


原文: How to Create an AI Tweet Generator Using LangChain
今天我给大家带来了一个有趣的教程。如果你读过我上一篇关于使用 LangChain 构建自定义知识聊天机器人的文章,那么你一定对自己可以创建的伟大项目充满了想法。
好的,我想鼓励你的创造力,并举例说明使用 LangChain 和大型语言模型(LLM)可以创建什么。虽然听起来有点吓人,但实际上实现起来非常简单。
今天,我们将使用 LangChain 和 OpenAI 的 LLM 创建一个 AI Tweet 生成器。这是一个简单的项目,它接收一个 Tweet 主题并输出相关的 Tweet。
这有什么特别的?有趣的是,我们将使用 LangChain 通过维基百科上的最新信息。这让我们克服了 ChatGPT 的训练数据限制,因为它只能在 2021 年之前的数据上进行训练。
这就是我们要做的:
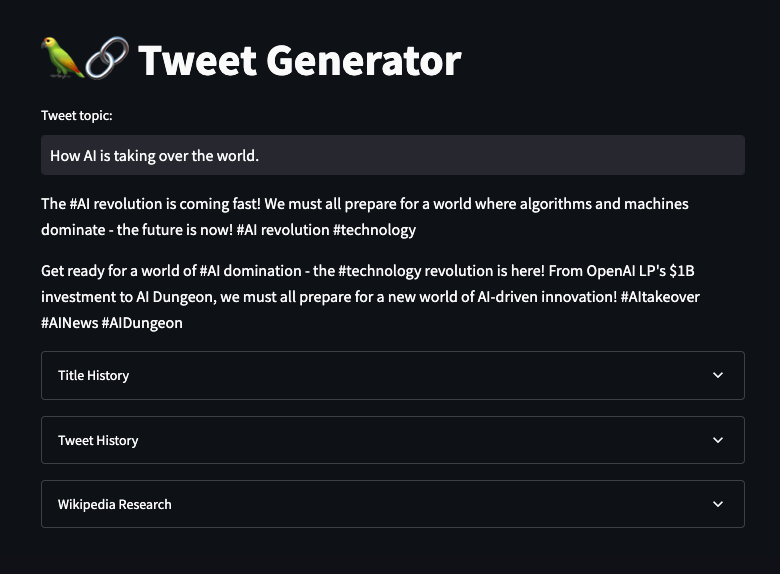
请看下面我们的推特所引用的信息。它使用了维基百科关于微软在 2023 年对 OpenAI 进行投资的信息。因此,现在你不必担心你的人工智能所引用的数据会过时了。

如果你觉得听起来不错,那我们就开始吧。
如何设置项目
虽然这个项目需要多个组件,但实际上所有内容都可以很好地整合到一个 app.py 文件中,该文件只需将多个 API 整合在一起即可。
在结构上,我们只需创建 app.py 文件和 apikey.py 文件来存储 API key(主要用于 OpenAI)。
此外,我们还要安装的库。以下是我们将在本项目中使用的库列表:
- Streamlit – Used to build the app(用于构建应用程序)
- LangChain – Used to build LLM workflow(用于建立 LLM 工作流程)
- OpenAI – For using OpenAI GPT(调用 OpenAI GPT 接口)
- Wikipedia – Used to connect GPT to WIKIPEDIA(用于连接 GPT 和 WIKIPEDIA)
- ChromaDB – Vector storage(向量存储))
- Tiktoken – Backend tokenizer for OpenAI(OpenAI 的后台令牌生成器)
要安装这些软件,请在终端运行以下命令:
pip install streamlit langchain openai wikipedia chromadb tiktoken
如果你的系统已经包含其中一些服务,则可以逐一安装。此外,我们还将为该环境配置 API Key 变量。将这些内容导入 app.py 文件后,我们就可以开始了。
import os
from apikey import apikey
import streamlit as st
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain, SequentialChain
from langchain.memory import ConversationBufferMemory
from langchain.utilities import WikipediaAPIWrapper
os.environ['OPENAI_API_KEY'] = apikey
如何实现用户界面
现在,我们要创建的应用程序相当简单。因此,我决定尽可能简化用户界面,只使用一个标题和文本输入框。对于这个 Tweet 生成器来说,这已经达到了目的。
# Creating the title and input field
st.title('🦜🔗 Tweet Generator')
prompt = st.text_input('Tweet topic: ')
稍后,我们将添加功能来显示我们的话题历史、推特历史,以及最重要的,我们引用的维基百科数据。现在,这就是我们要使用的用户界面:
如何包含提示模板
现在,我们将进入 LangChain 领域。在这一点上,如果你对 LangChain 不熟悉,也没有阅读过我关于 LangChain 的 上一篇文章,我强烈建议你阅读一下,以便更好地了解接下来的步骤。
我们要做的第一件事就是介绍 PromptTemplates。概括地说,PromptTemplates 是提示语的封装器,可以通过多种操作将它们串联起来,这也是 LangChain 的基础。
此外,我们还将为维基百科应用程序接口(Wikipedia API)提供一个封装,以便在链式执行中包含数据。
# template for the title
title_template = PromptTemplate(
input_variables = ['topic'],
template='write me a tweet about {topic}'
)
# template for the tweet
tweet_template = PromptTemplate(
input_variables = ['title', 'wikipedia_research'],
template='write me a tweet on this title TITLE: {title} while leveraging this wikipedia reserch:{wikipedia_research} '
)
# wrapper for Wikipedia data
wiki = WikipediaAPIWrapper()
