个关键因素是时机。几年前,JavaScript 开始被认为是一种严肃的语言,这要归功于 “Web 2.0” 应用程序,它们向世界展示了网络上的现代体验是什么样的(想想谷歌地图或GMail)。
由于浏览器的竞争,JavaScript 引擎的性能标准大大提高了,这种竞争仍在继续。每个主要浏览器背后的开发团队每天都在努力工作,为我们提供更好的性能,这对 JavaScript 这个平台来说是一个巨大的胜利。Chrome V8,即 Node.js 背后使用的引擎,就是其中之一,特别是它的 Chrome JavaScript 引擎。
但当然,Node.js 的流行并不只是因为纯粹的运气或时机。它引入了许多关于如何在服务器上用 JavaScript 编程的创新思维。
2009
Node.js的诞生
第一种形式的 npm 的诞生
2010
Express 诞生
Socket.io 诞生
2011
npm达到1.0版本
Hapi 诞生
2012
被采用的速度非常快
2013
第一个使用 Node.js 的大型博客平台: Ghost
Koa 诞生
2014
大事件: IO.js 是 Node.js 的一个重要分叉,目标是引入ES6支持,并快速推进。
2015
Node.js 基金会 诞生
IO.js 回归到 Node.js 中
npm引入了私有模块
Node 4 发布(之前没有发布过1、2、3版本)
2016
Yarn 诞生:Node 6 发布
2017
npm 更专注于安全:Node 8 发布
V8 在其测试套件中引入了 Node,正式将 Node 作为除 Chrome 之外的 JavaScript 引擎的目标。
每周 30 亿次 npm 下载
2018
Node 10 发布
mjs 实验性支持
如何安装 Node.js
如何在你的系统上安装 Node.js:使用软件包管理器、官方网站安装程序或 nvm
Node.js 可以通过不同的方式进行安装。这篇文章强调了最常见和最方便的方式。
所有主要平台的官方软件包都可以使用这里。
安装 Node.js 的一个非常方便的方法是通过包管理器。在这种情况下,每个操作系统都有自己的。
在macOS上,Homebrew 是事实上的标准,而且一旦安装,就可以通过在 CLI 中运行这个命令,非常容易地安装 Node.js:
brew install node
其他用于 Linux 和 Windows 的软件包管理器被列出 这里。
nvm 是运行 Node.js 的一种流行方式。它允许你轻松地切换 Node.js 的版本,并安装新的版本来尝试,并在发生故障时轻松回滚,例如。
它对于用旧的 Node.js 版本测试你的代码也非常有用。
我的建议是,如果你刚刚开始,而且你还没有使用 Homebrew,就使用官方安装程序。否则,Homebrew是我最喜欢的解决方案。
使用 Node.js,你需要知道多少 JavaScript?
如果你刚刚开始学习 JavaScript,你需要对这门语言有多深的了解?
作为一个初学者,你很难达到对自己的编程能力有足够信心的程度。
在学习编程的过程中,你可能也会迷惑不解,到底哪里是 JavaScript 的终点,哪里是 Node.js 的起点,反之亦然。
我建议你在深入学习 Node.js 之前,先对主要的 JavaScript 概念有一个很好的掌握:
- Lexical Structure(语法结构)
- Expressions(表示式)
- Types (类型)
- Variables (变量)
- Functions (函数)
- this
- Arrow Functions (箭头函数)
- Loops (循环)
- Loops and Scope (循环和作用域)
- Arrays (数组)
- Template Literals (模板文字)
- Semicolons (分号)
- Strict Mode (严格模式)
- ECMAScript 6, 2016, 2017 (ES6 ES2016 ES2017标准)
有了这些概念,你就可以在浏览器和 Node.js 中成为一名熟练的 JavaScript 开发者了。
以下概念也是理解异步编程的关键,这也是 Node.js 的一个基本部分:
- 异步编程(Asynchronous programming)和回调(callbacks)
- 定时器(Timers)
- Promises
- Async and Await
- 闭包(Closures)
- 事件循环(The Event Loop)
幸运的是,我写了一本免费的电子书,解释了所有这些主题,它叫做 JavaScript基础知识。这是你能找到的学习所有这些的最紧凑的资源。
Node.js 和浏览器之间的差异
在 Node.js 中编写 JavaScript 应用程序与在浏览器内为网络编程有什么不同。
浏览器和 Node 都使用 JavaScript 作为其编程语言。
构建在浏览器中运行的应用程序与构建 Node.js 应用程序是完全不同的事情。
尽管它始终是 JavaScript,但有一些关键的区别,使体验有了根本的不同。
编写 Node.js 应用程序的前端开发者有一个巨大的优势--语言仍然是一样的。
你有一个巨大的机会,因为我们知道全面、深入地学习一门编程语言是多么困难。通过使用相同的语言来执行你在网络上的所有工作--无论是在客户端还是在服务器上--你就处于一个独特的优势地位。
生态系统的变化。
在浏览器中,大多数时候你所做的是与DOM或其他网络平台 API(如 Cookies )进行交互。当然,这些并不存在于 Node.js 中。你没有 document、window 和所有其他由浏览器提供的对象。
而且在浏览器中,我们没有 Node.js 通过其模块提供的所有好用的 API,如文件系统访问功能。
另一个很大的区别是,在 Node.js 中你可以控制环境。除非你正在构建一个任何人都可以在任何地方部署的开源应用程序,否则你知道你将在哪个版本的 Node.js 上运行该应用程序。与浏览器环境相比,你不能奢侈地选择你的访问者将使用什么浏览器。
这意味着你可以编写所有你的 Node 版本支持的现代 ES6-7-8-9 的 JavaScript。
由于 JavaScript 的发展如此之快,但浏览器可能有点慢,用户的升级也有点慢--有时在网络上,你只能使用旧的 JavaScript/ECMAScript 版本。
你可以使用 Babel 将你的代码转换为兼容 ES5 的版本,然后再运到浏览器上,但在 Node.js 中,你就不需要这样了。
另一个区别是,Node.js 使用 CommonJS 模块系统,而在浏览器中,我们开始看到 ES 模块标准被实施。
在实践中,这意味着你暂时在 Node.js 中使用 require(),而在浏览器中使用 import(译者注:Node 13.2.0 起开始正式支持 ES Modules,可以在 Node 中使用 import :)。
V8 JavaScript 引擎
V8 是谷歌浏览器的 JavaScript 引擎的名字。在使用 Chrome 浏览器浏览时,它能接收我们的JavaScript 并执行它。
V8 提供了运行时环境,在其中执行 JavaScript。DOM 和其他网络平台 API 是由浏览器提供的。
最酷的是,JavaScript 引擎是独立于它所承载的浏览器的。这一关键特征使 Node.js 的崛起成为可能。V8 早在2009年就被 Node.js 选择为引擎,随着 Node.js 的普及,V8成为现在为大量用JavaScript 编写的服务器端代码提供动力的引擎。
Node.js 的生态系统是巨大的,由于它的存在,V8也为桌面应用程序提供了动力,比如 Electron 等项目。
其他 JS 引擎
其他浏览器有自己的 JavaScript 引擎:
- Firefox使用 Spidermonkey
- Safari使用 JavaScriptCore (也叫Nitro)
- Edge使用 Chakra(译者注: 现在Edge放弃自己的引擎,使用chrome一样的引擎,即V8)
还有很多JavaScript引擎。
所有这些引擎都实现了ECMA ES-262标准,也叫ECMAScript,即JavaScript使用的标准。
对性能的追求
V8 是用 C++ 编写的,而且它在不断改进。它是可移植的,可以在 Mac、Windows、Linux 和其他一些系统上运行。
在这个 V8 介绍中,我将忽略 V8 的实现细节。它们可以在更权威的网站上找到,包括 V8官方网站,而且它们随着时间的推移而变化,往往是很大的变化。
V8一直在发展,就像周围的其他JavaScript引擎一样,以加快网络和 Node.js 生态系统的发展。
在网络上,有一场多年来一直在进行的性能竞赛,我们(作为用户和开发者)从这场竞争中获益良多,因为我们年复一年地得到更快和更优化的机器。
编译(Compilation)
一般来说,JavaScript 被认为是一种解释语言,但现代的 JavaScript 引擎不再只是解释JavaScript,而是对其进行编译。
这发生在 2009 年,当时 SpiderMonkey JavaScript 编译器被添加到 Firefox 3.5 中,每个人都遵循这个想法。
JavaScript 由V8内部编译,采用实时制(JIT)编译,以加快执行速度。
这可能看起来违反直觉,。但自从2004年谷歌地图问世以来,JavaScript 已经从一般执行几十行代码的语言发展到在浏览器中运行的几千到几十万行的完整应用程序。
我们的应用程序现在可以在浏览器中运行数小时,而不仅仅是一些表单验证规则或简单的脚本。
在这个新世界里,编译JavaScript是非常有意义的,因为虽然可能需要多花一点时间来让JavaScript就绪,但一旦完成,它的性能就会比纯粹的解释代码高得多。
如何退出 Node.js 程序
终止一个 Node.js 应用程序有多种方法。
在控制台中运行程序时,你可以用 ctrl-C 关闭它,但我想在这里讨论的是以编程方式退出。
让我们从最激烈的一个开始,看看为什么你最好不使用它。
process 核心模块提供了一个方便的方法,允许你以编程方式退出Node.js程序:process.exit()。
当 Node.js 运行这一行时,进程会立即被强制终止。
这意味着任何正在等待的回调,任何仍在发送的网络请求,任何文件系统访问,或写到 stdout 或 stderr 的进程--都将立即被强制地终止。
如果这对你来说是好的,你可以传递一个整数,向操作系统发出退出代码的信号:
process.exit(1)
默认情况下,退出代码是`0',这意味着成功。不同的退出代码有不同的含义,你可能想在自己的系统中使用这些代码,让程序与其他程序沟通。
你可以阅读更多关于退出代码的内容 这里。
你也可以设置 process.exitCode 属性:
process.exitCode = 1
而当程序后来结束时,Node.js 将返回该退出代码。
当所有的处理完成后,一个程序会优雅地退出。
很多时候,我们用 Node.js 启动服务器,比如这个 HTTP 服务器:
const express = require('express')
const app = express()
app.get('/', (req, res) => { res.send('Hi!')})
app.listen(3000, () => console.log('Server ready'))
这个程序永远不会结束。如果你调用 process.exit(),任何正在等待或运行的请求都会被终止。这是不好的。
在这种情况下,你需要给命令发送一个 `SIGTERM' 信号,并通过进程信号处理程序来处理:
注意: process 不需要 require,它是自带的。
const express = require('express')
const app = express()
app.get('/', (req, res) => { res.send('Hi!')})
app.listen(3000, () => console.log('Server ready'))
process.on('SIGTERM', () => {
app.close(() => {
console.log('Process terminated')
})
})
什么是信号?信号是一种便携式操作系统接口(POSIX)的互通系统:为了通知一个进程发生的事件而向其发送的通知。
SIGKILL 是告诉一个进程立即终止的信号,最好是像 process.exit() 那样。
SIGTERM 是告诉一个进程优雅地终止的信号。它是进程管理器发出的信号,如 upstart 或 supervisord 和其他的。
你可以从程序内部,在另一个函数中发送这个信号:
process.kill(process.pid, 'SIGTERM')
或者从另一个正在运行的Node.js程序,或者在你的系统中运行的任何其他应用程序,知道你想终止的进程的PID。
如何从 Node.js 读取环境变量
Node的 process 核心模块提供了 env 属性,它承载了所有在进程启动时设置的环境变量。
下面是一个访问 NODE_ENV 环境变量的例子,该变量默认设置为 development。
process.env.NODE_ENV // "development"
在脚本运行前将其设置为 production 将告诉 Node.js,这是一个生产环境。
以同样的方式,你可以访问你设置的任何自定义环境变量。
在哪里托管一个 Node.js 应用程序
一个 Node.js 应用程序可以被托管在很多地方,这取决于你的需求。
下面是一个非详尽的清单,当你想部署你的应用程序并使其可以公开访问时,你可以探索这些选项。
我将列出从最简单和受限制到更复杂和强大的选项。
最简单的选择:本地隧道
即使你有一个动态 IP,或者你在一个 NAT 下,你也可以部署你的应用程序,并使用本地隧道从你的计算机上提供请求。
这个选项适合于一些快速测试、演示产品或与一小部分人分享应用程序。
一个在所有平台上都可用的非常好的工具是 ngrok。
使用它,你只需输入 ngrok PORT,你想要的端口就会暴露在互联网上。你会得到一个 ngrok.io 的域名,但如果付费订阅,你可以得到一个自定义的 URL 以及更多的安全选项(记住,你的机器是向公共互联网开放的)。
你可以使用的另一项服务是 localtunnel。
零配置部署
Glitch
Glitch 是一个 playground,是一种比以往任何时候都更快地建立你的应用程序的方式,并看到它们在自己的 glitch.com 子域上运行。你目前不能拥有一个自定义域名,而且还有一些 限制,但它真的很适合做原型。它看起来很有趣(这是个优点),而且它不是一个傻瓜式的环境--你得到了 Node.js 的所有功能,一个 CDN,安全的证书存储,GitHub 导入/导出和更多。
由 FogBugz 和 Trello 背后的公司(以及 Stack Overflow 的共同创建者)提供。
我经常使用它来做演示。
Codepen
Codepen 是一个了不起的平台和社区。你可以创建一个有多个文件的项目,并以自定义域名进行部署。
Serverless
无服务器(Serverless)是一种发布应用的方式,而且完全没有服务器需要管理。无服务器是一种范式,你把你的应用发布为功能,它们在网络端点上做出响应(也叫FAAS--功能即服务)。
非常受欢迎的解决方案有:
它们都为在 AWS Lambda 和其他基于 Azure 或谷歌云的 FAAS 解决方案上发布,提供了一个抽象层。
PAAS
PAAS 是 Platform As A Service 的缩写。这些平台解决了很多你在部署应用时应该担心的事情。
Zeit Now
Zeit 是一个有趣的选择。你只需在终端输入 now,它就会负责部署你的应用程序。有一个有限制的免费版本,而付费版本则更强大。你只需忘记有一个服务器,你只需部署应用程序。
Nanobox
Heroku
Heroku 是一个神奇的平台。
这是一篇好文章,在Heroku上开始使用Node.js.
Microsoft Azure
Azure 是微软的云产品。
Google Cloud Platform
Google Cloud 是你的应用程序的一个了不起的结构。
他们有一个很好的Node.js文档部分.
Virtual Private Server(虚拟私有服务器)
在本节中,你会找到常见的选择,从友好到更不友好的顺序排列:
- Digital Ocean
- Linode
- Amazon Web Services, 我特别提到 Amazon Elastic Beanstalk,因为它抽象了一点 AWS 的复杂性。
因为他们提供了一个空的Linux机器,你可以在上面工作,所以这些没有具体的教程。
在VPS类别中还有很多选择,这些只是我使用的和我推荐的。
Bare metal(裸金属)
另一个解决方案是获得一个 裸机金属服务器,安装一个Linux发行版,把它连接到互联网上(或者每月租一个,比如你可以使用 虚拟裸金属服务)。
如何使用 Node.js REPL
REPL 是 Read-Evaluate-Print-Loop 的缩写,它是一种快速探索 Node.js 功能的好方法。
node 命令是我们用来运行 Node.js 脚本的命令:
node script.js
如果我们省略文件名,我们在 REPL 模式下使用它:
node
如果你现在在你的终端尝试一下,会发生这样的情况:
node
该命令保持在空闲模式,等待我们输入什么。
提示:如果你不确定如何打开你的终端,谷歌 “How to open terminal on
REPL正在等待我们输入一些JavaScript代码。
从简单的开始,然后按下 enter 键:
> console.log('test')
> test
> undefined
第一个值 test,是我们告诉控制台要打印的输出,然后我们得到 undefined,这是运行 console.log() 的返回值。
现在我们可以输入一行新的 JavaScript 了。
通过使用 tab 键完成自动补全
REPL最酷的地方是它是互动的。
当你写代码时,如果你按下 tab 键,REPL 将尝试自动完成你写的内容,以匹配你已经定义的变量或预定义的变量。
探索 JavaScript 对象
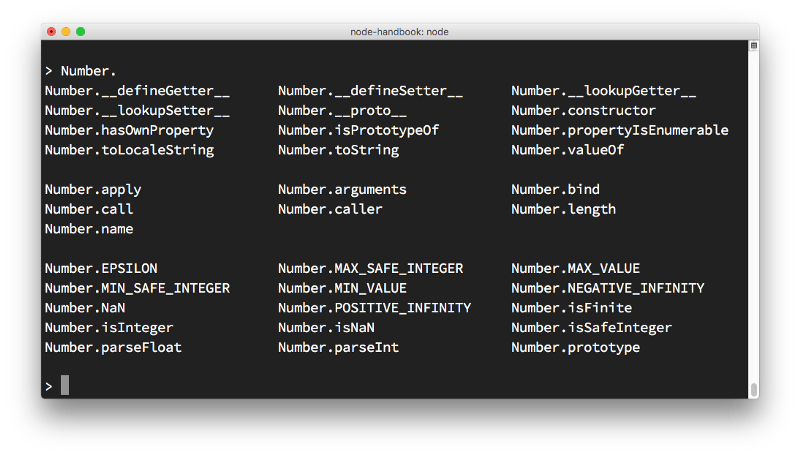
试着输入一个 JavaScript 类的名称,如 Number,加一个点,然后按 tab。
REPL将打印出你可以访问该类的所有属性和方法:
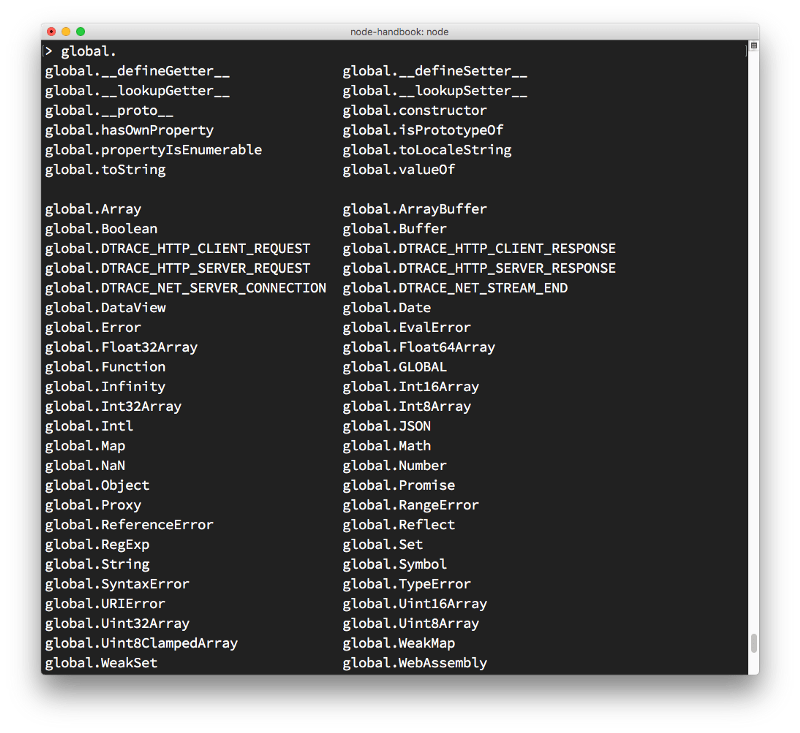
探索全局对象(global objects)
你可以通过输入 "global. "并按 "tab "来检查你可以访问的globals对象:
The _ special variable (特殊变量)
如果在一些代码之后,你输入_,这将会打印出最后一个操作的结果。
点命令(Dot commands)
REPL有一些特殊的命令,都以点.开头。它们是
.help: 显示点命令的帮助。.editor: 启用更多的编辑器,可以轻松地编写多行JavaScript代码。一旦你进入这个模式,输入ctrl-D就可以运行你写的代码。.break: 当输入一个多行表达式时,输入.break命令将中止继续输入。与按下ctrl-C相同。.clear: 将REPL上下文重置为空对象,并清除当前正在输入的任何多行表达式。.load: 加载一个JavaScript文件,相对于当前工作目录。.save: 将你在REPL会话中输入的所有内容保存到一个文件(指定文件名).exit: 退出repl(与按两次ctrl-C相同)
REPL知道你什么时候在输入一个多行语句,而不需要调用.editor。
例如,如果你开始键入一个迭代,像这样:
[1, 2, 3].forEach(num =>; {
并按下 "enter",REPL 将转到一个以 3 个点开始的新行,表明你现在可以继续在该块上工作。
... console.log(num)... })
如果你在一行的结尾处输入 .break,多行模式将停止,语句不会被执行。
Node.js,接受来自命令行的参数
如何在 Node.js 程序中接受从命令行传递的参数
在调用 Node.js 程序时,你可以使用以下方式传递任意数量的参数:
node app.js
参数可以是独立的,也可以有一个键和一个值。
例如:
node app.js flavio
或者
node app.js name=flavio
这改变了你在 Node.js 代码中检索该值的方式。
你检索它的方式是使用 Node.js 内置的 process 对象。
它暴露了一个 argv 属性,这是一个包含所有命令行调用参数的数组。
第一个参数是 node 命令的完整路径。
第二个元素是正在执行的文件的完整路径。
所有的附加参数都是从第三个位置开始往前出现。
你可以用一个循环遍历所有的参数(包括节点路径和文件路径):
process.argv.forEach((val, index) => {
console.log(`${index}: ${val}`)
})
你可以通过创建一个排除前两个参数的新数组,只获得额外的参数:
const args = process.argv.slice(2)
如果你有一个没有索引名称的参数,像这样:
node app.js flavio
你可以通过以下方式访问它
const args = process.argv.slice(2)
args[0]
在这种情况下:
node app.js name=flavio
args[0] 的值是 name=flavio,而你需要对它进行解析。最好的方法是使用 minimist,它有助于处理参数:
const args = require('minimist')(process.argv.slice(2))
args['name'] //flavio
使用 Node.js 输出到命令行
如何使用 Node.js 打印到命令行控制台,从基本的 console.log 到更复杂的情况。
使用控制台模块的基本输出
Node.js提供了一个 console模块,它提供了大量非常有用的方法来与命令行进行交互。
它基本上与你在浏览器中找到的 console 对象相同。
最基本和最常用的方法是 console.log(),它将你传递给它的字符串打印到控制台。
如果你传递一个对象,它将把它渲染成一个字符串。
你可以向 console.log 传递多个变量,例如:
const x = 'x'
const y = 'y'
console.log(x, y)
而 Node.js 会同时打印。
我们还可以通过传递变量和格式指定器来格式化短语,让它看起来更漂亮。
例如:
console.log('My %s has %d years', 'cat', 2)
%s格式化变量为字符串%d或者%i格式化变量为整数%f格式化一个变量为浮点数%O用于打印一个对象的表示方法
比如:
console.log('%O', Number)
清空控制台
console.clear() 清空控制台(其行为可能取决于所使用的控制台)
元素统计
console.count() 是一个很方便的方法。
以此代码为例:
const x = 1
const y = 2
const z = 3
console.count( 'The value of x is ' + x + ' and has been checked .. how many times?')
console.count( 'The value of x is ' + x + ' and has been checked .. how many times?')
console.count( 'The value of y is ' + y + ' and has been checked .. how many times?')
发生的情况是,count 将计算一个字符串被打印的次数,并在其旁边打印出计数。
你可以只统计 apples 和 oranges:
const oranges = ['orange', 'orange']
const apples = ['just one apple']
oranges.forEach(fruit => {console.count(fruit)})
apples.forEach(fruit => {console.count(fruit)})
打印堆栈跟踪
在有些情况下,打印一个函数的调用堆栈跟踪是很有用的,也许是为了回答这个问题。"你是如何到达代码的这一部分的?”
你可以使用 console.trace():
const function2 = () => console.trace()
const function1 = () => function2()
function1()
这将打印出堆栈跟踪。如果我在 Node REPL 中尝试这样做,会打印出以下内容:
Trace
at function2 (repl:1:33)
at function1 (repl:1:25)
at repl:1:1
at ContextifyScript.Script.runInThisContext (vm.js:44:33)
at REPLServer.defaultEval (repl.js:239:29)
at bound (domain.js:301:14)
at REPLServer.runBound [as eval] (domain.js:314:12)
at REPLServer.onLine (repl.js:440:10)
at emitOne (events.js:120:20)
at REPLServer.emit (events.js:210:7)
计算花费的时间
你可以使用 time() 和 timeEnd() 轻松计算出一个函数的运行时间。
const doSomething = () => console.log('test')
const measureDoingSomething = () => {
console.time('doSomething()') //do something, and measure the time it takes doSomething()
doSomething()
console.timeEnd('doSomething()')
}
measureDoingSomething()
stdout 和 stderr
正如我们所看到的,console.log 很适合在控制台中打印信息。这就是所谓的标准输出(stdout)。
console.error 打印到 stderr 流(stream)。
它不会出现在控制台,但会出现在错误日志中。
输出颜色
你可以通过使用转义序列给控制台中的文本输出着色。转义序列是一组标识颜色的字符。
Example:
console.log('\x1b[33m%s\x1b[0m', 'hi!')
你可以在 Node REPL 中尝试这样做,它将以黄色打印 hi!。
然而,这只是低级别的方法。为控制台输出着色的最简单方法是使用一个库。Chalk 就是这样一个库,除了着色之外,它还可以帮助其他的样式设计,比如将文本加粗、斜体或下划线。
你用 npm install chalk 安装它,然后你就可以使用它:
const chalk = require('chalk')
console.log(chalk.yellow('hi!'))
使用 chalk.yellow 比记住转义代码要方便得多,而且代码的可读性也很强。
查看我在上面发布的 Chalk 项目链接,了解更多的使用实例。
创建一个进度条
Progress 是一个很棒的软件包,可以在控制台中创建一个进度条。使用 npm install progress 来安装它。
这个片段创建了一个10步的进度条,每100毫秒完成一步。当进度条完成后,我们会清除间隔时间:
const ProgressBar = require('progress')
const bar = new ProgressBar(':bar', { total: 10 })
const timer = setInterval(() => {
bar.tick()
if (bar.complete) {
clearInterval(timer)
}
}, 100)
在 Node.js 中接受来自命令行的输入
如何使 Node.js CLI 程序具有交互性?
Node 从第7版开始就提供了 readline模块 来执行这个任务:从一个可读流中获取输入,比如 process.stdin 流,在 Node 程序的执行过程中,它就是终端输入,一次一个行。
const readline = require('readline')
.createInterface({
input: process.stdin, output: process.stdout
})
readline.question(`What's your name?\n`, (name) => {
console.log(`Hi ${name}!`)
readline.close()
})
这段代码询问用户名,一旦输入文本并且用户按了回车键,我们就会发送一个问候语。
question() 方法显示第一个参数(一个问题)并等待用户输入。一旦回车键被按下,它就会调用回调函数。
在这个回调函数中,我们关闭 readline 接口。
readline 提供了其他几个方法,我将让你在我上面 链接 文档中查看它们。
如果你需要要求一个密码,现在最好是回显它,而是显示一个*符号。
最简单的方法是使用 readline-sync,它在API方面非常相似,可以开箱即用。
一个更完整和抽象的解决方案是由 Inquirer.js 提供。
你可以用 npm install inquirer 来安装它,然后你可以像这样复制上面的代码:
const inquirer = require('inquirer')
const questions = [{ type: 'input', name: 'name', message: "What's your name?", }]
inquirer.prompt(questions).then(answers => {
console.log(`Hi ${answers['name']}!`)
})
Inquirer.js 可以让你做很多事情,比如问多个选择,有单选按钮,确认选项等等。
值得了解所有的替代方案,特别是 Node.js 提供的内置方案,但如果你打算将 CLI 输入提高到一个新的水平,Inquirer.js 是一个最佳选择。
使用 exports 从 Node.js 文件中暴露功能(Expose functionality)
如何使用 module.exports API 将数据暴露给你的应用程序中的其他文件,或者也暴露给其他应用程序。
Node.js 有一个内置的模块系统。
一个 Node.js 文件可以导入其他 Node.js 文件所暴露的功能。
当你想导入一些东西时,你可以使用:
const library = require('./library')
导入驻扎在当前文件夹中的 library.js 文件中所暴露的功能。
在这个文件中,功能必须在被其他文件导入之前被公开。
文件中定义的任何其他对象或变量默认为私有,不向外界公开。
这就是 module 系统提供的 module.exports API所允许我们做的。
当你把一个对象或一个函数指定为新的 exports 属性时,这就是被暴露的东西。因此,它可以被导入到你的应用程序的其他部分,或者其他应用程序中。
你可以通过2种方式做到这一点。
首先是给 module.exports 指定一个对象,这是一个由模块系统提供的开箱即用的对象,这将使你的文件只导出那个对象:
const car = { brand: 'Ford', model: 'Fiesta'}
module.exports = car
//..in the other file
const car = require('./car')
第二种方式是将导出的对象作为 exports 的一个属性。这种方式允许你导出多个对象、函数或数据:
const car = { brand: 'Ford', model: 'Fiesta'}
exports.car = car
或直接
exports.car = { brand: 'Ford', model: 'Fiesta'}
而在另一个文件中,你将通过引用你导入的一个属性来使用它:
const items = require('./items')items.car
或者
const car = require('./items').car
module.exports 和 exports 之间有什么区别?
前者暴露了 它所指向的对象。后者暴露了它所指向的对象的 属性。
npm 简介
npm 是 node 软件包管理器。
2017年1月,超过35万个软件包被报告列在 npm registry 中,使其成为地球上最大的单一语言代码库,你可以肯定有一个软件包用于(几乎!)一切。
它开始时是一种下载和管理Node.js包的依赖关系的方式,但后来它也成为了一个用于前端 JavaScript 的工具。
npm 做了很多事情。
下载
npm 管理你项目的依赖项下载。
安装所有的依赖项
如果一个项目有一个 packages.json 文件,通过运行
npm install
它将在 node_modules 文件夹中安装项目所需的一切,如果它不存在,则创建它。
安装单个软件包
你也可以通过运行以下命令来安装一个特定的软件包
npm install <package-name>
通常你会看到在这个命令中加入更多的标志(flags):
--save安装并添加条目到package.json文件中dependencies。--save-dev安装并添加条目到package.json文件devDependencies中。
区别主要在于,devDependencies 通常是开发工具,如测试库,而 dependencies 是与生产中的应用捆绑在一起的。
更新软件包
更新也很容易,通过运行
npm update
npm 将检查所有软件包是否有满足你的版本约束的较新版本。
你可以指定一个单独的软件包来更新:
npm update <package-name>
版本管理
除了普通的下载,npm 还管理版本,所以你可以指定一个包的任何特定版本,或者要求比你所需要的版本高或低。
很多时候,你会发现一个库只与另一个库的主要版本兼容。
或者一个库的最新版本中的一个bug,仍未被修复,导致了一个问题。
指定一个库的明确版本也有助于让每个人都处于同一个确切的软件包版本上,这样整个团队就会运行同一个版本,直到 package.json 文件被更新。
在所有这些情况下,版本管理都有很大帮助,npm 遵循语义版本管理(semver)标准。
运行任务
package.json 文件支持一种指定命令行任务的格式,可以通过使用
npm <task-name>
例如:
{
"scripts": {
"start-dev": "node lib/server-development",
"start": "node lib/server-production"
}
}
使用这个功能来运行Webpack是非常普遍的:
{
"scripts": {
"watch": "webpack --watch --progress --colors --config webpack.conf.js",
"dev": "webpack --progress --colors --config webpack.conf.js",
"prod": "NODE_ENV=production webpack -p --config webpack.conf.js",
}
}
因此,与其输入那些容易忘记或打错的长命令,你可以运行
npm watch
npm dev
npm prod
npm在哪里安装软件包?
当你使用npm(或 yarn)安装一个软件包时,你可以执行2种类型的安装:
- a local install (本地安装)
- a global install (全局安装)
默认情况下,当你输入一个 "npm install "命令时,例如:
npm install lodash
包被安装在当前文件树下的 node_modules 子文件夹中。
在这种情况下,npm 也会在当前文件夹中的 package.json 文件的 dependencies 属性中添加 lodash 条目。
使用 -g 标志进行全局安装:
npm install -g lodash
当这种情况发生时,npm 不会将软件包安装在本地文件夹下,而是会使用一个全局位置。
具体在哪里?
npm root -g 命令将告诉你该位置在你的机器上的确切位置。
在MacOS或Linux上,这个位置可以是 /usr/local/lib/node_modules。 在 Windows 上应该是C:\Users\YOU\AppData\Roaming\npm\node_modules
然而,如果你使用 nvm 来管理 Node.js 的版本,这个位置会有所不同。
例如,我使用 nvm,我的软件包位置显示为 /Users/flavio/.nvm/versions/node/v8.9.0/lib/node_modules。
如何使用或执行一个用 npm 安装的软件包
如何在你的代码中包含并使用安装在 node_modules 文件夹中的软件包
当你使用 npm 安装一个包到你的 node_modules 文件夹,或者全局安装,你如何在你的Node代码中使用它?
假设你安装了 lodash,一个流行的 JavaScript 工具库,使用
npm install lodash
这将在本地的 node_modules 文件夹中安装该软件包
要在你的代码中使用它,你只需要用 require 将它导入你的程序:
const _ = require('lodash')
如果你的软件包是一个可执行文件呢?
在这种情况下,它将把可执行文件放在 node_modules/.bin/ 文件夹下。
一个简单的演示, 使用 cowsay。
cowsay 软件包提供了一个命令行程序,执行该程序可以让一头牛说些什么(也可以是其他动物)。
当你使用 npm install cowsay 来安装这个包时,它将自己和一些依赖项安装在 node_modules 文件夹:
有一个隐藏的.bin文件夹,它包含cowsay二进制文件的符号链接。
你如何执行这些?
你当然可以输入 ./node_modules/.bin/cowsay 来运行它,它也可以工作,但是 npx,包括在最近版本的 npm 中(从5.2开始),是一个更好的选择。你只需运行:
npx cowsay
而npx会找到软件包的位置。
package.json 指南
package.json 文件是很多基于 Node.js 生态系统的应用代码库中的一个关键元素。
如果你用 JavaScript 工作,或者你曾经与一个 JavaScript 项目、Node.js 或前端项目互动,你肯定见过 package.json 文件。
那是做什么用的?你应该知道些什么,你可以用它做哪些很酷的事情?
package.json 文件是你项目的清单。它可以做很多事情,完全不相关。例如,它是一个工具配置的中央仓库。它也是 npm 和 yarn 存储它所安装的软件包的名称和版本的地方。
文件结构
下面是一个 package.json 文件的例子:
{}
它是空的! 对于一个应用程序来说,package.json 文件中应该包含什么并没有固定的要求。唯一的要求是遵循 JSON 格式,否则它不能被试图以编程方式访问其属性的程序读取。
如果你正在构建一个 Node.js 包,你想通过 npm 发布,事情就会发生根本性的变化,你必须有一套属性来帮助其他人使用它。我们将在后面看到更多关于这方面的内容。
这是另一个 package.json:
{ "name": "test-project"}
它定义了一个 name 属性,它告诉了这个文件所在的同一文件夹中包含的应用程序或包的名称。
这里有一个更复杂的例子,我从一个 Vue.js 应用样本中提取了这个例子:
{
"name": "test-project",
"version": "1.0.0",
"description": "A Vue.js project",
"main": "src/main.js",
"private": true,
"scripts": {
"dev": "webpack-dev-server --inline --progress --config build/webpack.dev.conf.js",
"start": "npm run dev",
"unit": "jest --config test/unit/jest.conf.js --coverage",
"test": "npm run unit",
"lint": "eslint --ext .js,.vue src test/unit",
"build": "node build/build.js"
},
"dependencies": {
"vue": "^2.5.2"
},
"devDependencies": {
"autoprefixer": "^7.1.2",
"babel-core": "^6.22.1",
"babel-eslint": "^8.2.1",
"babel-helper-vue-jsx-merge-props": "^2.0.3",
"babel-jest": "^21.0.2",
"babel-loader": "^7.1.1",
"babel-plugin-dynamic-import-node": "^1.2.0",
"babel-plugin-syntax-jsx": "^6.18.0",
"babel-plugin-transform-es2015-modules-commonjs": "^6.26.0",
"babel-plugin-transform-runtime": "^6.22.0",
"babel-plugin-transform-vue-jsx": "^3.5.0",
"babel-preset-env": "^1.3.2",
"babel-preset-stage-2": "^6.22.0",
"chalk": "^2.0.1",
"copy-webpack-plugin": "^4.0.1",
"css-loader": "^0.28.0",
"eslint": "^4.15.0",
"eslint-config-airbnb-base": "^11.3.0",
"eslint-friendly-formatter": "^3.0.0",
"eslint-import-resolver-webpack": "^0.8.3",
"eslint-loader": "^1.7.1",
"eslint-plugin-import": "^2.7.0",
"eslint-plugin-vue": "^4.0.0",
"extract-text-webpack-plugin": "^3.0.0",
"file-loader": "^1.1.4",
"friendly-errors-webpack-plugin": "^1.6.1",
"html-webpack-plugin": "^2.30.1",
"jest": "^22.0.4",
"jest-serializer-vue": "^0.3.0",
"node-notifier": "^5.1.2",
"optimize-css-assets-webpack-plugin": "^3.2.0",
"ora": "^1.2.0",
"portfinder": "^1.0.13",
"postcss-import": "^11.0.0",
"postcss-loader": "^2.0.8",
"postcss-url": "^7.2.1",
"rimraf": "^2.6.0",
"semver": "^5.3.0",
"shelljs": "^0.7.6",
"uglifyjs-webpack-plugin": "^1.1.1",
"url-loader": "^0.5.8",
"vue-jest": "^1.0.2",
"vue-loader": "^13.3.0",
"vue-style-loader": "^3.0.1",
"vue-template-compiler": "^2.5.2",
"webpack": "^3.6.0",
"webpack-bundle-analyzer": "^2.9.0",
"webpack-dev-server": "^2.9.1",
"webpack-merge": "^4.1.0"
},
"engines": {
"node": ">= 6.0.0",
"npm": ">= 3.0.0"
},
"browserslist": ["> 1%", "last 2 versions", "not ie <= 8"]
}
这里有很多的事情要做:
name设置应用程序/包的名称version设置应用程序/包的名称description是对应用程序/包的简要描述main设置应用程序的入口点private如果设置为true可以防止应用程序/软件包被意外地发布到npmscripts定义了一组你可以运行的node脚本dependencies设置一个作为依赖项安装的npm包的列表devDependencies设置一个作为开发依赖的npm包的列表engines设置该软件包/应用程序适用于哪些版本的 Nodebrowserslist用于告诉你要支持哪些浏览器(以及它们的版本)
所有这些属性都被 npm 或其他我们可以使用的工具所使用。
属性分类
本节详细描述了你可以使用的属性。我指的是 包(package),但同样的事情也适用于你不作为包使用的本地应用程序。
这些属性大多只在 npm网站 上使用,其他的由与你的代码交互的脚本使用,如 npm 或其他。
name
设置软件包的名称。
例如:
{"name": "test-project"}
该名称必须少于214个字符,不能有空格,只能包含小写字母、连字符(-)或下划线(_)。
这是因为当一个软件包在 npm 上发布时,它会根据这个属性获得自己的URL。
author
列出软件包作者的名字
例如:
{
"author": "Flavio Copes <flavio@flaviocopes.com> (https://flaviocopes.com)"
}
也可与此格式一起使用:
{
"author": {
"name": "Flavio Copes",
"email": "flavio@flaviocopes.com",
"url": "https://flaviocopes.com"
}
}
contributors
除了作者之外,该项目还可以有一个或多个贡献者。这个属性是一个数组,列出他们。
例如:
{
"contributors": ["Flavio Copes <flavio@flaviocopes.com> (https://flaviocopes.com)"]
}
也可与此格式一起使用:
{
"contributors": [{
"name": "Flavio Copes",
"email": "flavio@flaviocopes.com",
"url": "https://flaviocopes.com"
}]
}
bugs
链接到软件包的issues跟踪器,很可能是GitHub issues页面
比如:
{ "bugs": "https://github.com/flaviocopes/package/issues"}
homepage
设置软件包的主页
例子:
{ "homepage": "https://flaviocopes.com/package"}
version
表示软件包的当前版本。
例子:
{"version": "1.0.0"}
这个属性遵循版本的语义版本(semver)符号,这意味着版本总是用3个数字表示。x.x.x。
第一个数字是主要版本,第二个是次要版本,第三个是补丁版本。
这些数字是有意义的:一个只修复bug的版本是补丁版本,一个引入了向后兼容的变化的版本是次要版本,一个主要版本可以有突破性的变化。
license
表示该软件包的许可证。
例如:
{"license": "MIT"}
keywords
这个属性包含一个与你的包所做的事情相关联的关键词。
例如:
{"keywords": [ "email", "machine learning", "ai"]}
这有助于人们在浏览类似的软件包或浏览npm官网时找到你的软件包。
description
这个属性包含了对软件包的简要描述.