在这个例子中,我还创建了一个 标题提示(title prompt),为我们的推文主题提供一个总标题。至于实际的提示,如果你一直在使用 ChatGPT,它的概念基本相同,只是现在我们引入了变量(推特话题)。
这样我们就可以避免每次输入时都输入 给我写一条关于...的推文。相反,我们只需插入话题即可。说完这些,让我们开始介绍实际的 OpenAI LLM。
Introducing OpenAI's LLMs
有几种方法可以做到这一点,你可以选择自己认为合适的模式。在上一篇文章中,我使用了 GPT-3.5-turbo chat model,代码如下:
chat = ChatOpenAI(model_name="gpt-3.5-turbo",temperature=0.3)
messages = [
SystemMessage(content="You are an expert data scientist"),
HumanMessage(content="Write a Python script that trains a neural network on simulated data ")
]
不过,你可以根据自己的 API 密钥决定使用哪个模块,然后按照 LangChain 文档 进行设置即可。
今天,我们将使用 "text-davinci-003 "模型,它与 ChatGPT 早期的 GPT-3 模型基本相同。

上图是 OpenAI 的各种模型(见其网站)。
你可以随意尝试使用这些模型,看看哪种推文能产生最好的结果。你甚至可以尝试功能更强大(也更昂贵)的 GPT-4,但对于像推文生成器这样简单的提示完成案例,可能就没有必要了。
llm = OpenAI(model_name="text-davinci-003", temperature=0.9)
title_chain = LLMChain(llm=llm, prompt=title_template, verbose=True, output_key='title', memory=title_memory)
script_chain = LLMChain(llm=llm, prompt=script_template, verbose=True, output_key='script', memory=script_memory)
我还决定将 temperature 设定为 0.9,以便让模型发表更有创意的推文。temperature 可以衡量模型回复的随机性和创造性,0 代表简单明了,1 代表随机性极强。如果你希望你的回应更符合事实和确定性,只需调低 temperature 即可。
temperature 将是我们进行这项工作所需的唯一变量。如果你想了解其他字段,请花些时间阅读文档,了解它们的含义。
例如,我们可以指定令牌限制(token limits),以确保不会得到冗长的响应,但使用我们当前的 tweet 提示模板应该不成问题。
如何跟踪你的 Tweet 生成历史
这是一个可选部分,但可为应用程序提供额外功能。如果你想跟踪应用程序活动的历史记录,包括以前的标题或推文等信息,则只需包含以下步骤即可:
# Memory
title_memory = ConversationBufferMemory(input_key='topic', memory_key='chat_history')
script_memory = ConversationBufferMemory(input_key='title', memory_key='chat_history')
在上面的代码中,我们创建了两个不同的内存变量:title_memory 和 script_memory。title_memory 保存推文主题的历史记录,script_memory 保存推文的历史记录。
ConversationBufferMemory 是 LangChain 的一项功能,它允许你跟踪迄今为止的输入和输出(在本例中,这只是我们之前生成的话题和推文)。
如何将组件串联起来
现在,我们已经对应用程序的所有组件(用户界面、提示模板和维基百科封装器)进行了分类,可以将它们组合在一起执行了。这正是 LangChain 的价值所在。
标准程序中的 复合函数(composite functions)就是一个很好的类比。只不过,这里的函数是 PromptTemplates、LLMs 和 Wikipedia 数据。使用之前的封装器,我们只需决定执行顺序(就像一个链条),就能获得我们想要的输出。
在本例中,首先从我们的主题中获取标题,然后使用维基百科对该主题的相关研究创建 Tweet,最后使用 Streamlit 显示这些内容。
if prompt:
title = title_chain.run(prompt) # Running the title prompt
wiki_research = wiki.run(prompt) # Performing wikipedia research
script = script_chain.run(title=title, wikipedia_research=wiki_research) # Creating the tweet
st.write(title) # Show the topic/title of the tweet
st.write(script) # Show the generated tweet
with st.expander('Title History'):
st.info(title_memory.buffer) # Storing the topic of the tweet to the history