例如:
{"description": "A package to work with strings"}
如果你决定将你的软件包发布到npm上,这样人们就能发现软件包的内容,这就特别有用。
repository
这个属性指定了这个软件包仓库的位置。
例如:
{"repository": "github:flaviocopes/testing"}
注意github前缀。 还有其他受欢迎的服务::
{"repository": "gitlab:flaviocopes/testing"}
{"repository": "bitbucket:flaviocopes/testing"}
你可以明确地设置所使用的版本控制系统:
{"repository": { "type": "git", "url": "https://github.com/flaviocopes/testing.git"}}
你可以使用不同的版本控制系统:
{"repository": { "type": "svn", "url": "..."}}
main
设置包的入口点。
当你在一个应用程序中导入这个包时,应用程序就会在这里搜索模块的出口。
例如:
{"main": "src/main.js"}
private
如果设置为 "true",可以防止应用程序/软件包被意外地发布在 "npm" 上
例如:
{"private": true }
scripts
定义了一组你可以运行的 node 脚本
例如:
{
"scripts": {
"dev": "webpack-dev-server --inline --progress --config build/webpack.dev.conf.js",
"start": "npm run dev",
"unit": "jest --config test/unit/jest.conf.js --coverage",
"test": "npm run unit",
"lint": "eslint --ext .js,.vue src test/unit",
"build": "node build/build.js"
}
}
这些脚本是命令行应用程序。你可以通过调用 npm run XXXX 或 yarn XXXX 来运行它们,其中 XXXX 是命令名称。
例如:
npm run dev
你可以为命令使用任何你想要的名字,而且脚本可以做任何你想要的事情。
dependencies
设置一个作为依赖项安装的 npm 包的列表。
当你使用 npm 或 yarn 安装一个包时:
npm install <PACKAGENAME>
yarn add <PACKAGENAME>
该软件包会自动插入该列表中。
例如:
{"dependencies": { "vue": "^2.5.2"}}
devDependencies
设置一个作为开发依赖的 npm 包的列表。
它们与 dependencies 不同,因为它们只能安装在开发机器上,不需要在生产中运行代码。
当你使用 npm 或 yarn 安装一个包时:
npm install --dev <PACKAGENAME>
yarn add --dev <PACKAGENAME>
该软件包会自动插入该列表中。
比如:
{"devDependencies": { "autoprefixer": "^7.1.2", "babel-core": "^6.22.1"}}
engines
设置该软件包/应用程序适用于哪些版本的Node.js和其他命令。
例如:
{"engines": { "node": ">= 6.0.0", "npm": ">= 3.0.0", "yarn": "^0.13.0"}}
browserslist
是用来告诉你要支持哪些浏览器(以及它们的版本)。它被 Babel、Autoprefixer 和其他工具引用,只为你的目标浏览器添加所需的 polyfills(降级方案)和fallbacks(回退方案)。
例如:
{"browserslist": [ "> 1%", "last 2 versions", "not ie <= 8"]}
这种配置意味着你要支持所有至少有1%使用量的浏览器的最后两个主要版本(来自 CanIUse.com统计),但IE8和更低版本除外(见更多 浏览器列表)。
Command-specific properties
package.json 文件也可以承载特定命令的配置,例如 Babel、ESLint 等等。
每一个都有一个特定的属性,如 eslintConfig,babel 和其他。这些都是特定的命令,你可以在各自的命令/项目文档中找到如何使用它们。
Package versions
你在上面的描述中看到了这样的版本号。~3.0.0 或 ^0.13.0。它们是什么意思,你还可以使用哪些其他的版本指定符?
该符号指定了你的软件包接受哪些更新,来自该依赖关系。
鉴于使用semver(语义版本管理),所有的版本都有3位数字,第一位是主要版本,第二位是次要版本,第三位是补丁版本,你有这些规则:
~: 如果你写~0.13.0, 你想只更新补丁版本。0.13.1可以,但0.14.0不可以。^: 如果你写^0.13.0, 你想更新补丁和次要版本。0.13.1,0.14.0等等。*: 如果你写*, 这意味着你接受所有的更新,包括主要版本的升级。>: 你接受比你指定的版本高的任何版本。>=: 你接受任何等于或高于你指定的版本。<=: 你接受任何等于或低于你指定的版本。<: 你接受比你指定的版本低的任何版本。
也有其他规则:
no symbol:你只接受你指定的那个特定版本latest:你想使用最新的可用版本
你可以将上述大部分的范围结合起来,就像这样。1.0.0 || >=1.1.0 < 1.2.0,以使用1.0.0或1.1.0以上的一个版本,但低于1.2.0。
package-lock.json 文件
package-lock.json 文件是在安装 Nodo包时自动生成的。
在版本5中,NPM 引入了 package-lock.json 文件。
那是什么?你可能知道 package.json 文件,它更常见,存在的时间也更长。
该文件的目的是跟踪每一个安装的软件包的确切版本,这样,即使软件包被维护者更新,产品也能以同样的方式100%重现。
这解决了 package.json 未解决的一个非常具体的问题。在 package.json 中,你可以使用 semver 注解来设置你想升级到哪个版本(补丁或小版本),例如:
- 如果你写
~0.13.0, 你想只更新补丁版本。0.13.1可以,但0.14.0不行。 - 如果你写
^0.13.0, 你想更新补丁和次要版本。0.13.1,0.14.0等等。 - 如果你写
0.13.0, 这就是将被使用的确切版本,永远都是0.13.0。
你不会向 Git 提交你的 node_modules 文件夹,它通常是巨大的,当你试图通过使用 npm install 命令在另一台机器上复制项目时,如果你指定了~语法,并且一个包的补丁版本已经发布,那就会被安装。对于 ^ 和次要版本也是如此。
如果你指定了准确的版本,如例子中的 "0.13.0",你就不会受到这个问题的影响。
可能是你,也可能是另一个人在世界的另一端试图通过运行 npm install 来初始化这个项目。
所以你的原始项目和新初始化的项目实际上是不同的。即使一个补丁或小版本不应该引入破坏性的变化,我们都知道bug可以(所以,他们会)潜入。
package-lock.json 将你当前安装的每个软件包的版本in stone上,npm 在运行 npm install 时将使用这些确切的版本。
这个概念并不新鲜,其他编程语言的包管理器(如 PHP 中的 Composer)多年来也使用类似的系统。
package-lock.json 文件需要提交到你的 Git 仓库,如果项目是公开的或者你有合作者,或者你使用 Git 作为部署的来源,那么它可以被其他人取走。
当你运行 npm update 时,依赖的版本将在 package-lock.json 文件中更新。
一个例子
这是一个 package-lock.json 文件的结构示例,当我们在一个空的文件夹中运行 npm install cowsay 时,我们得到了这个文件:
{
"requires": true, "lockfileVersion": 1, "dependencies": {
"ansi-regex": { "version": "3.0.0", "resolved": "https://registry.npmjs.org/ansi-regex/-/ansi-regex-3.0.0.tgz", "integrity": "sha1-7QMXwyIGT3lGbAKWa922Bas32Zg=" }, "cowsay": { "version": "1.3.1", "resolved": "https://registry.npmjs.org/cowsay/-/cowsay-1.3.1.tgz", "integrity": "sha512-3PVFe6FePVtPj1HTeLin9v8WyLl+VmM1l1H/5P+BTTDkMAjufp+0F9eLjzRnOHzVAYeIYFF5po5NjRrgefnRMQ==", "requires": { "get-stdin": "^5.0.1", "optimist": "~0.6.1", "string-width": "~2.1.1", "strip-eof": "^1.0.0" } }, "get-stdin": { "version": "5.0.1", "resolved": "https://registry.npmjs.org/get-stdin/-/get-stdin-5.0.1.tgz", "integrity": "sha1-Ei4WFZHiH/TFJTAwVpPyDmOTo5g=" }, "is-fullwidth-code-point": { "version": "2.0.0", "resolved": "https://registry.npmjs.org/is-fullwidth-code-point/-/is-fullwidth-code-point-2.0.0.tgz", "integrity": "sha1-o7MKXE8ZkYMWeqq5O+764937ZU8=" }, "minimist": { "version": "0.0.10", "resolved": "https://registry.npmjs.org/minimist/-/minimist-0.0.10.tgz", "integrity": "sha1-3j+YVD2/lggr5IrRoMfNqDYwHc8=" }, "optimist": {
"version": "0.6.1", "resolved": "https://registry.npmjs.org/optimist/-/optimist-0.6.1.tgz", "integrity": "sha1-2j6nRob6IaGaERwybpDrFaAZZoY=",
"requires": { "minimist": "~0.0.1", "wordwrap": "~0.0.2" }
}, "string-width": { "version": "2.1.1", "resolved": "https://registry.npmjs.org/string-width/-/string-width-2.1.1.tgz", "integrity": "sha512-nOqH59deCq9SRHlxq1Aw85Jnt4w6KvLKqWVik6oA9ZklXLNIOlqg4F2yrT1MVaTjAqvVwdfeZ7w7aCvJD7ugkw==", "requires": { "is-fullwidth-code-point": "^2.0.0", "strip-ansi": "^4.0.0" } }, "strip-ansi": { "version": "4.0.0", "resolved": "https://registry.npmjs.org/strip-ansi/-/strip-ansi-4.0.0.tgz", "integrity": "sha1-qEeQIusaw2iocTibY1JixQXuNo8=", "requires": { "ansi-regex": "^3.0.0" } }, "strip-eof": { "version": "1.0.0", "resolved": "https://registry.npmjs.org/strip-eof/-/strip-eof-1.0.0.tgz", "integrity": "sha1-u0P/VZim6wXYm1n80SnJgzE2Br8=" }, "wordwrap": { "version": "0.0.3", "resolved": "https://registry.npmjs.org/wordwrap/-/wordwrap-0.0.3.tgz", "integrity": "sha1-o9XabNXAvAAI03I0u68b7WMFkQc=" }
}
}
我们安装了 cowsay,它依赖于:
get-stdinoptimiststring-widthstrip-eof
反过来,这些软件包需要其他的软件包,我们可以从 "requires "属性中看到,有些软件包有:
ansi-regexis-fullwidth-code-pointminimistwordwrapstrip-eof
它们按字母顺序被添加到文件中,每一个都有一个 version 字段,一个指向软件包位置的 resolved 字段,以及一个 integrity 字符串,我们可以用来验证该软件包。
查找一个npm包的安装版本
查看所有安装的 npm 包的最新版本,包括它们的依赖关系:
npm list
例如:
❯ npm list/Users/flavio/dev/node/cowsay
└─┬ cowsay@1.3.1
├── get-stdin@5.0.1
├─┬ optimist@0.6.1
│ ├── minimist@0.0.10
│ └── wordwrap@0.0.3
├─┬ string-width@2.1.1
├── is-fullwidth-code-point@2.0.0
│ └─┬ strip-ansi@4.0.0
│ └── ansi-regex@3.0.0
└── strip-eof@1.0.0
你也可以直接打开 package-lock.json 文件,但这涉及一些用眼睛查看。
npm list -g 也是一样的,只是针对全局安装的软件包。
要想只得到你的顶层软件包(基本上是你告诉 npm 安装的和你在 package.json 中列出的那些),运行 npm list --depth=0:
❯ npm list --depth=0/Users/flavio/dev/node/cowsay
└── cowsay@1.3.1
你可以通过指定名称来获得一个特定软件包的版本:
❯ npm list cowsay/Users/flavio/dev/node/cowsay
└── cowsay@1.3.1
这也适用于你安装的软件包的依赖性:
❯ npm list minimist/Users/flavio/dev/node/cowsay
└─┬ cowsay@1.3.1
└─┬ optimist@0.6.1
└── minimist@0.0.10
如果你想查看npm仓库中软件包的最新可用版本,运行npm view [package_name] version:
❯ npm view cowsay version
1.3.1
安装一个旧版本的 npm 包
安装一个旧版本的 npm 包可能对解决兼容性问题有帮助。
你可以使用 @ 语法来安装一个npm包的旧版本:
npm install <package>@<;version>
例如:
npm install cowsay
安装1.3.1版本(在撰写本文时)。
安装1.2.0 版本:
npm install cowsay@1.2.0
同样的情况也可以用全局包来做:
npm install -g webpack@4.16.4
你也可能对列出一个包的所有以前的版本感兴趣。你可以用 npm view <package> versions 来做:
❯ npm view cowsay versions
[ '1.0.0', '1.0.1', '1.0.2', '1.0.3', '1.1.0', '1.1.1', '1.1.2', '1.1.3', '1.1.4', '1.1.5', '1.1.6', '1.1.7', '1.1.8', '1.1.9', '1.2.0', '1.2.1', '1.3.0', '1.3.1' ]
将所有 Node 的依赖关系更新为最新版本
当你使用 npm install <packagename> 安装一个软件包时,该软件包的最新可用版本会被下载并放在 node_modules文件夹 中,并且在你当前文件夹中的package.json 和 package-lock.json 文件中添加相应条目。
npm会计算依赖关系,并安装那些最新的可用版本。
假设你安装了 [cowsay][85],一个很酷的命令行工具,可以让你让cow(牛)说东西。
当你 npm安装cowsay 时,这个条目被添加到 package.json 文件中:
{ "dependencies": { "cowsay": "^1.3.1" }}
这是 package-lock.json 的摘录,为了清晰起见,我把嵌套的依赖关系去掉了:
{
"requires": true,
"lockfileVersion": 1,
"dependencies": {
"cowsay": {
"version": "1.3.1",
"resolved": "https://registry.npmjs.org/cowsay/-/cowsay-1.3.1.tgz",
"integrity": "sha512-3PVFe6FePVtPj1HTeLin9v8WyLl+VmM1l1H/5P+BTTDkMAjufp+0F9eLjzRnOHzVAYeIYFF5po5NjRrgefnRMQ==",
"requires": {
"get-stdin": "^5.0.1",
"optimist": "~0.6.1",
"string-width": "~2.1.1",
"strip-eof": "^1.0.0"
}
}
}
}
现在这2个文件告诉我们,我们安装了cowsay的1.3.1版本,而我们的更新规则是 ^1.3.1,对于npm的版本规则(后面会解释)意味着npm可以更新到补丁和小版本。0.13.1,0.14.0,以此类推。
如果有一个新的次要版本或补丁版本,我们输入 npm update,安装的版本就会被更新,package-lock.json 文件就会勤奋地填上新的版本。
package.json 保持不变。
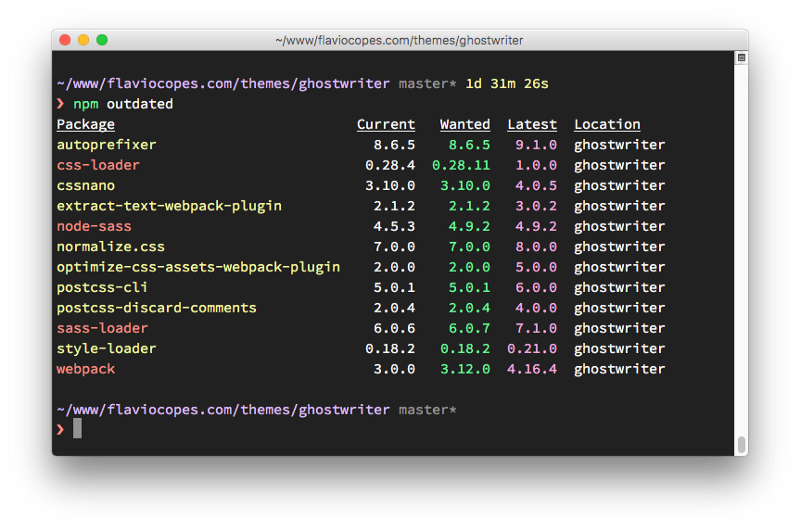
为了发现新发布的软件包,你可以运行 npm outdated。
下面是我很久没有更新的一个软件库中的一些过时的软件包的列表:
其中一些更新是主要版本。运行 npm update 不会更新这些版本。主要版本从不以这种方式更新,因为它们(顾名思义)会带来破坏性的变化,而 npm 想为你省去麻烦。
要将所有软件包更新到新的主要版本,请在全局安装 npm-check-updates 包:
npm install -g npm-check-updates
然后运行:
ncu -u
这将升级 package.json 文件中的所有版本提示,到 dependencies 和 devDependencies,所以 npm 可以安装新的主要版本(major version)。
现在你已经准备好运行更新:
npm update
如果你刚下载的项目没有 node_modules 的依赖,你想先安装全新版本,只要运行
npm install
使用 npm 进行语义版本管理
语义版本管理(Semantic Versioning)是一种用来为版本提供意义的惯例。
如果说Node.js包中有什么了不起的东西,那就是所有的人都同意使用语义版本控制(Semantic Versioning)来进行版本编号。
语义版本控制的概念很简单:所有的版本都有3位数字。x.y.z。
- 第一个数字是主版本(major version)
- 第二位数字是次要版本 (minor version)
- 第三位数字是补丁版本 (patch version)
当你制作一个新的版本时,你不会随心所欲地提高一个数字,而是有规则的:
- 当你对API进行不兼容的修改时,你要提高主版本的等级
- 当你以向后兼容的方式增加功能时,你要提高次要版本的数量
- 当你进行向后兼容的 bug 修复时,你要提高补丁版本
这个惯例在所有的编程语言中都被采用,而且每个 npm 包都要遵守这个惯例,这一点非常重要,因为整个系统都依赖于此。
为什么这么重要?
因为 npm 设置了一些规则,我们可以在 package.json文件 中使用,以便在运行 npm update 时,选择它可以将我们的软件包更新到哪些版本。
规则使用这些符号:
^~=>=<<==-||
让我们看看这些规则的细节:
^: 如果你写^0.13.0,当运行npm update, 它可以更新到补丁(patch)和次要版本(minor version):0.13.1,0.14.0等。~: 如果你写~0.13.0, 当运行npm update,它可以更新到补丁(patch):0.13.1是可以的, 但0.14.0不行。>: 你接受比你指定的版本高的任何版本>=: 你接受任何等于或高于你指定的版本<=: 你接受任何等于或低于你指定的版本<: 你接受比你指定的版本低的任何版本=: 你接受确切的版本-: 你接受一定范围的版本。例如:2.1.0 - 2.6.2||: 你结合一组。例如:< 2.1 || > 2.6
你可以结合这些符号,例如使用 1.0.0 || >=1.1.0 <1.2.0 来表示使用 1.0.0 或 1.1.0 以上的一个版本,但低于1.2.0。
也有其他规则:
no symbol:你只接受你指定的那个特定版本(1.2.1)。latest:你想使用最新的可用版本
在本地或全球范围内卸载 npm 包
要卸载你以前本地安装的软件包(使用 npm install <package-name> 在 node_modules 文件夹下),请运行:
npm uninstall <package-name>
使用 -S 标志,或 --save,这个操作也将删除 package.json 文件 中的引用。
如果软件包是一个开发依赖,列在 package.json 文件的 devDependencies 中,你必须使用 -D/--save-dev 标志从文件中删除它:
npm uninstall -S <package-name>
npm uninstall -D <package-name>
如果软件包在全局范围内**安装,你需要添加 -g/--global 标志:
npm uninstall -g <package-name>
例如:
npm uninstall -g webpack
你可以在你系统的任何地方运行这个命令,因为你目前所在的文件夹并不重要。
全局或本地软件 npm 包
一个软件包最好在什么时候全局安装?以及为什么?
本地包和全局包的主要区别:
- 本地包 安装在你运行
npm install <package-name>的目录下,并且它们被放在这个目录下的 node_modules 文件夹中。 - 全局包 都放在你系统中的一个地方(具体位置取决于你的设置),不管你在哪里运行
npm install -g <package-name>。
在你的代码中,它们都是以同样的方式被导入:
require('package-name')
那么,你应该在什么时候以一种或另一种方式安装呢?
一般来说,所有的软件包都应该以本地包的方式安装。
这可以确保你的电脑中可以有几十个应用程序,如果需要的话,都可以运行每个软件包的不同版本。
更新全局软件包会使你的所有项目都使用新的版本,你可以想象这可能会在维护方面造成噩梦,因为一些软件包可能会破坏与其他依赖的兼容性,等等。
所有的项目都有自己的本地包,即使这看起来是一种资源的浪费,但与可能产生的负面影响相比,它是微不足道的。
当一个软件包提供了一个可执行的命令,你可以从shell(CLI)中运行,并且在不同的项目中重复使用时,它应该被全局地安装。
你也可以在本地安装可执行命令,并使用 npx 运行它们,但有些软件包最好是全局安装。
你可能知道的流行的全局软件包的很好的例子:
npmcreate-react-appvue-cligrunt-climochareact-native-cligatsby-cliforevernodemon
你的系统中可能已经有一些全局安装的软件包。你可以通过运行:
npm list -g --depth 0
在你的终端.
npm dependencies(依赖关系) 和 devDependencies(开发依赖关系)
一个包什么时候是依赖关系,什么时候是开发依赖关系?
当你使用 npm install <package-name> 安装一个 npm 包时,你是把它为一个依赖。
该包会自动列在 package.json 文件的 dependencies 列表中(从 npm 5 开始:在你必须手动指定 --save 之前)。
当你添加 -D 标志,或 --save-dev 时,你就把它作为一个开发依赖项来安装,这就把它添加到 devDependencies 列表中。
开发依赖是指仅用于开发的软件包,在生产中不需要。例如,测试包、webpack 或 Babel。
当你在 生产环境 中时,如果你输入 npm install,并且该文件夹包含 package.json 文件,它们就会被安装(译者注: devDependencies 的 npm 包也会被安装),因为 npm 认为这是一个开发部署。
你需要设置 --production flag (npm install --production),以避免安装这些开发依赖项。
npx Node包运行器
npx 是一种非常酷的运行 Node.js 代码的方式,并提供了许多有用的功能。
在本节中,我想介绍一个非常强大的命令,从2017年7月发布的5.2版本开始,npm 中就有这个命令,npx。
如果你不想安装 npm,你可以将 npx 作为一个 独立的包 来安装。
npx 让你运行用 Node.js 构建并通过 npm 注册表发布的代码。
轻松地运行本地命令
Node.js 的开发者曾经将大多数可执行的命令作为全局包发布,以便让它们添加到系统的路径(path)中并可以执行。
这是一种痛苦,因为你无法真正安装同一命令的不同版本。
运行 npx commandname 会自动在项目的 node_modules 文件夹中找到该命令的正确引用,不需要知道确切的路径,也不需要在全局和用户的路径中安装包。
免安装的命令执行
npm 还有一个很好的功能,就是允许运行命令而不需要先安装它们。
这相当有用,主要是因为:
- 你不需要安装任何东西
- 你可以使用语法
@version来运行同一命令的不同版本
使用 npx 的一个典型示范是通过 cowsay 命令。cowsay 将打印一头牛,说你在命令中写的东西。比如:
cowsay "Hello" 将打印出
< Hello >
-------
\ ^__^
\ (oo)\_______
(__)\ )\/\
||----w |
|| ||
现在,这需要你之前从npm全局安装了 cowsay 命令,否则当你试图运行该命令时,你会得到一个错误。
npx 允许你在没有本地安装的情况下运行该npm命令:
npx cowsay "Hello"
现在,这是一个有趣的无用命令。其他情况包括:
- 运行
vue CLI工具来创建新的应用程序并运行它们:npx vue create my-vue-app - 使用
create-react-app创建一个新的React应用:npx create-react-app my-react-app
以及更多。
一旦下载,下载的代码将被抹去。
使用不同的 Node.js 版本运行一些代码
使用 @ 来指定版本,并将其与 node npm 包相结合:
npx node@6 -v #v6.14.3
npx node@8 -v #v8.11.3
这有助于避免像 nvm 或其他 Node 版本管理工具的使用。
直接从 URL 中运行任意的代码片段
npx 并不仅能运行在npm注册表上发布的软件包。
你可以运行位于 GitHub gist 中的代码,例如:
npx https://gist.github.com/zkat/4bc19503fe9e9309e2bfaa2c58074d32
当然,在运行不受你控制的代码时,你需要小心,因为巨大的权力伴随着巨大的责任。
The Event Loop(事件循环)
事件循环是了解JavaScript的最重要的方面之一。本节解释了JavaScript如何在单线程中工作的内部细节,以及它如何处理异步函数。
我已经用JavaScript编程多年了,但我从来没有 完全 理解过事情是如何在幕后运作的。不了解这个概念的细节是完全可以的。但是像往常一样,知道它是如何工作的是很有帮助的,而且在这一点上你可能只是有点好奇。
你的JavaScript代码是单线程(single threaded)运行的。每次只有一件事在发生。
这是一个实际上非常有帮助的限制,因为它简化了很多你编程的方式,而不用担心并发问题。
你只需要注意如何写你的代码,避免任何可能阻塞线程的东西,比如同步网络调用或无限 循环。
一般来说,在大多数浏览器中,每个浏览器标签都有一个事件循环,以使每个进程都被隔离,避免一个有无限循环的网页或繁重的处理过程阻塞你整个浏览器。
该环境管理着多个并发的事件循环,以处理例如API调用。Web Workers 也是在自己的事件循环中运行。
你主要需要关注的是,你的代码会在一个事件循环中运行,写代码时要考虑到这个事情,避免阻塞它。
阻塞事件循环
任何 JavaScript 代码,如果需要花费太长的时间将控制权返回到事件循环中,就会阻断页面中任何 JavaScript 代码的执行,甚至阻断UI线程,用户就无法点击、滚动页面,等等。
JavaScript 中几乎所有的 I/O 原生语句都是无阻塞的。如网络请求、Node.js 文件系统操作,等等。阻塞是个例外,这就是为什么 JavaScript 如此基于回调,以及最近的 promises 和 async/await 的原因。
The call stack(调用栈)
调用栈是一个 LIFO 队列(Last In, First Out)。
事件循环不断检查调用栈(call stack),看是否有任何函数需要运行。
在这样做的同时,它将发现的任何函数调用添加到调用栈中,并按顺序执行每个函数。
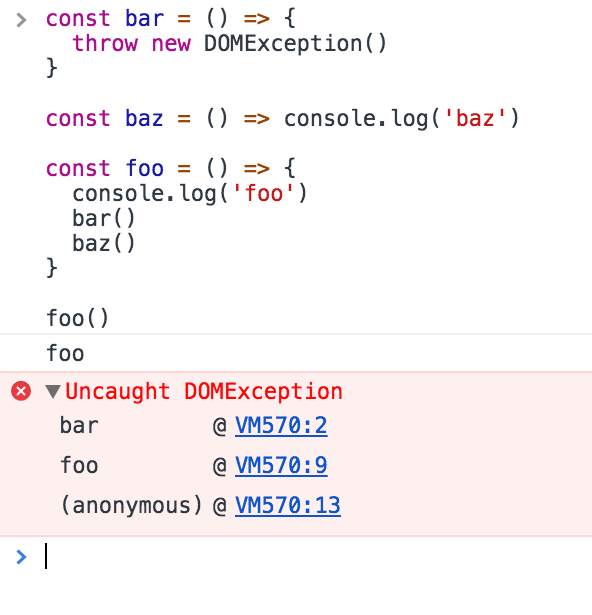
你知道你可能熟悉的错误堆栈跟踪,在调试器或浏览器控制台中?
浏览器查找调用堆栈中的函数名称,以告知你当前调用是由哪个函数发起的:
一个简单的事件循环解释
举个例子:
const bar = () => console.log('bar')
const baz = () => console.log('baz')
const foo = () => {
console.log('foo')
bar()
baz()
}
foo()
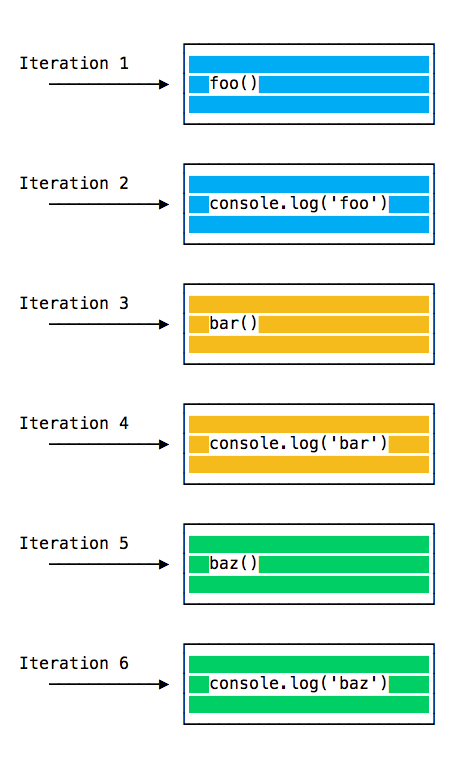
这段代码打印出:
foo
bar
baz
正如预期的那样。
当这段代码运行时,首先调用 foo()。在 foo() 中,我们首先调用 bar(),然后我们调用baz()。
在这一点上,调用栈看起来像这样:
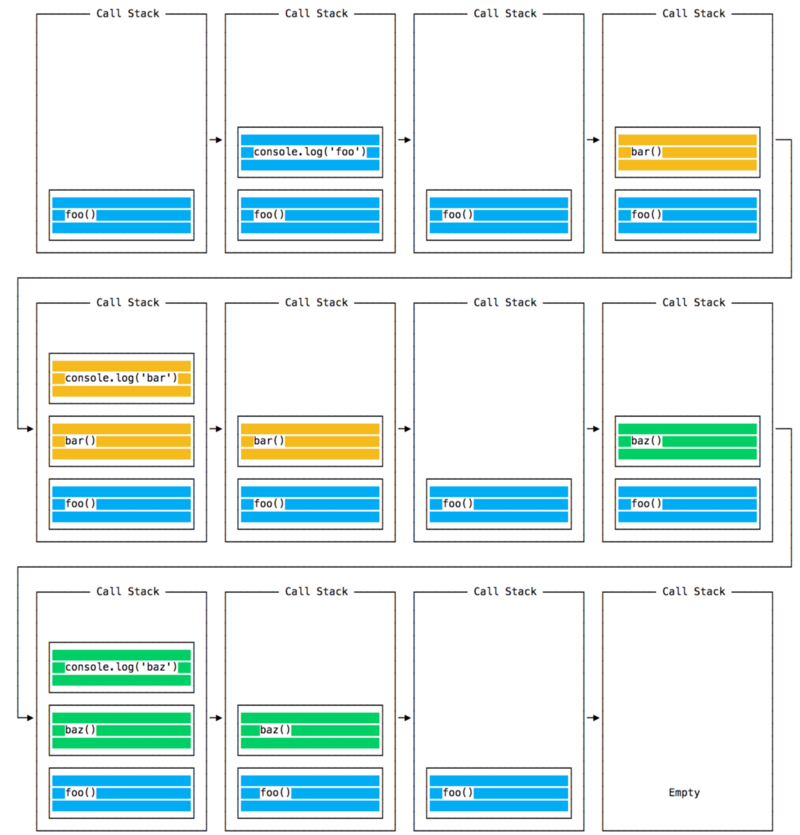
事件循环在每个迭代中都会查看调用栈中是否有东西,并执行它:
直到调用栈为空。
排列函数执行
上面的例子看起来很正常,没有什么特别的地方。JavaScript找到要执行的东西,按顺序运行它们。
我们来看看如何推迟一个函数,直到堆栈清空。
setTimeout(() => {},0) 的用例是调用一个函数,但要在代码中的其他函数都执行完后再执行它。
以此为例:
const bar = () => console.log('bar')
const baz = () => console.log('baz')
const foo = () => {
console.log('foo')
setTimeout(bar, 0)
baz()
}
foo()
这段代码的打印结果,也许是令人惊讶的:
foo
baz
bar
当这段代码运行时,首先 foo() 被调用。在 foo() 中,我们首先调用 setTimeout,传递 bar 作为参数,我们指示它立即尽可能快地运行,传递 0 作为计时器。然后我们调用 baz()。
在这一点上,调用栈看起来像这样:
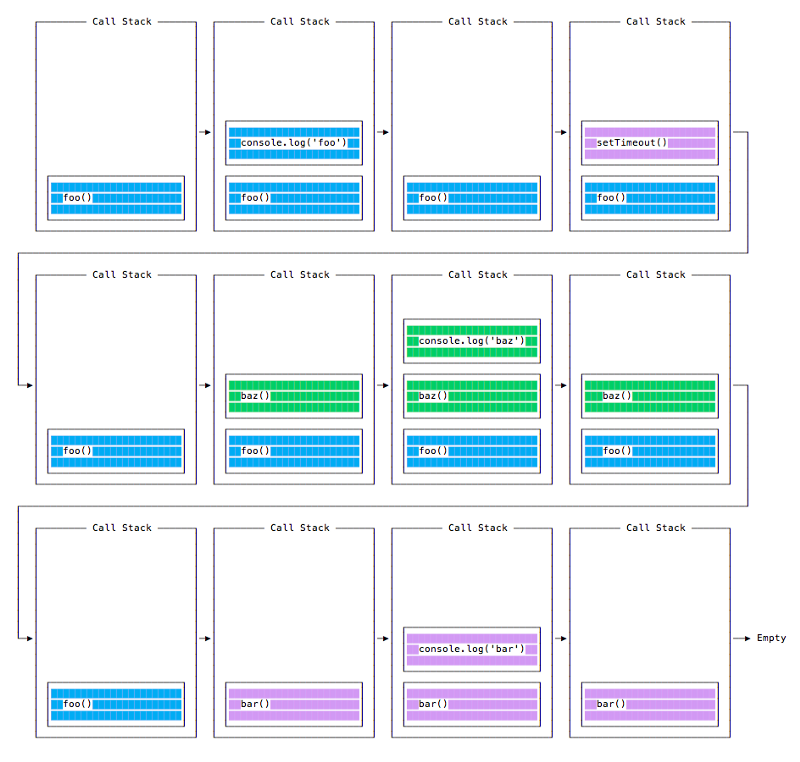
以下是我们程序中所有函数的执行顺序:
为什么会发生这种情况?