with st.expander('Tweet History'):
st.info(script_memory.buffer) # Storing the tweet to the history
with st.expander('Wikipedia Research'):
st.info(wiki_research) # Storing the Wikipedia Research on the topic to the history
当我们运行 这些链(those chain)时,基本上是从用户界面获取话题,然后将其插入到与 LLM 相连的 PromptTemplate 中。推文 PromptTemplate 也会从维基百科中获取数据,并输入到 LLM 中。
最后,是时候检查我们的应用程序了。使用以下命令运行它:
streamlit run app.py
最终代码和下一步行动
其结果是能够克服 ChatGPT 过时的信息限制,并创建相关推文。如果你觉得难以理解,下面是我们目前掌握的情况:
# Importing necessary packages, files and services
import os
from apikey import apikey
import streamlit as st
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain, SequentialChain
from langchain.memory import ConversationBufferMemory
from langchain.utilities import WikipediaAPIWrapper
os.environ['OPENAI_API_KEY'] = apikey
# App UI framework
st.title('🦜🔗 Tweet Generator')
prompt = st.text_input('Tweet topic: ')
# Prompt templates
title_template = PromptTemplate(
input_variables = ['topic'],
template='write me a tweet about {topic}'
)
tweet_template = PromptTemplate(
input_variables = ['title', 'wikipedia_research'],
template='write me a tweet on this title TITLE: {title} while leveraging this wikipedia reserch:{wikipedia_research} '
)
# Wikipedia data
wiki = WikipediaAPIWrapper()
# Memory
title_memory = ConversationBufferMemory(input_key='topic', memory_key='chat_history')
tweet_memory = ConversationBufferMemory(input_key='title', memory_key='chat_history')
# Llms
llm = OpenAI(model_name="text-davinci-003", temperature=0.9)
title_chain = LLMChain(llm=llm, prompt=title_template, verbose=True, output_key='title', memory=title_memory)
tweet_chain = LLMChain(llm=llm, prompt=tweet_template, verbose=True, output_key='script', memory=tweet_memory)
# Chaining the components and displaying outputs
if prompt:
title = title_chain.run(prompt)
wiki_research = wiki.run(prompt)
tweet = tweet_chain.run(title=title, wikipedia_research=wiki_research)
st.write(title)
st.write(tweet)
with st.expander('Title History'):
st.info(title_memory.buffer)
with st.expander('Tweet History'):
st.info(tweet_memory.buffer)
with st.expander('Wikipedia Research'):
st.info(wiki_research)
当然,Tweet 生成器只是 LangChain 和 LLMs 的一个简单示例。例如,你还可以应用相同的流程创建 YouTube 脚本生成器或社交媒体内容日历助手,无限可能。
总结
希望你喜欢这个有趣的教程!LangChain 最近非常流行,这是有原因的--它的用途非常广泛。我强烈推荐你去看看。
如果你喜欢这篇文章,并想了解更多关于人工智能创造者正在开发的新工具的信息,你可以通过我的字节大小的人工智能通讯了解最新信息。这里有大量关于人工智能领域的精彩故事,我希望你能加入我们的社区。
我也会定期在 Linkedin 上发帖,我很乐意与你联系!除此之外,祝大家享受创建项目的过程,我很期待看到你们分享的项目。