消息队列
当 setTimeout() 被调用时,浏览器或Node.js开始计时。一旦定时器过期,在这种情况下,由于我们把 0 作为超时,回调函数就会被放到消息队列中。
消息队列也是用户启动的事件(如点击和键盘事件或获取响应)在您的代码有机会对其做出反应之前排队的地方。 或者像 onLoad 这样的 DOM 事件。
循环优先考虑调用栈。 它首先处理它在调用栈中找到的所有内容,一旦那里没有任何内容,它就会去获取消息队列中的内容。
我们不必等待像 setTimeout、fetch或其他东西的函数来做它们自己的工作,因为它们是由浏览器提供的,而且它们生活在自己的线程上。例如,如果你把 setTimeout 的超时时间设为2秒,你就不必等待2秒,等待发生在其他地方。
ES6 Job Queue(ES6任务队列)
ECMAScript 2015引入了Job Queue的概念,Promises(也在ES6/ES2015中引入)也使用了这个概念。这是一种尽快执行异步函数结果的方法,而不是放在调用栈的最后。
在当前函数结束之前解析的 Promise 将在当前函数之后立即执行。
我觉得用游乐园的过山车来比喻很好:消息队列让你回到队列中,排在所有其他人之后,而工作队列是一张快速通行票,让你在完成前一项工作后马上再坐一次。
Example:
const bar = () => console.log('bar')
const baz = () => console.log('baz')
const foo = () => {
console.log('foo')
setTimeout(bar, 0)
new Promise((resolve, reject) => resolve('should be right after baz, before bar'))
.then(resolve => console.log(resolve))
bar()
}
foo()
这打印出:
foo
baz
should be right after foo, before barbar
这是Promises(以及建立在Promises 之上的 async/await)和通过 setTimeout() 或其他平台API的普通异步函数之间的巨大区别。
理解process.nextTick()
当你试图理解Node.js的事件循环时,它的一个重要部分是 process.nextTick()。它以一种特殊的方式与事件循环互动。
每当事件循环进行一次完整的旅行,我们称它为tick。
当我们向 process.nextTick() 传递一个函数时,我们指示引擎在当前操作结束时,在下一个事件循环tick开始前调用这个函数:
process.nextTick(() => {
//do something
})
事件循环正忙于处理当前的函数代码。
当这个操作结束时,JavaScript引擎会运行该操作期间传递给 nextTick 调用的所有函数。
这是我们可以告诉JavaScript引擎异步处理一个函数的方法(在当前函数之后),但要尽快,不要排队。
调用 setTimeout(() => {}, 0) 将在下一个tick中执行该函数,比使用 nextTick() 时晚得多。
当你想确保在下一个事件循环迭代中,代码已经被执行时,使用 nextTick()。
了解 setImmediate()
当你想异步执行一些代码,但又想尽快执行时,一个选择是使用 Node.js 提供的 setImmediate() 函数:
setImmediate(() => {
//run something
})
作为 setImmediate() 参数传递的函数都是一个回调,会在事件循环的下一次迭代中执行。
setImmediate() 与 setTimeout(() => {}, 0)(传递0ms的超时)和 from process.nextTick() 有何不同?
传递给 process.nextTick() 的函数将在事件循环的当前迭代中执行,在当前操作结束后。这意味着它将总是在 setTimeout() 和 setImmediate() 之前执行。
具有0ms延迟的 setTimeout() 回调与 setImmediate() 非常相似。执行顺序取决于各种因素,但它们都将在事件循环的下一次迭代中运行。
定时器
在编写JavaScript代码时,你可能想延迟一个函数的执行。学习如何使用 setTimeout() 和 setInterval() 来安排未来的函数。
setTimeout()
在编写JavaScript代码时,你可能想延迟一个函数的执行。这就是 setTimeout 的工作。
你可以指定一个稍后执行的回调函数,以及一个表达你希望它多长时间运行的值,单位是毫秒:
setTimeout(() => {
//do something
}, 2000)// runs after 2 seconds
setTimeout(() => {
//do something
}, 50)// runs after 50 milliseconds
这种语法定义了一个新的函数。你可以在这里调用任何你想调用的其他函数,或者你可以传递一个现有的函数名和一组参数:
const myFunction = (firstParam, secondParam) => {
// do something
}
setTimeout(myFunction, 2000, firstParam, secondParam)// runs after 2 seconds
setTimeout() 返回定时器ID。这通常是不使用的,但你可以存储这个ID,如果你想删除这个预定函数的执行,可以清除它:
const id = setTimeout(() => {
// should run after 2 seconds
}, 2000)
clearTimeout(id) // 取消定时器
Zero delay(零延迟)
如果你指定超时延迟为 0,回调函数将尽快执行,但在当前函数执行之后:
setTimeout(() => {
console.log('after ')
}, 0)
console.log(' before ')
将打印出 before after.
这对于避免在密集型任务上阻塞CPU,并在执行繁重的计算时让其他函数被执行,通过在调度器中排队的函数特别有用。
一些浏览器(IE 和 Edge)实现了一个 setImmediate() 方法,可以实现这个完全相同的功能,但它不是标准的,在其他浏览器上不可用。但它是 Node.js 的一个标准函数。
setInterval()
setInterval() 是一个类似于 setTimeout() 的函数,但有一点不同。它不是运行一次回调函数,而是在你指定的特定时间间隔(以毫秒为单位)永远运行它:
setInterval(() => {
// runs every 2 seconds
}, 2000)
上面的函数每2秒运行一次,除非你用 clearInterval 告诉它停止,并把 setInterval 返回的定时器id传给它:
const id = setInterval(() => {
// runs every 2 seconds
}, 2000)
通常在 setInterval 回调函数中调用 clearInterval,让它自动判断是否应该再次运行或停止。例如,这段代码在 App.somethingIWait 的值为 arrived 时才运行。
const interval = setInterval(function() {
if (App.somethingIWait === 'arrived') {
clearInterval(interval)
}}, 100)// otherwise do things
递归设置超时
setInterval 每隔 n 毫秒启动一个函数,完全不考虑函数何时执行完毕。
如果一个函数花费的时间总是一样的,那就没问题了:

也许该函数需要不同的执行时间,取决于网络条件,例如:

也许一个长期执行的项目会与下一个项目重叠:

为了避免这种情况,你可以安排一个递归的setTimeout,当回调函数完成时被调用:
const myFunction = () => { // do something
setTimeout(myFunction, 1000)
}
setTimeout(myFunction()}, 1000)
实现这一设想:

setTimeout 和 setInterval 在 Node.js 中也可以使用,通过 Timer模块。
Node.js还提供了 setImmediate(),相当于使用 setTimeout(() => {}, 0),主要用于与 Node.js 事件循环一起工作。
异步编程(Asynchronous Programming)和回调(Callbacks)
JavaScript 默认是同步的,而且是单线程的。这意味着,代码不能创建新的线程,也不能并行运行。
编程语言中的异步性
计算机在设计上是异步的。
异步的意思是,事情可以独立于主程序流程而发生。
在目前的消费类计算机中,每个程序都在一个特定的时间段内运行,然后它停止执行,让另一个程序继续执行。这件事的运行周期非常快,不可能注意到,我们认为我们的计算机同时运行许多程序,但这是一种错觉(除了在多处理器机器上)。
程序在内部使用中断,这是一种向处理器发出的信号,以获得系统的处理。
我不会去研究这个的内部情况,但只要记住,程序是异步的,在需要注意之前停止执行是正常的,计算机可以在这期间执行其他事情。当一个程序在等待来自网络的响应时,它不能停止处理器,直到请求完成。
通常情况下,编程语言是同步的,有些语言提供了一种管理异步性的方法,在语言中或通过库。C、Java、C#、PHP、Go、Ruby、Swift、Python,它们默认都是同步的。其中一些语言通过使用线程来处理异步性,生成一个新的进程。
JavaScript
JavaScript 默认是同步的,并且是单线程的。 这意味着代码无法创建新线程并并行运行。
代码行一个接一个地依次执行。
例如:
const a = 1
const b = 2
const c = a * b
console.log(c)
doSomething()
但是 JavaScript 是在浏览器内部诞生的。 一开始,它的主要工作是响应用户操作,如 onClick、onMouseOver、onChange、onSubmit 等。 它如何使用同步编程模型做到这一点?
答案就在它的环境中。 浏览器通过提供一组可以处理此类功能的 API 来提供一种方法。
最近,Node.js 引入了非阻塞 I/O 环境,将这一概念扩展到文件访问、网络调用等。
Callbacks(回调)
你不可能知道用户何时会点击一个按钮,所以你要做的是为点击事件定义一个事件处理程序。
这个事件处理程序接受一个函数,当事件被触发时,该函数将被调用:
document.getElementById('button')
.addEventListener('click', () => {
console.log('button clicked')
})//item clicked
这就是所谓的回调。
回调是一个简单的函数,它作为一个值传递给另一个函数,只有当事件发生时才会被执行。我们可以这样做,因为JavaScript有的函数是一等公民,它可以被分配给变量并传递给其他函数(称为高阶函数)。
常见的做法是将所有的客户端代码包裹在 "window "对象的 "load "事件监听器中,只有当页面准备好时才运行回调函数:
window.addEventListener('load', () => {})//window loaded //do what you want
回调无处不在,不仅仅是在DOM事件中使用。
一个常见的例子是通过使用定时器:
setTimeout(() => {
// runs after 2 seconds
}, 2000)
XHR请求 也接受回调,在这个例子中,通过给一个属性分配一个函数,当一个特定的事件发生时(在这个例子中,请求的状态改变),该函数将被调用:
const xhr = new XMLHttpRequest()
xhr.onreadystatechange = () => {
if (xhr.readyState === 4) {
xhr.status === 200 ? console.log(xhr.responseText) : console.error('error')
}}
xhr.open('GET', 'https://yoursite.com')
xhr.send()
处理回调中的错误
你如何用回调来处理错误?一个很常见的策略是使用 Node.js 采用的方法:任何回调函数的第一个参数是错误对象,错误优先的回调。
如果没有错误,该对象是 null。如果有错误,它包含一些错误的描述和其他信息。
fs.readFile('/file.json', (err, data) => {
if (err !== null) { //handle error
console.log(err)
return
}
console.log(data) //no errors, process data
})
使用回调会遇到的问题
回调非常适合简单的情况!
但是,每个回调都会增加一层嵌套。 当你有很多回调时,代码很快就会变得复杂:
window.addEventListener('load', () => {
document.getElementById('button')
.addEventListener('click', () => {
setTimeout(() => {
items.forEach(item => {})
}, 2000)
}) //your code here
})
这只是一个简单的4级代码,但我见过更多级别的嵌套,这很不好玩。
我们如何解决这个问题呢?
回调的替代方案
从ES6开始,JavaScript 引入了几个功能,帮助我们处理不涉及使用回调的异步代码:
- Promises (ES6)
- Async/Await (ES8)
Promises
Promises 是处理 JavaScript 中异步代码的一种方式,而不需要在代码中写太多的回调。
Promises 简介
承诺通常被定义为一个最终会变得可用的值的代理。
虽然已经存在多年,但它们在 ES2015 中被标准化并引入,现在它们在 ES2017 中被 async 函数所取代。
**异步函数(Async functions)**使用 Promise API 作为其构建模块,因此,即使在较新的代码中,你可能会使用异步函数而不是 Promise,理解它们也是基本的。
Promises是如何工作的
一旦一个 Promises 被调用,它将开始处于待定状态。这意味着调用者函数继续执行,同时等待 Promises 做它自己的处理,并给调用者函数一些反馈。
在这一点上,调用者函数等待它在**解决的状态(resolved state)下返回promises,或者在拒绝的状态(rejected state)**下返回 Promises,但是你知道 JavaScript 是异步的,所以函数继续执行,而承诺在做它的工作。
哪些 JS API 使用 Promises?
除了你自己的代码和库的代码外,Promises 还被标准的现代网络 API 所使用,如:
- the Battery API
- the Fetch API
- Service Workers
在现代 JavaScript 中,你发现自己不可能不使用承诺,所以让我们直接开始研究它们。
创建 Promise
Promise API 暴露了一个 Promise 构造函数,你可以使用 new Promise() 来初始化它:
let done = true
const isItDoneYet = new Promise( (resolve, reject) => {
if (done) {
const workDone = 'Here is the thing I built'
resolve(workDone)
} else {
const why = 'Still working on something else'
reject(why)
}
})
正如你所看到的,承诺会检查 done 全局常量,如果是真的,我们会返回一个已解决(resolved)的 Promise,否则就是拒绝(rejected )的 resolved 。
使用 resolve 和 reject 我们可以返回一个值,在上面的例子中我们只是返回一个字符串,但也可以是一个对象。
消费(Consuming)Promise
在上一节中,我们介绍了如何创建一个 Promise。
现在让我们来看看promise如何被消费或使用。
const isItDoneYet = new Promise()//...
const checkIfItsDone = () => {
isItDoneYet.then((ok) => {console.log(ok)})
.catch((err) => {console.error(err)})
}
运行 checkIfItsDone() 将执行 isItDoneYet() 承诺,并等待它的解析,使用 then 回调,如果有错误,它将在 catch 回调中处理。
链式 Promises
一个 Promise 可以返回给另一个 Promise,形成一个 Promise 链。
Fetch API 给出了一个很好的 Promise 链的例子,它是 XMLHttpRequest API 上面的一层,我们可以用它来获取一个资源,并在获取资源的时候排队执行一连串的 Promise。
Fetch API是一个基于promise的机制,调用 fetch() 等同于使用 new Promise() 定义我们自己的 Promise。
Promises链的例子
const status = (response) => {
if (response.status >= 200 && response.status < 300)
{ return Promise.resolve(response) }
return Promise.reject(new Error(response.statusText))}
const json = (response) => response.json()
fetch('/todos.json')
.then(status)
.then(json)
.then((data) => {console.log('Request succeeded with JSON response', data)})
.catch((error) => { console.log('Request failed', error) })
在这个例子中,我们调用 fetch() 从当前目录中找到的 todos.json 文件中获得一个 TODO 项目的列表,并且我们创建了一个 Promises 链。
运行 fetch() 返回一个 response,它有许多属性,在这些属性中我们引用了:
status, 一个代表HTTP状态代码的数字值statusText, 一个状态信息,如果请求成功,就是OK
response 也有一个 json() 方法,它返回一个 Promise,该 Promise 将对 body 的内容进行处理并转化为 JSON。
所以在这些前提下,会发生这样的事情:链中的第一个 Promise是我们定义的一个函数,叫做status(),它检查响应状态,如果不是一个成功的响应(在200和299之间),它拒绝这个 Promise(rejects the promise)。
这个操作将导致承诺链跳过所有列出的链式 Promise,直接跳到底部的 catch() 语句,记录 Request failed 文本和错误信息。
如果成功了,它会调用我们定义的 json() 函数。由于前一个 Promise 在成功时返回了 response 对象,我们得到它作为第二个 Promise 的输入。
在这种情况下,我们返回经过处理的 JSON 数据,所以第三个 Promise 直接接收 JSON:
.then((data) => {
console.log('Request succeeded with JSON response', data)
})
我们只需将其记录到控制台。
处理错误
在上一节的例子中,我们有一个附加到 Promise 链上的 catch。
当 Promise 链中的任何东西失败并引发错误或拒绝 Promise 时,控制就会转到链下最近的 catch() 语句。
new Promise((resolve, reject) => {
throw new Error('Error')})
.catch((err) => { console.error(err) })
或者这样写
new Promise((resolve, reject) => {
reject('Error')})
.catch((err) => { console.error(err) })
Cascading(层叠)errors
如果在 catch() 里面你引发了一个错误,你可以附加第二个 catch() 来处理它,以此类推。
new Promise((resolve, reject) => {throw new Error('Error')})
.catch((err) => { throw new Error('Error') })
.catch((err) => { console.error(err) })
Orchestrating(协调) Promises
Promise.all()
如果你需要同步不同的 Promise,Promise.all() 可以帮助你定义一个 Promise 列表,并在它们都被解决(resolved)后执行一些操作。
例如:
const f1 = fetch('/something.json')
const f2 = fetch('/something2.json')
Promise.all([f1, f2])
.then((res) => {console.log('Array of results', res)})
.catch((err) => {console.error(err)})
ES2015的析构赋值 语法允许你也这样做:
Promise.all([f1, f2])
.then(([res1, res2]) => {
console.log('Results', res1, res2)
})
当然,你并不局限于使用 fetch,任何 Promise 都可以使用。
Promise.race()
Promise.race() 在你传递给它的第一个 Promise 得到解决时运行,它只运行一次所附的回调,并使用第一个 Promise 的解决结果。
例如:
const first = new Promise((resolve, reject) => {
setTimeout(resolve, 500, 'first')
})
const second = new Promise((resolve, reject) => {
setTimeout(resolve, 100, 'second')
})
Promise.race([first, second]).then((result) => {
console.log(result)
})// second
Common error, Uncaught TypeError: undefined is not a promise
如果你在控制台得到 Uncaught TypeError: undefined is not a promise,请确保你使用 new Promise(),而不是仅仅使用 Promise()。
Async and Await
探索 JavaScript 中异步函数的现代方法。
JavaScript在很短的时间内从回调(callback)发展到了 Promise(ES2015),而从ES2017开始,异步 JavaScript 通过 async/await 语法变得更加简单。
异步函数是 Promises 和生成器(generators)的结合,基本上,它们是 Promises 的更高层次的抽象。让我重复一遍:async/await 是建立在 Promises 之上的。
为什么会引入 async/await?
它们减少了围绕 Promises 的模板, 以及链式 Promises 的 don’t break the chain 的限制。
当 Promises 在 ES2015 中被引入时,它们旨在解决异步代码的问题,而且它们确实做到了,但在 ES2015 和 ES2017 之间的两年时间里,显然 Promises 不可能成为最终的解决方案。
Promises 的引入是为了解决著名的回调地狱(callback hell)问题,但它们本身就引入了复杂性,而且是语法上的复杂性。
它们是很好的基元(primitives),围绕它们可以向开发者展示更好的语法,所以当时机成熟的时候,我们得到了同步函数(async functions)。
它们使代码看起来是同步的,但在幕后却是异步的和非阻塞的。
它是如何工作的
一个 "async" 函数会返回一个 Promise,比如在这个例子中:
const doSomethingAsync = () => {
return new Promise((resolve) => {
setTimeout(() => resolve('I did something'), 3000)
})
}
当你想调用这个函数时,你要在前面加上 await,调用代码将停止直到承诺被解决或拒绝(promise is resolved or rejected)。有一点需要注意:客户端函数必须定义为 async。
这是一个例子:
const doSomething = async () => {
console.log(await doSomethingAsync())
}
一个简短的例子
这是一个简单的 async/await 的例子,用于异步运行一个函数:
const doSomethingAsync = () => {
return new Promise((resolve) => {
setTimeout(() => resolve('I did something'), 3000)
})
}
const doSomething = async () => {
console.log(await doSomethingAsync())
}
console.log('Before')
doSomething()
console.log('After')
上述代码将向浏览器控制台打印以下内容:
Before
After
I did something //after 3s
Promise all the things
在任何函数前加上 async 关键字意味着该函数将返回一个 promise。
即使它没有明确地这样做,也会在内部使其返回一个promise。
这就是为什么这段代码是有效的:
const aFunction = async () => { return 'test'}
aFunction().then(alert) // This will alert 'test'
跟下面的是相同的:
const aFunction = async () => {
return Promise.resolve('test')
}
aFunction().then(alert) // This will alert 'test'
代码阅读起来更简单
正如你在上面的例子中看到的,我们的代码看起来非常简单。与使用普通承诺的代码相比,它有链式和回调函数。
而这只是一个非常简单的例子,主要的好处将出现在代码更复杂的时候。
例如,这里是你如何获得一个JSON资源并解析它,使用 Promises:
const getFirstUserData = () => {
return fetch('/users.json') // get users list
.then(response => response.json()) // parse JSON
.then(users => users[0]) // pick first user
.then(user => fetch(`/users/${user.name}`)) // get user data
.then(userResponse => response.json()) // parse JSON
}
getFirstUserData()
这里是用以下方式提供的相同功能,通过使用 await/async:
const getFirstUserData = async () => {
const response = await fetch('/users.json') // get users list
const users = await response.json() // parse JSON const user = users[0] // pick first user
const userResponse = await fetch(`/users/${user.name}`) // get user data
const userData = await user.json() // parse JSON return userData
}
getFirstUserData()
串联多个的异步函数
async 函数可以很容易地串联起来,而且语法比普通的 Promises 更易读:
const promiseToDoSomething = () => { return
new Promise(resolve => {
setTimeout(() => resolve('I did something'), 10000)
}
)}
const watchOverSomeoneDoingSomething = async () => {
const something = await promiseToDoSomething()
return something + ' and I watched'
}
const watchOverSomeoneWatchingSomeoneDoingSomething = async () => {
const something = await watchOverSomeoneDoingSomething()
return something + ' and I watched as well'
}
watchOverSomeoneWatchingSomeoneDoingSomething().then((res) => {
console.log(res)
})
将会打印:
I did something and I watched and I watched as well
更容易调试
调试 Promises 是很难的,因为调试器不会在异步代码上断点。
async/await 使之变得非常容易,因为对编译器来说,它就像同步代码。
Node.js 事件发送器(Event Emitter)
你可以在 Node.js 中使用自定义事件。
如果你在浏览器中使用 JavaScript,你就知道用户的大部分交互是通过事件处理的:鼠标点击、键盘按键、对鼠标移动的反应等等。
在后端,Node.js为我们提供了使用 events模块 建立类似系统的选择。
这个模块特别提供了 EventEmitter 类,我们将用它来处理我们的事件。
你可以用以下方式初始化它:
const eventEmitter = require('events').EventEmitter()
这个对象暴露了 on 和 emit 方法,以及其他许多方法。
emit用于触发一个事件。on用于添加一个回调函数,当事件被触发时将被执行。
例如,让我们创建一个start事件,作为提供一个样本的问题,我们对该事件的反应只是记录到控制台:
eventEmitter.on('start', () => {
console.log('started')
})
当我们运行:
eventEmitter.emit('start')
事件处理函数被触发,我们得到控制台日志。
你可以通过将参数作为附加参数传递给 emit() 来给事件处理程序传递参数:
eventEmitter.on('start', (number) => {
console.log(`started ${number}`)
})
eventEmitter.emit('start', 23)
多个参数:
eventEmitter.on('start', (start, end) => {
console.log(`started from ${start} to ${end}`)
})
eventEmitter.emit('start', 1, 100)
EventEmitter 对象还公开了其他几个与事件互动的方法,比如:
once(): 添加一个一次性的监听器removeListener()/off(): 从一个事件中删除一个事件监听器removeAllListeners(): 删除一个事件的所有监听器。
HTTP请求如何工作
当你在浏览器中输入一个 URL 时,从开始到结束会发生什么?
本节介绍浏览器如何使用 HTTP/1.1 协议执行页面请求。
如果你曾经做过一次面试,你可能会被问到。"当你在谷歌搜索框中输入东西并按下回车键时会发生什么?"。
这是你被问到的最多的问题之一。人们只是想看看你是否能解释一些相当基本的概念,以及你是否了解互联网的实际运作。
在本节中,我将分析当你在浏览器的地址栏中输入一个 URL 并按下回车键时会发生什么。
在本节中,我将分析当你在浏览器的地址栏中输入一个 URL 并按下回车键时会发生什么。
这是很少变化的技术,它为人类有史以来最复杂、最广泛的生态系统之一提供动力。
HTTP协议
我只分析 URL 请求。
现代浏览器有能力知道你在地址栏中写的东西是一个实际的URL还是一个搜索词,如果它不是一个有效的URL,它们将使用默认的搜索引擎。
我假设你输入了一个实际的 URL。
当你输入URL并按下回车键时,浏览器首先建立完整的URL。
与 MacOS/Linux 有关的事情
仅供参考。Windows可能会对一些事情的处理方式略有不同。
DNS 查询阶段
浏览器开始进行 DNS 查询以获得服务器的 IP 地址。
域名对我们人类来说是方便记忆,但互联网的组织方式是,计算机可以通过其 IP 地址查询服务器的确切位置,这是一组数字,如 222.324.3.1(IPv4)。
首先,它检查 DNS 的本地缓存,看这个域名最近是否已经被解析。
Chrome 有一个方便的DNS缓存可视化工具,你可以在这个网址上看到:chrome://net-internals/#dns(复制并粘贴到Chrome浏览器地址栏)
如果没有找到,浏览器就使用DNS解析器,使用 gethostbyname POSIX 系统调用来检索主机信息。
gethostbyname
gethostbyname:浏览器首先查找本地主机文件,在 macOS 或 Linux 上,该文件位于 /etc/hosts,以查看系统是否在本地提供了该信息。
如果这没有提供任何关于域名的信息,系统会向DNS服务器发出请求。
DNS服务器的地址存储在系统偏好中。
这些是2个流行的 DNS 服务器:
8.8.8.8: 谷歌公共 DNS 服务器1.1.1.1: CloudFlare DNS 服务器
大多数人使用他们的互联网供应商提供的 DNS 服务器。
浏览器使用 UDP 协议执行 DNS 请求。
TCP 和 UDP 是计算机网络的两个基础性协议。它们处于相同的概念层面,但 TCP 是面向连接的,而 UDP 是一个无连接的协议,更轻巧,用于发送消息,开销很小。
如何进行 UDP 请求不在本手册的范围内。
DNS 服务器的缓存中可能有该域名的 IP。如果没有,它将询问根域名服务器。那是一个驱动整个互联网的系统(由 13 个实际的服务器组成,分布在地球上)。
DNS 服务器并不知道地球上每一个域名的地址。
它所知道的是顶级 DNS 解析器的位置。
顶级域名是域名的扩展名:.com、.it、.pizza 等等。
一旦根 DNS 服务器收到请求,它就将请求转发到该顶级域名(TLD)DNS 服务器。
假设你正在寻找 flaviocopes.com。根域名的 DNS 服务器返回 .com TLD 服务器的 IP。
现在,我们的 DNS 解析器将缓存该 TLD 服务器的 IP,所以它不必再向根 DNS 服务器询问它。
TLD DNS 服务器将拥有我们正在寻找的域名的权威性域名服务器的 IP 地址。
怎么会这样?当你购买一个域名时,域名注册商会向域名服务器发送适当的 TDL。当你更新名称服务器时(例如,当你改变主机提供商时),这些信息将由你的域名注册商自动更新。
这些是主机提供商的 DNS 服务器。它们通常不止一个,以作为备份。
例如:
ns1.dreamhost.comns2.dreamhost.comns3.dreamhost.com
DNS 解析器从第一个开始,试图询问你要找的域名(也包括子域名)的 IP。
这就是IP地址的最终真实来源。
现在我们有了 IP 地址,我们可以继续我们的旅程了。
TCP 请求握手
有了服务器的 IP 地址,现在浏览器可以启动一个 TCP 连接。
TCP 连接在完全初始化之前需要进行一些握手,然后就可以开始发送数据。
一旦连接建立,我们可以发送请求
发送请求
请求是一个纯文本文件,以通信协议确定的精确方式结构化。
它由3个部分组成:
- 请求行
- 请求头
- 请求体
请求行
请求行设置了,在一个单行上:
- HTTP 方法
- 资源位置
- 协议版本
例如:
GET / HTTP/1.1
请求头
请求头是一组 "字段:值 "对,用于设置某些值。
有两个强制性的字段,一个是 host,另一个是 Connection,而所有其他字段是可选:
Host: flaviocopes.comConnection: close
Host 表示我们想要的目标域名,而 Connection 总是被设置为 close,除非连接必须保持开放。
一些最常用的请求头(header)字段是:
OriginAcceptAccept-EncodingCookieCache-ControlDnt
但还有更多。
请求头(head)部分由一个空行结束。
请求体
请求体是可选的,在 GET 请求中不使用,但在 POST 请求中非常使用,有时也用于其他动词,它可以包含 JSON 格式的数据。
由于我们现在分析的是一个 GET 请求,所以请求体是空白的,我们不做更多研究。
The response(响应)
一旦发送请求,服务器就会对其进行处理并发回一个响应。
响应以状态代码和状态信息开始。如果请求成功并返回 200:
200 OK
该请求可能会返回一个不同的状态代码和信息,比如这些信息之一:
404 Not Found
403 Forbidden
301 Moved Permanently
500 Internal Server Error
304 Not Modified
401 Unauthorized
然后,响应包含一个 HTTP 头的列表和响应体(因为我们是在浏览器中发出请求,所以它将是 HTML)。
解析(Parse)HTML
浏览器现在已经收到了 HTML,并开始解析它,它将重复我们对页面所需的所有资源所做的完全相同的过程:
- CSS 文件
- 图像
- 图标
- JavaScript 文件
- ……
浏览器是如何渲染页面的,这不在我们的讨论范围之内,但重要的是要明白,我所描述的过程不仅仅是针对 HTML 页面,而是针对任何通过 HTTP 提供的项目。
用 Node.js 建立一个 HTTP 服务器
这里是我们在介绍使用 Node.js HTTP 网络服务器实现 Hello World 应用程序:
const http = require('http')
const port = 3000
const server = http.createServer((req, res) => {
res.statusCode = 200
res.setHeader('Content-Type', 'text/plain')
res.end('Hello World\n')
})
server.listen(port, () => {
console.log(`Server running at http://${hostname}:${port}/`)
})s
让我们简单地分析一下。我们包括 http模块。
我们使用该模块来创建一个 HTTP 服务器。
该服务器被设置为监听指定的端口,3000。当服务器准备好时,listen 回调函数被调用。
我们传递的回调函数是在每个请求到来时都要执行的函数。每当收到一个新的请求,request event 被调用,提供两个对象:一个请求(一个 http.IncomingMessage 对象)和一个响应(一个 http.ServerResponse 对象)。
request 提供了请求的细节。通过它,我们可以访问请求头和请求数据。
response 用于填充我们要返回给客户端的数据。
response 用于填充我们要返回给客户端的数据:
res.statusCode = 200
我们将 statusCode 属性设置为 200,以表示响应成功。
我们还设置了 Content-Type 头:
res.setHeader('Content-Type', 'text/plain')
然后我们结束关闭响应,将内容作为参数添加到 end():
res.end('Hello World\n')
用 Node.js 做 HTTP 请求
如何用 Node.js 执行 HTTP 请求,使用 GET、POST、PUT 和 DELETE。
我使用 HTTP 一词,但 HTTPS 才是应该到处使用的(译者注:HTTPS 更安全),因此这些例子使用 HTTPS 而不是 HTTP。
Perform a GET Request
const https = require('https')
const options = {
hostname: 'flaviocopes.com',
port: 443, path: '/todos',
method: 'GET'
}
const req = https.request(options, (res) => {
console.log(`statusCode: ${res.statusCode}`)
res.on('data', (d) => { process.stdout.write(d) })
})
req.on('error', (error) => { console.error(error) })
req.end()
Perform a POST Request
const https = require('https')
const data = JSON.stringify({ todo: 'Buy the milk'})
const options = {
hostname: 'flaviocopes.com',
port: 443, path: '/todos',
method: 'POST',
headers: {'Content-Type':'application/json', 'Content-Length': data.length }
}
const req = https.request(options, (res) => {
console.log(`statusCode: ${res.statusCode}`)
})
res.on('data', (d) => {process.stdout.write(d)})
req.on('error', (error) => {console.error(error)})
req.write(data)
req.end()
PUT 和 DELETE
PUT 和 DELETE 请求使用相同的 POST 请求格式,只是改变 options.method 值。
在 Node.js 中使用 Axios 的 HTTP 请求
Axios 是一个非常流行的 JavaScript 库,你可以用来执行 HTTP 请求,它可以在浏览器和 Node.js 平台上工作。
它支持所有的现代浏览器,包括对 IE8 和更高版本的支持。
它是 promise-based, 这让我们可以非常容易编写异步/等待代码来执行 XHR 请求。
与原生的 Fetch API 相比,使用 Axios 有很多优势:
- 支持旧的浏览器(Fetch 需要一个 polyfill,即降级方案)
- 可以中止请求
- 可以设置响应超时
- 有内置的 CSRF 保护
- 支持上传进度
- 执行自动 JSON 数据转换
- 可以在 Node.js 中使用
安装
Axios 可以用 npm 安装:
npm install axios
或者 yarn:
yarn add axios
或简单地使用 unpkg.com,在你的页面引用:
<script src="https://unpkg.com/axios/dist/axios.min.js"></script>
Axios API
你可以从 axios 对象中开始一个 HTTP 请求:
axios({
url: 'https://dog.ceo/api/breeds/list/all',
method: 'get',
data: {foo:'bar'}
})
但为了方便起见,你一般会使用:
axios.get()axios.post()
(就像在 jQuery 中你会使用 $.get() 和 $.post() 而不是 $.ajax())
Axios 为所有的 HTTP 动词提供了方法,这些动词不太流行,但仍在使用:
axios.delete()axios.put()axios.patch()axios.options()
和一个方法来获取一个请求的 HTTP 头信息,并丢弃正文(discarding the body):
axios.head()
GET 请求
使用 Axios 的一个方便方法是使用现代(ES2017)的 async/await 语法。
这个 Node.js 例子查询了 Dog API,使用 axios.get() 检索了所有狗的品种列表,并对它们进行了统计:
const axios = require('axios')
const getBreeds = async () => {
try {
return await axios.get('https://dog.ceo/api/breeds/list/all')
}
catch (error) {
console.error(error)
}
}
const countBreeds = async () => {
const breeds = await getBreeds()
if (breeds.data.message) {
console.log(`Got ${Object.entries(breeds.data.message).length} breeds`)
}
}
countBreeds()
如果你不想使用 async/await,你可以使用 Promises 语法:
const axios = require('axios')
const getBreeds = () => {
try {
return axios.get('https://dog.ceo/api/breeds/list/all')
}
catch (error) {
console.error(error)
}
}
const countBreeds = async () => {
const breeds = getBreeds().then(response => {
if (response.data.message) {
console.log(`Got ${Object.entries(response.data.message).length} breeds`)
}
}).catch(error => {
console.log(error)})
}
countBreeds()
在GET请求中添加参数
一个 GET 响应可以在 URL 中包含参数,像这样 https://site.com/?foo=bar。
使用 Axios,你可以通过简单地使用该 URL 来执行:
axios.get('https://site.com/?foo=bar')
或者你可以在选项中使用一个 params 属性:
axios.get('https://site.com/', { params: { foo: 'bar' }})
POST 请求
执行 POST 请求就像执行 GET 请求一样,但你使用的不是 axios.get,而是 axios.post:
axios.post('https://site.com/')
一个包含 POST 参数的对象是第二个参数:
axios.post('https://site.com/', { foo: 'bar'})
在 Node.js 中使用 WebSockets
WebSockets 是网络应用中 HTTP 通信的替代方案。
它们在客户端和服务器之间提供了一个长期的、双向的通信通道。
一旦建立,通道就会保持开放,提供一个非常快速的连接,延迟和开销都很低。
浏览器对 WebSockets 的支持
所有现代浏览器都支持 WebSockets。
WebSockets与HTTP有什么不同
HTTP 是一个非常不同的协议,并且有不同的通信方式。
HTTP 是一个请求/响应协议:服务器在客户端请求时返回一些数据。
WebSockets:
- 服务器可以向客户端发送一个消息,而不需要客户端明确请求什么
- 客户端和服务器可以同时彼此对话
- 发送消息所需的数据开销非常小。这意味着低延迟的通信
WebSockets 非常适用于实时和长期的通信。
HTTP 非常适用于偶尔的数据交换和由客户端发起的互动。
HTTP 的实现要简单得多,而 WebSockets 则需要更多的开销。
安全的 WebSockets
始终使用安全的、加密的 WebSockets 协议,wss://。
ws:// 指的是不安全的 WebSockets 版本(WebSockets 的http://),由于明显的原因,应该避免使用。
创建一个新的 WebSockets 连接
const url = 'wss://myserver.com/something'
const connection = new WebSocket(url)
connection 是一个 WebSocket 对象。
当连接被成功建立时,"open" 事件被触发。
通过给 connection 对象的 onopen 属性分配一个回调函数来监听它:
connection.onopen = () => {} //...
如果有任何错误,onerror 函数回调被触发:
connection.onerror = error => {
console.log(`WebSocket error: ${error}`)
}
使用 WebSockets 向服务器发送数据
一旦连接被打开,你就可以向服务器发送数据。
你可以在 onopen 回调函数中方便地这样做:
connection.onopen = () => { connection.send('hey')}
使用 WebSockets 从服务器接收数据
在 onmessage 上使用回调函数进行监听,当收到 message 事件时被调用:
connection.onmessage = e => { console.log(e.data)}
在 Node.js 中实现一个 WebSockets 服务器
ws 是一个用于 Node.js 的流行的 WebSockets 库。
我们将用它来建立一个 WebSockets 服务器。它也可以用来实现一个客户端,并使用 WebSockets 在两个后端服务之间通信。
使用以下方法轻松地安装它:
yarn init
yarn add ws
你需要写的代码非常少:
const WebSocket = require('ws')
const wss = new WebSocket.Server({ port: 8080 })
wss.on('connection', ws => { ws.on('message', message => {
console.log(`Received message => ${message}`)
})
ws.send('ho!')})
这段代码在 8080 端口(WebSockets 的默认端口)创建了一个新的服务器,并在建立连接时添加了一个回调函数,向客户端发送 ho!,并记录它收到的消息。
请看 Glitch 上的一个运行中的例子
Here 是一个 WebSockets 服务器的活例子。
Here 是一个与服务器互动的 WebSockets 客户端。
在 Node.js 中使用文件描述符
在你能够与文件系统中的文件互动之前,你必须获得一个文件描述符。
文件描述符是使用 fs 模块提供的 open() 方法打开文件时返回的东西:
const fs = require('fs')
fs.open('/Users/flavio/test.txt', 'r', (err, fd) => { })//fd is our file descriptor
注意我们用 r 作为 fs.open() 调用的第二个参数。
这个标志意味着我们打开文件进行阅读。
你经常使用的其他标志是
r+打开文件进行读写w+打开文件进行读写,将流定位在文件的开头。如果文件不存在,将被创建。a打开文件进行写入,将数据流定位在文件的末端。如果不存在,文件将被创建。a+`打开文件进行读写,将数据流定位在文件的末端。如果不存在,文件被创建。
你也可以通过使用 fs.openSync 方法来打开文件,它不是在回调中提供文件描述符对象,而是返回它:
const fs = require('fs')
try {
const fd = fs.openSync('/Users/flavio/test.txt', 'r')
} catch (err) {
console.error(err)
}
一旦你得到了文件描述符,无论你选择什么方式,你都可以执行所有需要它的操作,比如调用 fs.open() 和许多其他与文件系统互动的操作。
Node.js 文件统计(stats)
每个文件都带有一组细节,我们可以使用 Node.js 检查。
特别是,使用 fs 模块提供的 stat() 方法。
你通过一个文件路径来调用它,一旦 Node.js 得到了文件的细节,它将调用你传递的带有 2 个参数的回调函数:一个错误信息和文件统计:
const fs = require('fs')fs.stat('/Users/flavio/test.txt', (err, stats) => {
if (err) {
console.error(err)
return
}
}) //we have access to the file stats in `stats`
Node.js 还提供了一个同步方法,它可以阻塞线程,直到文件统计准备就绪:
const fs = require('fs')
try {
const stats = fs.stat('/Users/flavio/test.txt')
}
catch (err) {
console.error(err)
}
文件信息被包含在 stats 变量中。我们可以用 stats 提取什么样的信息?
很多,包括:
- 如果文件是一个目录或一个文件,使用
stats.isFile()和stats.isDirectory() - 如果文件是一个符号链接,使用
stats.isSymbolicLink() - 使用
stats.size来计算文件的字节数
还有其他高级方法,但你在日常编程中会用到的大部分方法是这样的:
const fs = require('fs')fs.stat('/Users/flavio/test.txt', (err, stats) => {
if (err) {
console.error(err)
return
}
stats.isFile() //true
stats.isDirectory() //false
stats.isSymbolicLink() //false
stats.size //1024000 //= 1MB})
}
Node.js 文件路径
系统中的每个文件都有一个路径。
在 Linux 和 MacOS 上,一个路径可能看起来像:
/users/flavio/file.txt
而 Windows 电脑则不同,它的结构如:
C:\users\flavio\file.txt
在你的应用程序中使用路径时,你需要注意,因为必须考虑到这种差异。
你在你的文件中包括这个模块,使用:
const path = require('path')
你可以开始使用它的方法。
从路径中获取信息
给定一个路径,你可以用这些方法提取其中的信息:
dirname: 获取文件的父文件夹basename: 获取文件名部分extname: 获得文件的扩展名
例如:
const notes = '/users/flavio/notes.txt'
path.dirname(notes) // /users/flavio
path.basename(notes) // notes.txt
path.extname(notes) // .txt
你可以通过给 basename 指定第二个参数来获得不带扩展名的文件名:
path.basename(notes, path.extname(notes)) //notes
使用路径工作
你可以通过使用 path.join() 来连接一个路径的两个或多个部分:
const name = 'flavio'path.join('/', 'users', name, 'notes.txt') //'/users/flavio/notes.txt'
你可以使用 path.resolve() 从相对路径获得绝对路径计算:
path.resolve('flavio.txt') //'/Users/flavio/flavio.txt' if run from my home folder
在这种情况下,Node.js 将简单地把 /flavio.txt 追加到当前工作目录。如果你指定了第二个参数文件夹,resolve 将使用第一个作为第二个的基础:
path.resolve('tmp', 'flavio.txt')// '/Users/flavio/tmp/flavio.txt' if run from my home folder
如果第一个参数以斜线开头,这意味着它是一个绝对路径:
path.resolve('/etc', 'flavio.txt')// '/etc/flavio.txt'
path.normalize() 是另一个有用的函数,它将尝试计算实际的路径,当它包含像.或.这样的相对指定符,或双斜线时:
path.normalize('/users/flavio/..//test.txt') // /users/test.txt
但是 resolve 和 normalize 不会 检查路径是否存在。它们只是根据得到的信息计算出一个路径。
用 Node.js 读取文件
在 Node.js 中读取文件的最简单方法是使用 fs.readFile() 方法,将文件路径和一个回调函数传递给它,该函数将被调用,并带有文件数据(和错误):
const fs = require('fs')
fs.readFile('/Users/flavio/test.txt', (err, data) => {
if (err) {
console.error(err)
return
}
console.log(data)
})
或者,你可以使用同步版本 fs.readFileSync():
const fs = require('fs')
try {
const data = fs.readFileSync('/Users/flavio/test.txt')
console.log(data)
} catch (err) {
console.error(err)
}
默认编码是 "utf8",但你可以使用第二个参数指定一个自定义编码。
fs.readFile() 和 fs.readFileSync() 都是在返回数据之前读取内存中的全部文件内容。
这意味着大文件会对你的内存消耗和程序的执行速度产生重大影响。
在这种情况下,一个更好的选择是使用流(streams)读取文件内容。
用 Node.js 写文件
在 Node.js 中写入文件的最简单方法是使用 fs.writeFile() API。
例如:
const fs = require('fs')
const content = 'Some content!'
fs.writeFile('/Users/flavio/test.txt', content, (err) => {
if (err) {
console.error(err)
return
}
})//file written successfully
或者,你可以使用同步版本 fs.writeFileSync():
const fs = require('fs')
const content = 'Some content!'
try {
const data = fs.writeFileSync('/Users/flavio/test.txt', content)
//file written successfully
}
catch (err) {
console.error(err)
}
默认情况下,如果文件已经存在,该 API 将 替换 该文件的内容。
你可以通过指定一个标志(flag)来修改默认值:
fs.writeFile('/Users/flavio/test.txt', content, { flag: 'a+' }, (err) => {})
你可能会用到的标志(flags):
r+打开文件进行读写。w+打开文件进行读写,将流定位在文件的开头。如果文件不存在,将被创建。a打开文件进行写入,将数据流定位在文件的末端。如果不存在,文件将被创建。a+打开文件进行读写,将数据流定位在文件的末端。如果不存在,该文件将被创建
你可以找到更多关于 flags 的信息
追加到一个文件中
一个方便的方法是 fs.appendFile() (和它的 fs.appendFileSync() 对应同步的方法),将内容附加到文件的末尾:
const content = 'Some content!'
fs.appendFile('file.log', content, (err) => {
if (err) {
console.error(err)
return
}
})//done!
使用流(streams)
所有这些方法在把控制权返回给你的程序之前都会把全部内容写入文件(在异步版本中,这意味着执行回调)。
在这种情况下,一个更好的选择是使用流(streams)来写文件内容。
在 Node.js 中使用文件夹
Node.js fs 核心模块提供了许多方便的方法,你可以用来处理文件夹。
检查一个文件夹是否存在
使用 fs.access() 来检查文件夹是否存在,并且 Node.js 可以用其权限来访问它。
创建文件夹
使用 fs.mkdir() 或 fs.mkdirSync() 来创建一个新文件夹:
const fs = require('fs')
const folderName = '/Users/flavio/test'
try {
if (!fs.existsSync(dir))
{fs.mkdirSync(dir)}
} catch (err){
console.error(err)
}
读取一个目录的内容
使用 fs.readdir() 或 fs.readdirSync 来读取一个目录的内容。
这段代码读取一个文件夹的内容,包括文件和子文件夹,并返回其相对路径:
const fs = require('fs')
const path = require('path')
const folderPath = '/Users/flavio'
fs.readdirSync(folderPath)
你可以得到完整的路径:
fs.readdirSync(folderPath)
.map(fileName => {
return path.join(folderPath, fileName)
})
你还可以过滤结果,只返回文件,并排除文件夹:
const isFile = fileName => {
return fs.lstatSync(fileName).isFile()
}
fs.readdirSync(folderPath).map(fileName => {
return path.join(folderPath, fileName).filter(isFile)
})
重命名文件夹
使用 fs.rename() 或 fs.renameSync() 来重命名文件夹。
第一个参数是当前路径,第二个参数是新路径:
const fs = require('fs')
fs.rename('/Users/flavio', '/Users/roger', (err) => {
if (err) {
console.error(err)
return
}
})//done
fs.renameSync() 是同步版本:
const fs = require('fs')
try { fs.renameSync('/Users/flavio', '/Users/roger')
} catch (err) {
console.error(err)
}
删除文件夹
使用 fs.rmdir() 或 fs.rmdirSync() 来删除一个文件夹。
删除一个有内容的文件夹可能比你需要的更复杂。
在这种情况下,我建议安装 fs-extra 模块,它非常受欢迎,维护得很好,它可以直接替换 fs 模块,在其基础上提供更多的功能。
在这种情况下,remove() 方法是你想要的。
用以下方法安装它:
npm install fs-extra
像这样使用它:
const fs = require('fs-extra')
const folder = '/Users/flavio'
fs.remove(folder, err => {console.error(err)})
它也可以与 Promises 一起使用:
fs.remove(folder).then(() => {done}).catch(err => {
console.error(err)
}) //done
或者使用 async/await:
async function removeFolder(folder) {
try {
await fs.remove(folder)
}//done
catch (err) {console.error(err) }
}
const folder = '/Users/flavio'
removeFolder(folder)
Node.js fs 模块
fs 模块提供了很多非常有用的功能来访问文件系统并与之互动。
不需要安装它。作为 Node.js 核心的一部分,它可以通过简单地要求它来使用:
const fs = require('fs')
一旦你这样做,你就可以使用它的所有方法,其中包括:
fs.access(): 检查文件是否存在,并且Node可以用其权限访问它。fs.appendFile(): 将数据追加到文件中。如果文件不存在,就创建它fs.chmod(): 改变一个由文件名指定的文件的权限。相关的:fs.lchmod(),fs.fchmod()fs.chown(): 改变由文件名指定的文件的所有者和组。相关的:fs.fchown(),fs.lchown()fs.close(): 关闭一个文件描述符fs.copyFile(): 复制一个文件fs.createReadStream(): 创建一个可读文件流fs.createWriteStream(): 创建一个可写的文件流fs.link(): 为文件创建一个新的硬链接fs.mkdir(): 创建一个新的文件夹fs.mkdtemp(): 创建一个临时目录fs.open(): 设置文件模式fs.readdir(): 读取一个目录的内容fs.readFile(): 读取一个文件的内容. 相关的:fs.read()fs.readlink(): 读取一个符号链接的值fs.realpath(): 将相对文件路径指针 (.,..) 解析为全路径fs.rename(): 重命名一个文件或文件夹fs.rmdir(): 删除一个文件夹fs.stat(): 返回由文件名识别的文件的状态。相关的:fs.fstat(),fs.lstat()fs.symlink(): 创建一个新的符号链接到一个文件fs.truncate(): 将文件名标识的文件截断到指定长度。相关的:fs.ftruncate()fs.unlink(): 删除一个文件或一个符号链接fs.unwatchFile(): 停止监视一个文件的变化fs.utimes(): 改变由文件名标识的文件的时间戳。 相关的:fs.futimes()fs.watchFile(): 开始监视一个文件的变化。相关的:fs.watch()fs.writeFile(): 向文件写入数据。 相关的:fs.write()
关于 fs 模块的一个特别之处是,所有的方法默认都是异步的,但它们也可以通过附加 Sync 而同步工作。
例子:
fs.rename()fs.renameSync()fs.write()fs.writeSync()
这对你的应用流程有很大的影响。
Node 10 包括对基于 Promise 的API的 实验性支持。
例如,让我们检查 fs.rename() 方法。异步 API 是用一个回调来实现的:
const fs = require('fs')
fs.rename('before.json', 'after.json', (err) => {
if (err) {
return console.error(err)
}
})//done
一个同步的 API 可以这样使用,用一个 try/catch 块来处理错误:
const fs = require('fs')
try {
fs.renameSync('before.json', 'after.json')//done
} catch(err) {
console.error(err)
}
这里的关键区别是,在第二个例子中,你的脚本的执行将被阻塞,直到文件操作成功。
Node.js 的路径模块
path 模块提供了很多非常有用的功能,可以访问文件系统并与之互动。
没有必要安装它。作为 Node.js 核心的一部分,它可以通过简单地要求它来使用:
const path = require('path')
这个模块提供了 path.sep,它提供了路径段的分隔符(在 Windows下为 /,在 Linux/MacOS下为 /),以及 path.delimiter,它提供了路径分隔符(在 Windows 下为;,在 Linux/MacOS下为:)。
这些是 路径 方法。
path.basename()
返回一个路径的最后部分。第二个参数可以过滤掉文件扩展名:
require('path').basename('/test/something') //something
require('path').basename('/test/something.txt') //something.txt
require('path').basename('/test/something.txt', '.txt') //something
path.dirname()
返回一个路径的目录部分:
require('path').dirname('/test/something') // /test
require('path').dirname('/test/something/file.txt') // /test/something
path.extname()
返回一个路径的扩展部分:
require('path').dirname('/test/something') // ''
require('path').dirname('/test/something/file.txt') // '.txt'
path.isAbsolute()
如果它是一个绝对路径,则返回 true:
require('path').isAbsolute('/test/something') // true
require('path').isAbsolute('./test/something') // false
path.join()
连接一个路径的两个或多个部分:
const name = 'flavio'
require('path').join('/', 'users', name, 'notes.txt') //'/users/flavio/notes.txt'
path.normalize()
试图计算实际路径,当它包含相对指定符如 . 或 ..,或双斜线(//):
require('path').normalize('/users/flavio/..//test.txt') ///users/test.txt
path.parse()
解析一个对象的路径和组成它的片段:
root: 根目录dir: 从根开始的文件夹路径base: 文件名+扩展名name: 文件名ext: 扩展名
例如:
require('path').parse('/users/test.txt')
结果:
{ root: '/', dir: '/users', base: 'test.txt', ext: '.txt', name: 'test'}
path.relative()
接受两个路径作为参数。基于当前工作目录,返回从第一个路径到第二个路径的相对路径。
例如:
require('path').relative('/Users/flavio', '/Users/flavio/test.txt') //'test.txt'
require('path').relative('/Users/flavio', '/Users/flavio/something/test.txt') //'something/test.txt'
path.resolve()
你可以使用 path.resolve() 获得从相对路径得到绝对路径:
path.resolve('flavio.txt') //'/Users/flavio/flavio.txt' if run from my home folder
通过指定第二个参数,resolve 将使用第一个参数作为第二个参数的基础:
path.resolve('tmp', 'flavio.txt')//'/Users/flavio/tmp/flavio.txt' if run from my home folder
如果第一个参数以斜线开头,这意味着它是一个绝对路径:
path.resolve('/etc', 'flavio.txt')//'/etc/flavio.txt'
Node.js 的 os 模块
这个模块提供了许多功能,你可以用来从底层的操作系统和程序运行的计算机上检索信息,并与之进行交互。
const os = require('os')
有几个有用的属性告诉我们一些与处理文件有关的关键事情:
os.EOL 给出了行的定界符序列。在 Linux和MacOS 上是 \n,而在 Windows 上是 \r\n。
当我说 Linux 和 MacOS 时,我指的是 POSIX 平台。为了简单起见,我排除了其他不太流行的操作系统,Node 可以在上面运行。
os.constants.signals 告诉我们所有与处理进程信号有关的常量,如 SIGHUP, SIGKILL 等。
os.constants.errno 设置错误报告的常量,如 EADDRINUSE、EOVERFLOW 等。
你可以全部阅读 这里。
现在让我们看看 os 提供的主要方法:
os.arch()os.cpus()os.endianness()os.freemem()os.homedir()os.hostname()os.loadavg()os.networkInterfaces()os.platform()os.release()os.tmpdir()os.totalmem()os.type()os.uptime()os.userInfo()
os.arch()
返回标识底层架构的字符串,如 arm, x64, arm64.
os.cpus()
返回你系统上可用的 CPU 的信息。
例如:
[{
model: 'Intel(R) Core(TM)2 Duo CPU P8600 @ 2.40GHz',
speed: 2400,
times: {
user: 281685380,
nice: 0,
sys: 187986530,
idle: 685833750,
irq: 0
}
}, {
model: 'Intel(R) Core(TM)2 Duo CPU P8600 @ 2.40GHz',
speed: 2400,
times: {
user: 282348700,
nice: 0,
sys: 161800480,
idle: 703509470,
irq: 0
}
}]
os.endianness()
返回 BE 或 LE,取决于 Node.js 是用 Big Endian or Little Endian 编译的。
os.freemem()
返回代表系统中空闲内存的字节数。
os.homedir()
返回到当前用户的主目录的路径。
例如:
'/Users/flavio'
os.hostname()
返回主机名。
os.loadavg()
返回操作系统对负载平均值的计算结果。
它只在 Linux 和 MacOS 上返回一个有意义的值。
例如:
[ 3.68798828125, 4.00244140625, 11.1181640625 ]
os.networkInterfaces()
返回你系统中可用的网络接口的详细信息。
例如:
{
lo0: [{
address: '127.0.0.1',
netmask: '255.0.0.0',
family: 'IPv4',
mac: 'fe:82:00:00:00:00',
internal: true
}, {
address: '::1',
netmask: 'ffff:ffff:ffff:ffff:ffff:ffff:ffff:ffff',
family: 'IPv6',
mac: 'fe:82:00:00:00:00',
scopeid: 0,
internal: true
}, {
address: 'fe80::1',
netmask: 'ffff:ffff:ffff:ffff::',
family: 'IPv6',
mac: 'fe:82:00:00:00:00',
scopeid: 1,
internal: true
}],
en1: [{
address: 'fe82::9b:8282:d7e6:496e',
netmask: 'ffff:ffff:ffff:ffff::',
family: 'IPv6',
mac: '06:00:00:02:0e:00',
scopeid: 5,
internal: false
}, {
address: '192.168.1.38',
netmask: '255.255.255.0',
family: 'IPv4',
mac: '06:00:00:02:0e:00',
internal: false
}],
utun0: [{
address: 'fe80::2513:72bc:f405:61d0',
netmask: 'ffff:ffff:ffff:ffff::',
family: 'IPv6',
mac: 'fe:80:00:20:00:00',
scopeid: 8,
internal: false
}]
}
os.platform()
返回 Node.js 编译时使用的平台:
darwinfreebsdlinuxopenbsdwin32- ……more
os.release()
返回一个字符串,用于识别操作系统的发行号。
os.tmpdir()
返回指定的临时文件夹的路径。
os.totalmem()
返回代表系统中可用的总内存的字节数。
os.type()
识别操作系统:
LinuxDarwinon MacOSWindows_NTon Windows
os.uptime()
返回计算机自上次重启以来的运行秒数。
Node.js 的事件模块
events 模块为我们提供了 EventEmitter 类,它是在 Node.js 中处理事件的关键。
我在这方面发表了一篇完整的 文章,所以在这里我将只描述 API,而不进一步举例说明如何使用它。
const EventEmitter = require('events')
const door = new EventEmitter()
事件监听器吃自己的狗粮(译者注: dog food 是指自己写的代码),使用这些事件:
newListener当一个监听器被添加removeListener当一个监听器被移除
当一个监听器被移除:
emitter.addListener()emitter.emit()emitter.eventNames()emitter.getMaxListeners()emitter.listenerCount()emitter.listeners()emitter.off()emitter.on()emitter.once()emitter.prependListener()emitter.prependOnceListener()emitter.removeAllListeners()emitter.removeListener()emitter.setMaxListeners()
emitter.addListener()
别名 emitter.on().
emitter.emit()
发出一个事件。它按注册的顺序同步调用每个事件监听器。
emitter.eventNames()
返回一个字符串数组,代表在当前 EventListener 上注册的事件:
door.eventNames()
emitter.getMaxListeners()
获取可以添加到 EventListener 对象中的最大监听器数量,默认为 10,但可以通过使用 setMaxListeners() 增加或减少:
door.getMaxListeners()
emitter.listenerCount()
获取作为参数传递的事件的监听数量:
door.listenerCount('open')
emitter.listeners()
获取作为参数传递的事件的监听者数组:
door.listeners('open')
emitter.off()
别名 emitter.removeListener(),在 Node 10 加入的。
emitter.on()
添加一个回调函数,当一个事件被发出时被调用。
使用案例:
door.on('open', () => {console.log('Door was opened')})
emitter.once()
添加一个回调函数,在注册后第一次发出事件时被调用。这个回调函数只被调用一次,不会再被调用。
const EventEmitter = require('events')
const ee = new EventEmitter()
ee.once('my-event', () => {
//call callback function once
})
emitter.prependListener()
当你使用 on 或 addListener 添加监听器时,它在监听器队列中被最后添加,并被最后调用。使用 prependListener,它将在其他监听器之前被添加和调用。
emitter.prependOnceListener()
当你使用 once 添加一个监听器时,它在监听器队列中最后被添加,并最后被调用。使用 prependOnceListener,它将在其他监听器之前被添加和调用。
emitter.removeAllListeners()
移除监听某一特定事件的事件发射器对象的所有监听者:
door.removeAllListeners('open')
emitter.removeListener()
删除一个特定的监听器。你可以这样做,在添加回调函数时,将其保存到一个变量中,这样你以后就可以引用它了:
const doSomething = () => {
door.on('open', doSomething)
door.removeListener('open', doSomething)
}
emitter.setMaxListeners()
设置一个人可以添加到 EventListener 对象中的最大监听器数量,默认为 10,但可以增加或减少:
door.setMaxListeners(50)
Node.js http 模块
Node.js 的 http 模块提供了有用的函数和类来建立一个 HTTP 服务器。它是 Node.js 网络的一个关键模块。
它可以用以下方式引入:
const http = require('http')
该模块提供了一些属性和方法,以及一些类。
Properties
http.METHODS
此属性列出了所有支持的 HTTP 方法:
> require('http').METHODS
[ 'ACL', 'BIND', 'CHECKOUT', 'CONNECT', 'COPY', 'DELETE', 'GET', 'HEAD', 'LINK', 'LOCK', 'M-SEARCH', 'MERGE', 'MKACTIVITY', 'MKCALENDAR', 'MKCOL', 'MOVE', 'NOTIFY', 'OPTIONS', 'PATCH', 'POST', 'PROPFIND', 'PROPPATCH', 'PURGE', 'PUT', 'REBIND', 'REPORT', 'SEARCH', 'SUBSCRIBE', 'TRACE', 'UNBIND', 'UNLINK', 'UNLOCK', 'UNSUBSCRIBE' ]
http.STATUS_CODES
此属性列出了所有的HTTP状态代码及其描述:
> require('http').STATUS_CODES
{ '100': 'Continue', '101': 'Switching Protocols', '102': 'Processing', '200': 'OK', '201': 'Created', '202': 'Accepted', '203': 'Non-Authoritative Information', '204': 'No Content', '205': 'Reset Content', '206': 'Partial Content', '207': 'Multi-Status', '208': 'Already Reported', '226': 'IM Used', '300': 'Multiple Choices', '301': 'Moved Permanently', '302': 'Found', '303': 'See Other', '304': 'Not Modified', '305': 'Use Proxy', '307': 'Temporary Redirect', '308': 'Permanent Redirect', '400': 'Bad Request', '401': 'Unauthorized', '402': 'Payment Required', '403': 'Forbidden', '404': 'Not Found', '405': 'Method Not Allowed', '406': 'Not Acceptable', '407': 'Proxy Authentication Required', '408': 'Request Timeout', '409': 'Conflict', '410': 'Gone', '411': 'Length Required', '412': 'Precondition Failed', '413': 'Payload Too Large', '414': 'URI Too Long', '415': 'Unsupported Media Type', '416': 'Range Not Satisfiable', '417': 'Expectation Failed', '418': 'I\'m a teapot', '421': 'Misdirected Request', '422': 'Unprocessable Entity', '423': 'Locked', '424': 'Failed Dependency', '425': 'Unordered Collection', '426': 'Upgrade Required', '428': 'Precondition Required', '429': 'Too Many Requests', '431': 'Request Header Fields Too Large', '451': 'Unavailable For Legal Reasons', '500': 'Internal Server Error', '501': 'Not Implemented', '502': 'Bad Gateway', '503': 'Service Unavailable', '504': 'Gateway Timeout', '505': 'HTTP Version Not Supported', '506': 'Variant Also Negotiates', '507': 'Insufficient Storage', '508': 'Loop Detected', '509': 'Bandwidth Limit Exceeded', '510': 'Not Extended', '511': 'Network Authentication Required' }
http.globalAgent
指向 Agent 对象的全局实例,它是 http.Agent 类的一个实例。
它用于管理 HTTP 客户端的连接持久性和重用,是 Node.js HTTP 网络的一个关键组件。
在后面的 http.Agent 类描述中会有更多内容。
Methods
http.createServer()
返回一个 http.Server 类的新实例。
用法:
const server = http.createServer((req, res) => {})//handle every single request with this callback
http.request()
http.get()
向服务器发出一个 HTTP 请求,创建一个 http.ClientRequest 类的实例。
Classes
HTTP模块提供了5个类(classes):
http.Agenthttp.ClientRequesthttp.Serverhttp.ServerResponsehttp.IncomingMessage
http.Agent
Node创建了一个 http.Agent 类的全局实例来管理HTTP客户端的连接持久性和重复使用,这是 Node HTTP 网络的一个关键组成部分。
这个对象确保每一个向服务器发出的请求都是排队的,并且一个套接字被重复使用。
它还维护一个套接字池。这是性能方面的关键。
http.ClientRequest
当 http.request() 或 http.get() 被调用时,一个 http.ClientRequest 对象被创建。
当收到一个响应时,response 事件会被调用,并以一个 http.IncomingMessage 实例作为参数。
响应的返回数据可以通过两种方式读取:
- 你可以调用
response.read()方法 - 在
response事件处理程序中,你可以为data事件设置一个事件监听器,所以你可以监听流进的数据。
http.Server
这个类通常在使用 http.createServer() 创建一个新的服务器时被实例化并返回。
一旦你有了一个服务器对象,你就可以访问它的方法:
close()停止服务器接受新的连接listen()启动HTTP服务器并监听连接
http.ServerResponse
由http.Server创建,并作为第二个参数传递给它所触发的 request 事件。
通常在代码中被称为 res:
const server = http.createServer((req, res) => { })//res is an http.ServerResponse object
你总是在处理程序中调用的方法是 end(),它关闭了响应,消息已经完成,服务器可以把它发送给客户端。它必须在每个响应中被调用。
这些方法是用来与 HTTP 头信息交互的:
getHeaderNames()获得已经设置的 HTTP 头的名称列表getHeaders()获得一份已经设置的 HTTP 头的副本setHeader('headername', value)设置一个 HTTP 头的值getHeader('headername')获取一个已经设置的 HTTP 头信息removeHeader('headername')删除一个已经设置的 HTTP 头hasHeader('headername')如果响应中设置了该头信息,则返回 trueheadersSent()如果头信息已经被发送到客户端,则返回 true
在处理完头信息后,你可以通过调用 response.writeHead() 将它们发送给客户端,它接受 statusCode 作为第一个参数、可选的状态信息和头信息对象。
要在响应体中向客户端发送数据,你可以使用 write()。它将发送缓冲的数据到 HTTP 响应流中。
如果使用 response.writeHead() 还没有发送头信息,它将首先发送头信息,并在请求中设置状态码和信息,你可以通过设置 statusCode 和 statusMessage 属性值来编辑:
response.statusCode = 500
response.statusMessage = 'Internal Server Error'
http.IncomingMessage
一个 "http.IncomingMessage" 对象是通过以下方式创建的:
http.Server监听request事件http.ClientRequest监听 "response" 事件
它可以用来访问响应(response):
- status,使用
statusCode和statusMessage方法 - headers,使用
headers方法或rawHeaders - HTTP method 使用它的
methodmethod - HTTP version 使用
httpVersionmethod - URL 使用
urlmethod - 使用 "socket "方法的底层套接字
由于http.IncomingMessage 实现了可读流接口,所以数据可以使用流访问。
Node.js流(Streams)
流是支持 Node.js 应用程序的基本概念之一。
它们是一种有效处理读/写文件、网络通信或任何种类的端到端信息交换的方式。
流不是 Node.js 特有的概念。几十年前,它们就被引入到 Unix 操作系统中,程序之间可以通过管道操作符(|)传递流进行交互。
例如,在传统的方式中,当你告诉程序读取一个文件时,文件被读入内存,从头到尾,然后你处理它。
使用流,你会一块一块地读取它,处理它的内容,而不把它全部保留在内存中。
Node.js的 stream模块 提供了所有流媒体API的基础。
为什么是流?
流基本上提供了使用其他数据处理方法的两个主要优势:
- 内存效率: 你不需要在处理数据之前在内存中加载大量的数据
- 时间效率: 一旦你有了数据,就开始处理,而不是等到整个数据负载可用时才开始,这需要的时间要少得多。
一个流的例子
一个典型的例子是从磁盘上读取文件的例子。
使用Node.js fs 模块,你可以读取一个文件,并在与你的 http 服务器建立新的连接时通过 HTTP 提供服务:
const http = require('http')
const fs = require('fs')
const server = http.createServer(function (req, res) {
fs.readFile(__dirname + '/data.txt', (err, data) => {
res.end(data) })
})
server.listen(3000)
readFile() 读取文件的全部内容,并在完成后调用回调函数。
回调函数中的 res.end(data) 将返回文件内容给 HTTP 客户端。
如果文件很大,这个操作将花费相当多的时间。下面是用流写的同样的东西:
const http = require('http')
const fs = require('fs')
const server = http.createServer((req, res) => {
const stream = fs.createReadStream(__dirname + '/data.txt')
stream.pipe(res)
})
server.listen(3000)
我们不是等到文件被完全读完,而是一旦有了准备好的数据块,就开始把它流向 HTTP 客户端。
pipe()
上面的例子使用了 stream.pipe(res) 一行:在文件流中调用了 pipe() 方法。
这段代码做了什么?它接收源文件,并将其输送到一个目的地。
你在源流上调用它,所以在本例中,文件流被管道到 HTTP 响应。
pipe() 方法的返回值是目标流,这是一个非常方便的东西,让我们可以连锁调用多个 pipe(),像这样:
src.pipe(dest1).pipe(dest2)
这个结构做相同的事:
src.pipe(dest1)
dest1.pipe(dest2)
Node.js 的流(stream) API
由于它们的优势,许多 Node.js 核心模块提供了原生的流处理能力,最显著的是:
process.stdin返回一个连接到 stdin 的流process.stdout返回连接到 stdout 的流process.stderr返回一个与 stderr 相连的流fs.createReadStream()创建一个到文件的可读流fs.createWriteStream()创建一个到文件的可写流net.connect()发起一个基于流的连接http.request()返回 http.ClientRequest 类的一个实例,这是一个可写流zlib.createGzip()使用 gzip(一种压缩算法)将数据压缩到一个流中zlib.createGunzip()解压一个 gzip 流zlib.createDeflate()使用 deflate(一种压缩算法)将数据压缩到一个流中zlib.createInflate()解压一个 deflate 流
不同类型的流
有四种类型的流:
Readable: 你可以用管道输送,但不能用管道进入(你可以接收数据,但不能向它发送数据)。当你向一个可读流推送数据时,它被缓冲,直到消费者开始读取数据。Writable: 你可以用管道进入,但不能用管道离开(你可以发送数据,但不能从它接收)Duplex: 一个既可以管入又可以管出的流,基本上是一个可读流和可写流的组合。Transform: 类似于Duplex,但输出是其输入的变换
如何创建一个可读流
我们从 stream 模块获得 可读(Readable) 流,并初始化它:
const Stream = require('stream')
const readableStream = new Stream.Readable()
现在,流已经被初始化,我们可以向它发送数据了:
readableStream.push('hi!')
readableStream.push('ho!')
如何创建一个可写流
为了创建一个可写流,我们扩展了基础的 Writable 对象,并实现了它的 _write() 方法。
首先创建一个流对象:
const Stream = require('stream')
const writableStream = new Stream.Writable()
然后执行 _write:
writableStream._write = (chunk, encoding, next) => {
console.log(chunk.toString())
next()
}
你现在可以用管道输送一个可读流:
process.stdin.pipe(writableStream)
如何从一个可读流中获取数据
我们如何从一个可读流中读取数据?使用一个可写流:
const Stream = require('stream')
const readableStream = new Stream.Readable()
const writableStream = new Stream.Writable()
writableStream._write = (chunk, encoding, next) => {
console.log(chunk.toString())
next()
}
readableStream.pipe(writableStream)
readableStream.push('hi!')
readableStream.push('ho!')
你也可以直接消费一个可读流,使用 readable 事件:
readableStream.on('readable', () => {
console.log(readableStream.read())
})
如何向可写流发送数据
使用流 write() 方法:
writableStream.write('hey!\n')
向一个可写的流发出信号,当你想停止写入
使用 end() 方法:
const Stream = require('stream')
const readableStream = new Stream.Readable()
const writableStream = new Stream.Writable()
writableStream._write = (chunk, encoding, next) => {
console.log(chunk.toString())
next()
}
readableStream.pipe(writableStream)
readableStream.push('hi!')
readableStream.push('ho!')
writableStream.end()
使用 MySQL 和 Node.js 的基础知识
MySQL 是世界上最流行的关系型数据库之一。
Node.js 生态系统有几个不同的包,允许你与 MySQL 接口,存储数据,检索数据,等等。
我们将使用 mysqljs/mysql,这个包在 GitHub 上有超过 12,000 颗星,已经存在多年。
安装Node.js MySql包
安装命令:
npm install mysql
初始化与数据库的连接
你首先要引入包:
const mysql = require('mysql')
并创建一个连接:
const options = {
user: 'the_mysql_user_name',
password: 'the_mysql_user_password',
database: 'the_mysql_database_name'
}
const connection = mysql.createConnection(options)
你通过调用以下命令启动一个新的连接:
connection.connect(err => {
if (err) {
console.error('An error occurred while connecting to the DB')
throw err
}
})
连接选项
在上面的例子中,options 对象包含 3 个选项:
const options = {
user: 'the_mysql_user_name',
password: 'the_mysql_user_password',
database: 'the_mysql_database_name'
}
你还可以使用很多,包括:
host, 数据库主机名,默认为localhostport, MySQL服务器端口号,默认为 3306socketPath, 用于指定 Unix 套接字,而不是主机和端口debug, 默认为禁用,可用于调试trace, 默认为启用,当发生错误时打印堆栈跟踪ssl, 用于设置与服务器的SSL连接(不在本教程范围内)
执行一个 SELECT 查询
现在你已经准备好在数据库上执行一个 SQL 查询。查询一旦执行,将调用一个回调函数,其中包含一个最终的错误、结果和字段(fields):
connection.query('SELECT * FROM todos', (error, todos, fields) => {
if (error) {
console.error('An error occurred while executing the query')
throw error
}
console.log(todos)
})
你可以传入将被自动转义的值:
const id = 223
connection.query('SELECT * FROM todos WHERE id = ?', [id], (error, todos, fields) => {
if (error) {
console.error('An error occurred while executing the query')
throw error
}
console.log(todos)
})
要传递多个值,只需在你作为第二个参数传递的数组中放入更多元素即可:
const id = 223const author = 'Flavio'
connection.query('SELECT * FROM todos WHERE id = ? AND author = ?', [id, author], (error, todos, fields) => {
if (error) {
console.error('An error occurred while executing the query')
throw error
}
console.log(todos)
})
执行一个INSERT 语句
你可以传递一个对象:
const todo = { thing: 'Buy the milk' author: 'Flavio'}
connection.query('INSERT INTO todos SET ?', todo, (error, results, fields) => {
if (error) {
console.error('An error occurred while executing the query')
throw error
}
})
如果表有一个 "自动增量" 的主键,其值将在 "results.insertId" 值中返回:
const todo = { thing: 'Buy the milk' author: 'Flavio'}
connection.query('INSERT INTO todos SET ?', todo, (error, results, fields) => {
if (error) {
console.error('An error occurred while executing the query')
throw error
}
}
const id = results.resultId
console.log(id))
关闭连接
当你需要终止与数据库的连接时,你可以调用 end() 方法:
connection.end()
这可以确保任何未决的查询被发送,并且连接被优雅地终止。
开发环境和生产环境之间的区别
你可以为生产和开发环境进行不同的配置。
Node.js假定它总是在开发环境中运行。你可以通过设置 NODE_ENV=production 环境变量向 Node.js 发出信号,表明你正在生产环境中运行。
这通常是通过执行以下命令来完成的:
export NODE_ENV=production
在 Shell 中,但最好把它放在你的 Shell 配置文件中(比如 Bash shell 的 .bash_profile ),因为否则在系统重启的情况下,这个设置会失效。
你也可以通过在你的应用程序初始化命令前加上环境变量来应用它:
NODE_ENV=production node app.js
这个环境变量是一个惯例,在外部库中也被广泛使用。
将环境设置为 production 通常可以确保以下:
- 日志记录保持在最小的、必要的水平上
- 更多的缓存级别,以优化性能
例如 Pug,Express 使用的模板库,如果 NODE_ENV 没有设置为 production,则在开发(development)模式下进行编译。在开发模式下,Express 视图在每个请求中都被编译,而在生产(production)模式下,它们被缓存起来。还有很多例子。
Express 提供了特定于环境的配置钩子,这些钩子根据NODE_ENV变量值自动调用:
app.configure('development', () => {})//...
app.configure('production', () => {})//...
app.configure('production', 'staging', () => {})//...
例如,你可以用它来为不同的模式设置不同的错误处理程序:
app.configure('development', () => {
app.use(express.errorHandler({ dumpExceptions: true, showStack: true }));
})
app.configure('production', () => {
app.use(express.errorHandler())
})
结语
我希望对 Node.js 的介绍,能帮助你开始使用它,或者帮助你掌握它的一些概念。希望你现在知道的足够多,可以开始创造一些好东西!